







循环嵌套连接:行源1的每一条记录,依次去匹配行源2的每条记录,将符合连接条件的记录放在结果集中,直到行源1的所有记录都完成这个操作。循环嵌套连接是最基本也是最古老的表连接方式。

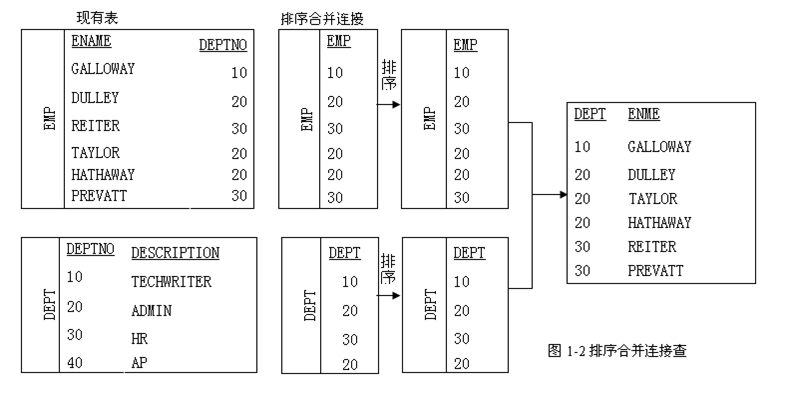
排序合并连接:行源1和行源2的数据分别排序,然后将两个排序的源表合并,符合连接条件的记录放到结果集中。由于排序需要内存空间,sort merge join对内存有比较大的消耗,如果内存空间(8i为sort_area_size,9i及以上使用PGA)不足,则会使用临时表空间,这样会降低排序合并连接的效率。排序合并连接是最古老的表连接方式之一。
附上tom哥哥的解释:
You Asked
Tom,
What is the difference between "Sort Merge" and "Hash" Joins. Don't they both do a one
FULL scan each on the joining tables and join them?
I know Sort Merge is used in the case of "ALL ROWS" and Nested Loops in the case of
"FIRST ROWS" hints. How about Has Join? When is it used?
Would really appreciate if you could explain it with a couple of examples.
Thanks in advance.
and we said...
Well, a sort merge of A and B is sort of like this:
read A and sort by join key to temp_a
read B and sort by join key to temp_b
read a record from temp_a
read a record from temp_b
while NOT eof on temp_a and temp_b
loop
if ( temp_a.key = temp_b.key ) then output joined record
elsif ( temp_a.key <= temp_b.key ) read a record from temp_a
elsif ( temp_a.key >= temp_b.key ) read a record from temp_b )
end loop
(its more complex then that, the above logic assumed the join key was unique -- we really
need to join every match in temp_a to every match in temp_b but you get the picture)
The hash join is conceptually like:
create a hash table on one of A or B (say A) on the join key creating temp_a.
while NOT eof on B
read a record in b
hash the join key and look up into temp_a by that hash key for matching
records
output the matches
end loop
So, a hash join can sometimes be much more efficient (one hash, not two sorts)
Hash joins are used any time a sort merge might be used in most cases. If you don't see
hash joins going on, perhaps you have hash_join_enabled turned off...
哈希连接:将行源1计算成一张基于连接键的hash表,行源2的每条记录依次扫描这张hash表,找到匹配的记录放到结果集。计算hash表需要内存空间,hash join同样对于内存有比较大的消耗,如果内存空间(8i为hash_area_size,9i及以上使用PGA)不足,则会使用临时表空间,这样会降低哈希连接的效率。
















 2141
2141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









