







如果下面文档格式错乱,请参见https://www.iteblog.com/archives/1899.html,或点击下面阅读原文 进行阅读
MMLSpark为Apache Spark提供了大量深度学习和数据科学工具,包括将Spark Machine Learning管道与Microsoft Cognitive Toolkit(CNTK)和OpenCV进行无缝集成,使您能够快速创建功能强大,高度可扩展的大型图像和文本数据集分析预测模型。
MMLSpark需要Scala 2.11,Spark 2.1+,以及Python 2.7或Python 3.5+。
显着特点
-
从 HDFS 轻松摄取图像到Spark DataFrame(示例:301)
-
使用 OpenCV 进行转换的预处理图像数据(示例:302)
-
使用 CNTK 进行预训练的深层神经网络(示例:301)
-
使用来自 Keras 预先训练的双向LSTM进行医疗实体提取(示例:304)
-
在Azure上的N系列GPU虚拟机上训练基于DNN的图像分类模型
-
通过单个变换器在SparkML中的基元上方使用方便的API实现自由格式的文本数据(示例:201)
-
列车分类和回归模型容易通过数据的隐式特征化(示例:101)
-
计算一组丰富的评估指标,包括每个实例的指标(示例:102)
所有的示例可以参见:https://github.com/Azure/mmlspark/tree/master/notebooks/samples
一个简单的示例
以下是使用预先训练的CNN在CIFAR-10数据集中分类图像的简单示例的摘录。完整的代码参见:https://github.com/Azure/mmlspark/blob/master/notebooks/samples/301%20-%20CIFAR10%20CNTK%20CNN%20Evaluation.ipynb
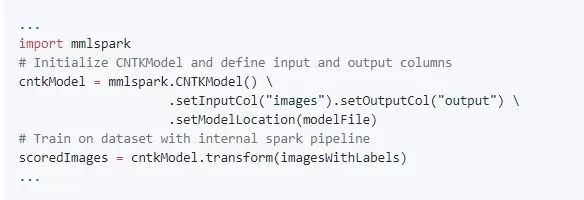
安装
Docker
使用MMLSpark 的最简单方法是通过预先编译好的Docker container,为了使用它,你先要运行下面的命令:
docker run -it -p 8888:8888 -e ACCEPT_EULA=yes microsoft/mmlspark
然后通过浏览器访问http://localhost:8888,这里我们可以运行简单的示例代码,更详细的使用请参见官方文档:https://github.com/Azure/mmlspark/blob/master/docs/docker.md
Spark package
当然,除了在Docker container里面使用MMLSpark 之外,我们还可以直接通过--packages 选项直接在现有的Spark集群中使用MMLSpark,具体如下:
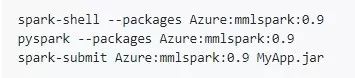
更多关于MMLSpark的使用和介绍,请参见官方文档。
死板、呆萌、宅、不解人意…作为一名敲代码为生的程序员,你是不是被旁人贴过太多不属于你的标签?
1024程序员节这天,100offer给你一个撕掉标签的机会:关注100offer微信号,发送一段话/一张图/一段视频/一条语音…展示你除了敲代码以外的神技能,还有最高价值1024元的“程序员兴趣基金”等你拿!















 83
83











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









