






关注 iteblog_hadoop 公众号并在本文末评论区留言(认真写评论,增加上榜的机会)。留言点赞数排名前6名的粉丝,各免费赠送一本《从零开始学Hadoop大数据分析》,活动截止至4月17日18:00。
本书针对愿意加入大数据行业的初学者量身定做,以简练风趣的语言介绍了大数据程核心技术及相关案例。内容包括了数据的基本概念、Hadoop的安装与配置、HDFS、基于Hadoop3的HDFS高可用、Zookeeper、MapReduce、YARN、Sqoop、KafKa、Redis,每个知识点配有可运行的案例,同时结合企业实际案例,让读者能够掌握从大数据环境搭建到大数据核心技术,并且进一步熟悉企业案例的分析及开发过程,从而轻松进入到大数据领域。本书实用性强,非常适合Hadoop大数据分析入门读者阅读,也适合相关院校作为大数据分析与挖掘的教材使用。

作者:温春水,毕洁馨
定价:89.00元
部分内容摘取
基于电商产品的大数据业务分析系统案例
项目背景、实现目标和项目需求
随着互联网快速的发展,越来越多行业都在尝试从网站挖掘来访客户的潜在价值,比如用户在打开网页后浏览了哪个页面,进行了什么样的操作,哪些用户来自于山东,哪些用户来自于北京,哪些用户购买了哪些商品,哪些商品容易销售等等,进而挖掘客户的潜在需求,比如当客户多次浏览了A商品,则说明客户对A类商品有购买意愿,如果有大批用户来自山东,则说明山东具有巨大的市场潜力。
说到这里,不得不提到天猫“双11”,据报道,2017天猫“双11”交易额超过去年的1207亿元人民币,再次创下新纪录,其实,不仅是天猫,很多电商后台都后有日志收集和分析系统,会记录用户浏览页面的相关操作和购买行为,并在后台以日志形式存在,比如用户的搜索、收藏、加入购物车、购买、评论等都对商家有着很大的参考价值。比如,用户通过各类浏览器访问网站最后会保存在磁盘上的logs目录下,如图1所示。
 图1 用户通过各类浏览器访问网站保存在磁盘上的logs中
图1 用户通过各类浏览器访问网站保存在磁盘上的logs中
首先我们从电商的参与者进行着手,这样便于通过不同的维度进行分析,我们知道电商的参与者,主要包括买方、卖方和快递三大类。接着可以对不同的用户群体进行不同维度的分析,包括基于买家的分析,基于商品的分析,以及买家购买了商品的分析,比如买家的消费额度等。
功能与流程
在这个案例中,我们从数据采集,数据存储,数据处理,数据可视化四部分组成,如图2所示。
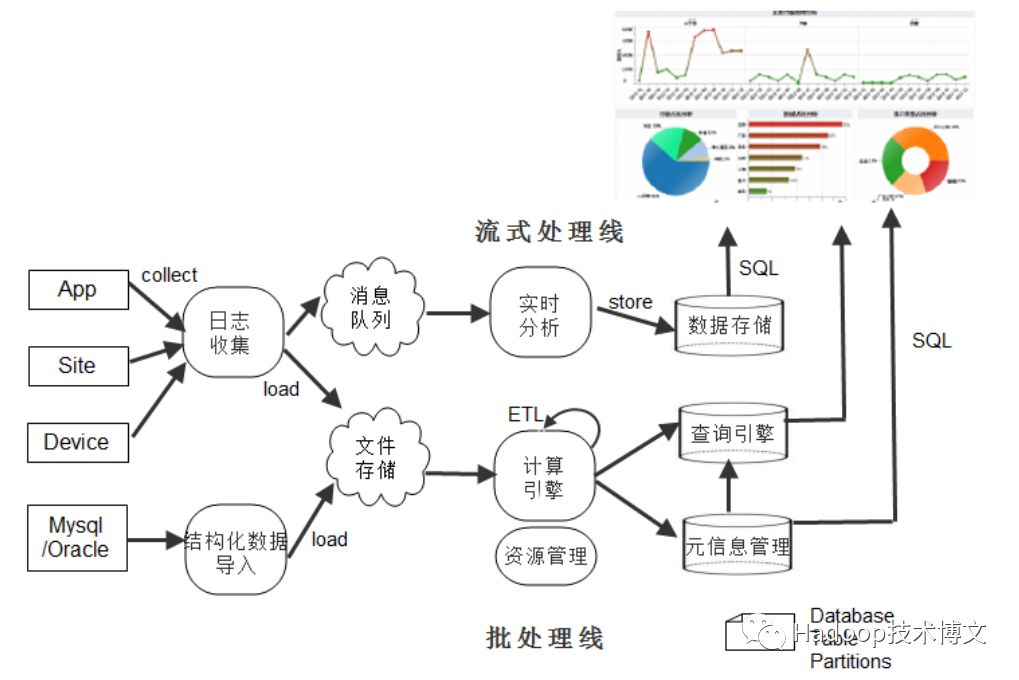
图2 大数据处理流程
开发大数据项目的第一往往是采集原始数据,在这个项目中,原始数据包括3部分,分别是用户信息、商品信息、购买记录。
l 用户信息包括:用户ID,性别、年龄(出生年月)和所在地。
l 商品信息包括:商家ID、类别、以及商品的商家。
l 购买记录包括:订单号、用户ID、商品ID、交易时间、价格、发货城市、收货城市、来源网站、快递单号、快递公司。
这里强调一点,读者需要和传统的关系型数据库区分开,这些信息初始是以log的形式生成,并以文本的样式存在磁盘上,比如电商后台会把你登录时的IP写在磁盘上的log文件中。其中用户数据和商品数据量相对较少,而交易记录往往非常大,大型的商务网站需要将数据存放在大数据平台HDFS上,在后面会逐步讨论。原始数据的关系如图3所示。
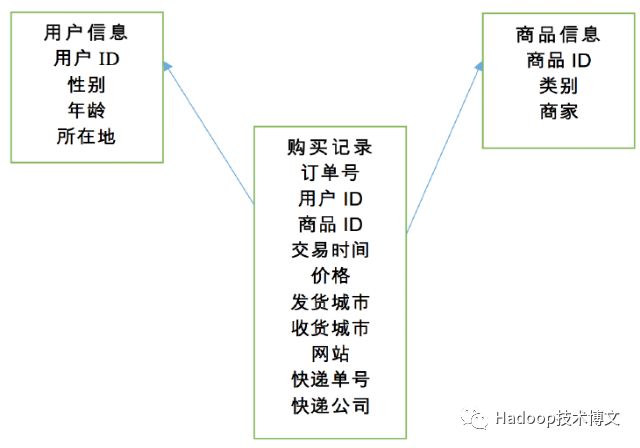
图3 原始数据关系图
数据收集
上面说到,原始数据通需要通过数据采集来完成,而数据采集通常分为两种方式,第一种方式是从手机App、网站、其他设备通过日志收集工具进行收集,这里的日志收集工具可以使用Flume。第二种方式是从现有的系统进行收集,比如MySQL/Oracle导入,导入的工具可以使用Sqoop。
针对与本项目来说,下一步就需要进行数据进行收集了,前面也提到购买记录由于数据量庞大,需要放到大数据存储平台HDFS上进行存储,将数据从本地传到HDFS上的工具可以用Flume,下面我们只讨论在该项目中如何使用flume。
1. Flume的配置文件
首先,flume存放在:/opt/software/flume/apache-flume-1.8.0-bin路径下,需要flume的conf文件夹下创建配置文件logAnalysis.properties来进行flume相关配置,配置文件内容如下:
#Source从Client收集数据,传递给Channel,这里source的名字是logSource
mylogAgent.sources = logSource
# Channel连接 sources 和 sinks ,Channel可以理解为一个队列,在这里Channel的名#字设置为fileChannel
mylogAgent.channels = fileChannel
# Sink从Channel收集数据,这里的名字是hdfsSink,将从Channel收集过来的数据,#最终放到HDFS上
mylogAgent.sinks = hdfsSink
#将source的属性定义为exec,使用exec的时候需要指定shell命令来对日志进行读取。
mylogAgent.sources.logSource.type = spooldir
mylogAgent.sources.logSource.spoolDir = /opt/data/loganalysis/records/
#将fileChannel绑到source上
mylogAgent.sources.logSource.channels = fileChannel
#定义sink的类型为
mylogAgent.sinks.hdfsSink.type = hdfs
#将收集到的数据放在hdfs上按照特定的格式进行显示
mylogAgent.sinks.hdfsSink.hdfs.path = hdfs:// master:9000/flume/record/%Y-%m-%d/%H%M
# 设置hdfs文件的前缀。默认是:FlumeData,这里设置前缀为record_log
mylogAgent.sinks.hdfsSink.hdfs.filePrefix=transaction_log
#产生新文件的间隔,默认是:30(秒) ,0表示不以时间间隔为准
mylogAgent.sinks.hdfsSink.hdfs.rollInterval= 120
#event达到特定大小时再产生一个新文件,默认是:10,0表示不以event数目为准
mylogAgent.sinks.hdfsSink.hdfs.rollCount= 1000
#文件到达特定大小时重新产生一个新文件,默认是:1024bytes,0表示不以文件大小为准。
mylogAgent.sinks.hdfsSink.hdfs.rollSize= 0
#类似于“四舍五入”,下面3行代码的意思是,每10分钟生成一个文件
mylogAgent.sinks.hdfsSink.hdfs.round = true
mylogAgent.sinks.hdfsSink.hdfs.roundValue = 10
mylogAgent.sinks.hdfsSink.hdfs.roundUnit = minute
# hdfs.fileType用于控制文件类型,这里设置为DataStream
mylogAgent.sinks.hdfsSink.hdfs.fileType = DataStream
mylogAgent.sinks.hdfsSink.hdfs.useLocalTimeStamp = true
#将fileChannel 绑定到sink上
mylogAgent.sinks.hdfsSink.channel = fileChannel
# Each channel's type is defined.
#FileChannel的类型设置为file
mylogAgent.channels.fileChannel.type = file
# 存放检查点目录,checkpointDir是一个目录
mylogAgent.channels.fileChannel.checkpointDir= /opt/software/flume/apache-flume-1.8.0-bin/dataCheckpointDir
#存放数据的目录
mylogAgent.channels.fileChannel.dataDirs= /opt/software/flume/apache-flume-1.8.0-bin /dataDir
2. 启动flume
flume配置文件创建完后,我们就可以启动flume了,根据上面的配置,flume启动完成后会检测/opt/data/loganalysis/records/文件夹,并把其中的文件传传到HDFS上。传到HDFS的主要原因是因为HDFS是分布式文件系统,在HDFS上可以存放大量的数据,所以不需要担心数据量过大无法存储的问题。下面是flume启动命令是:
./flume-ng agent --conf-file ../conf/flume-conf-logAnalysis.properties --name logAgent -Dflume.root.logger=INFO,console
其中,flume-ng agent代表启动flume代理,--conf-file指定配置文件为logAnalysis.properties, --name指定代理的名字是logAgent,-Dflume.root.logger是设置日志输出级别和显示方式。flume启动完成,可以在后台控制台看到以下信息:
18/04/27 09:34:00 INFO node.PollingPropertiesFileConfigurationProvider: Configuration provider starting
18/04/27 09:34:00 INFO node.PollingPropertiesFileConfigurationProvider: Reloading configuration file:../conf/flume-conf-logAnalysis.properties
18/04/27 09:34:00 INFO conf.FlumeConfiguration: Processing:hdfsSink
3. 查看采集后的文件
启动flume之后,就可以访问http://ip:50070,其中ip是namenode的地址。由于配置了监测/opt/data/loganalysis/records/文件夹,所以flume采集文件夹中的文件并放到HDFS上。关于hdfs上的存放路径配置是mylogAgent.sinks.hdfsSink.hdfs.path = hdfs:// master:9000/flume/record/%Y-%m-%d/%H%M ,其中master是namenode节点的机器名,9000是端口,由于存放路径是/%Y-%m-%的格式标识,所以,最终以年-月-日格式显示,如图4所示。
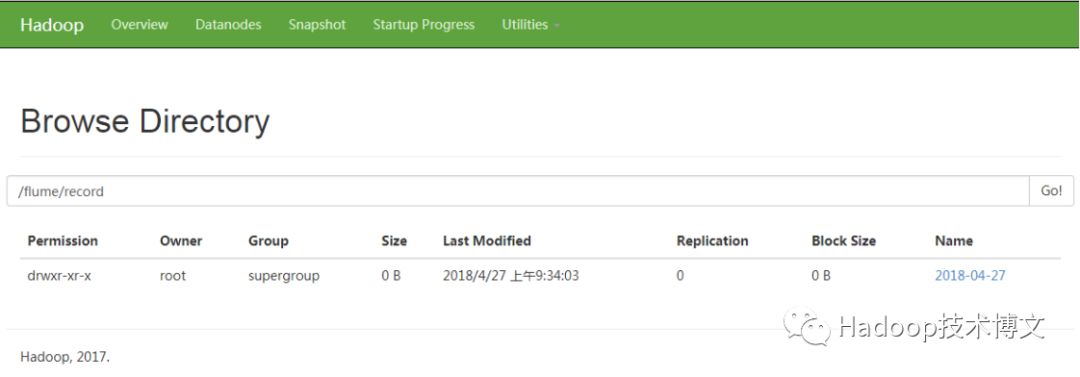 图4 基于浏览器查看hdfs上的文件
图4 基于浏览器查看hdfs上的文件
点开2018-04-27链接,可以看到以下信息,其中,0930对应%H%M,表示是9点30生成的文件,如图5所示。
图5 显示0930文件
继续点开1100,可以看到有个transaction_log.1524193717651文件。这就是flume存放在HDFS上的文件,在这里读者需要注意的是这个文件是存放在了集群上,而不是某台特定的电脑。
4. 通过后台命令查看文件
查看生成的文件,有2种方式,第一种是通过是通过浏览器查看,另外一种是通过后台HDFS命令查看:
hdfs dfs -ls /flume/record/2018-04-27/0930
其中“/flume/record/2018-04-27/0930”代表存放文件的路径。
当在后台执行查询命令时,可以列出相关文件,执行命令和结果如下所示:
[root@master records]# hdfs dfs -ls /flume/record/2018-04-27/0930
Found 5 items
-rw-r--r--1rootsupergroup11100282018-04-2709:34/flume/record/2018-04-27/0930/transaction_log.1524792841496
-rw-r--r--1rootsupergroup11102242018-04-2709:34/flume/record/2018-04-27/0930/transaction_log.1524792841497
-rw-r--r--1rootsupergroup11107752018-04-2709:34/flume/record/2018-04-27/0930/transaction_log.1524792841498
-rw-r--r--1rootsupergroup11110632018-04-2709:34/flume/record/2018-04-27/0930/transaction_log.1524792841499
-rw-r--r--1rootsupergroup111882018-04-2709:34/flume/record/2018-04-27/0930/transaction_log.1524792841500.tmp
扩展名是.tmp代表还没有生成完毕的临时文件
5. 查看文件内容
上面我们通过2种方式查看到了HDFS上的文件,接着我们可以查看文件的内容,相关命令是hdfs dfs -cat ,比如想要查看:
/flume/record/2018-04-27/0930/transaction_log.1524792841496文件,可以执行以下命令。
hdfs dfs -cat /flume/record/2018-04-27/0930/transaction_log.1524792841496 |tail -10
结果如下所示:
[root@masterrecords]#hdfsdfs-cat/flume/record/2018-04-27/0930/transaction_log.1524792841496|tail -10
0000009989,00000324,00000157,1494237443,344,ChongQing,BeiJing,JUHUASUAN,4189333890504,SHENTONG,12.153.117.42,fil
0000009990,00000256,00000077,1494237443,208,GuiZhou,GuiZhou,TIANMAO,4816864308189,YUANTONG,118.110.192.76,os
0000009991,00000331,00000295,1494237443,761,JiLin,TaiWan,TIANMAO,340787335790904,SHENTONG,208.109.80.9,uk
0000009992,00000340,00000427,1494237443,564,GuangDong,Aomen,TIANMAOCHAOSHI,30292252741340,YUNDA,87.248.43.49,ast
0000009993,00000092,00000422,1494237443,791,AnHui,JiangXi,JUHUASUAN,180094320378750,EMS,184.28.246.104,dv
0000009994,00000402,00000264,1494237443,848,HeNan,LiaoNing,JUHUASUAN,869985226241000,SHUNFENG,48.126.5.253,se
0000009995,00000497,00000561,1494237444,130,ShanXi3,SiChuan,TAOBAO,4259501077678107,ZHONGTONG,12.172.169.147,xh
0000009996,00000401,00000618,1494237444,443,JiangSu,ShanXi3,TIANMAO,210097518565199,YUNDA,241.98.145.191,mt
0000009997,00000166,00000895,1494237444,131,NingXia,JiangSu,JUHUASUAN,6011606123756890,YUNDA,241.226.176.91,ro
0000009998,00000553,00000061,1494237444,21,HeNan,SiChuan,JUHUASUAN,375999018058735,EMS,205.110.143.124,dz
由于数据量比较大,为了只显示一部分,我们在“|”之后加上了tail -10,其作用是显示最后10条。接着将用户信息user.list和商品信息brand.list上传到hdfs相应目录下。
6. 上传user.list文件
上传user.list文件,代码如下:
hdfs dfs -put user.list /flume/user
执行完成后,在浏览器中查看相应结果,如图6所示。
图6 浏览器中查看user.list文件
7. 上传brand.list目录
上传brand.list目录,代码如下:
hdfs dfs -put brand.list /flume/brand
如图7所示:
图7 浏览器查看brand.list文件
通常用户信息和商品信息是存放在关系型数据库中,在这里我们将这两类数据传到HDFS的目的是为了后续和交易数据整合分析。
简要回顾,目前我们已经完成了数据的收集,总体逻辑是通过flume将生成的log文件传到HDFS上,项目中log文件可以是各类数据比如用户操作行为,运行环境,访问ip等等,只要是想记录下来的信息,都可以放入log日志,除了进行数据分析,也方便后续的查询稽核。
数据预处理
前面我们将数据收集到了HDFS,下面就需要完成数据的清洗了,所谓数据清洗主要是要对各种脏数据(不符合要求)进行相应处理,一来是为了解决数据的质量问题,二是使数据更加便于做挖掘与分析,不同的目的清洗方式和规则也不一样。
包括但不局限于“数据完整性”、“数据唯一性”、“数据合法性”、“数据一致性”等。通过查看HDFS上的文件内容,我们发现某些数据需要进行处理,比如第四列的交易时间是从1970年到现在的秒数,而我们更习惯看到类似年-月-日的样式,比如2018-08-08 23:39。
0000044213,00000363,00000252,1494243770,41,GuangXi,YunNan,TIANMAOCHAOSHI,4631586785877033,ZHONGTONG,240.26.213.17,unm
下面就可以使用MapReduce来完成上述格式的转化,将类似1494243770的长整数样式换成2018-08-08 23:39年月日时分秒样式。在此创建MapReduce的核心类DateUtilMapper.java,代码如下所示:
DateUtilMapper.java
package com.mr.etl;
import java.io.IOException;
import java.text.SimpleDateFormat;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class DateUtilMapper extends Mapper<LongWritable, Text, Text, Text>{
protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
String[] words =value.toString().split(",");
String content = "";
for(int i = 0;i<words.length-2;i++){
//如果是第4列则进行数据处理
if(i==3){
//按照yyyy-MM-dd HH:mm:ss格式对数据处理
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
content = content+ sdf.format(Long.parseLong(words[3]+"000"))+"\t";
//对于不是第4列的数据,直接字符串连接
}else if(i==words.length-3){
content=content+words[i]+"";
}else{
//处理完后数据换行
content=content+words[i]+"\t";
}
}
context.write(new Text(content), new Text(""));
}
}
以上代码是数据处理的核心代码,其中最核心的逻辑是当遇到第4列时,则将呈现格式转化成类似2018-08-08 08:08的年月日时分秒,其他情况则直接将字符串连接。
与Mapper对应的是Reducer,以下是DateUtilReducer的核心代码。
DateUtilReducer.java
package com.mr.etl;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class DateUtilReducer extends Reducer<Text, Text, Text, Text>{
protected void reduce(Text arg0, Iterable<Text> arg1,
Context arg2)
throws IOException, InterruptedException {
arg2.write(arg0, new Text(""));
}
}
这里需要说明的是,由于核心代码在Mapper中已经处理完成,所以在Reducer中没有复杂的逻辑处理。
另外,Mapper和Reducer需要通过一个主函数进行调用,我们通过RunJob.java作为主函数来调用Mapper和Reducer,相关代码如下所示:
RunJob.java
package com.mr.etl;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class RunJob {
public static void main(String[] args) {
Configuration conf =new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
try {
FileSystem fs =FileSystem.get(conf);
Job job =Job.getInstance(conf,"wc");
job.setJarByClass(RunJob.class);
job.setMapperClass(DateUtilMapper.class);
job.setReducerClass(DateUtilReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path("/flume/record/2018-04-27/0930"));
Path output =new Path("/opt/logs/record_dimension/");
if(fs.exists(output)){
fs.delete(output, true);
}
FileOutputFormat.setOutputPath(job, output);
boolean f= job.waitForCompletion(true);
if(f){
System.out.println("job Complete");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
在以上的代码当中:
FileInputFormat.addInputPath(job,newPath("/flume/record/2018-04-27/0930"))的作用是设置了HDFS上的数据源。Path output =new Path("/opt/logs/record_dimension/")的作用是设置了数据处理完后文件的存放路径。
启动数据清洗程序,在Mapper、Reducer、RunJob主函数编写完毕后,就可以传到服务器并启动主函数完成数据的清洗了,调用命令如下:
hadoop jar dateutils.jar com.mr.etl.RunJob
通过运行以上命令,最终会在主函数中会调用Mapper和Reducer来完成数据的转化和清洗。主函数运行完后,会出现以下成功提示:
18/04/27 10:02:37 INFO mapreduce.Job: Counters: 35
File System Counters
FILE: Number of bytes read=194404854
FILE: Number of bytes written=213063644
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=20929407
HDFS: Number of bytes written=4577913
HDFS: Number of read operations=67
HDFS: Number of large read operations=0
HDFS: Number of write operations=14
Map-Reduce Framework
Map input records=44224
Map output records=44224
Map output bytes=4577982
Map output materialized bytes=4666460
Input split bytes=725
Combine input records=0
Combine output records=0
Reduce input groups=44223
Reduce shuffle bytes=4666460
Reduce input records=44224
Reduce output records=44223
Spilled Records=88448
Shuffled Maps =5
Failed Shuffles=0
Merged Map outputs=5
GC time elapsed (ms)=300
Total committed heap usage (bytes)=1670381568
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=4911177
File Output Format Counters
Bytes Written=4577913
job Complete
通常情况下,当读者看到job Complete时,则表示数据已经处理完成。如果我们想查看处理完后的相关文件,则可以在后台通过命令列出文件夹/opt/logs/record_dimension/下的文件了,执行命令和结果如下所示:
[root@master software]# hdfs dfs -ls /opt/logs/record_dimension/
Found 2 items
-rw-r--r-- 1 root supergroup 02018-04-2710:02/opt/logs/record_dimension/_SUCCESS
-rw-r--r-- 1 root supergroup45779132018-04-2710:02/opt/logs/record_dimension/part-r-00000
紧接着可以查看part-r-00000文件内容:
[root@master software]# hdfs dfs -cat /opt/logs/record_dimension/part-r-00000|tail -10
000004421300000363000002522017-05-08 19:42:5041GuangXiYunNanTIANMAOCHAOSHI4631586785877033 ZHONGTONG
000004421400000264000003372017-05-08 19:42:50974HeNanXiZangTAOBAO3112965475218387ZHONGTONG
000004421500000347000008352017-05-08 19:42:51458ZheJiangAnHuiJUHUASUAN869957068104422EMS
000004421600000189000006102017-05-08 19:42:51883XiangGangSiChuanJUHUASUAN180093303671603SHENTONG
000004421700000570000002172017-05-08 19:42:53409GuangXiZheJiangTIANMAOCHAOSHI30031673061320SHENTONG
000004421800000454000005412017-05-08 19:42:5395GanSuShanDongTIANMAOCHAOSHI3096474337270330YUANTONG
000004421900000453000000942017-05-08 19:42:53734ShanXi1ShanXi1JUHUASUAN180077602041071YUNDA
000004422000000043000003142017-05-08 19:42:53208ChongQingJiangXiJUHUASUAN5544770908298714SHENTONG
000004422100000200000004792017-05-08 19:42:53187ShanXi3ShangHaiJUHUASUAN869935332633749EMS
000004422200000116000009162017-05-08 19:42:53437NingXiaFuJian
从上面的结果中,我们可以看到第四列的数据已经变成了年-月-日样式,说明数据已经转化完成。
数据分析-创建外部表
到目前为止,我们已经将数据上传到了HDFS上,完成了数据收集、处理与清洗过程,那么下一步就可以进行数据分析了。在此,我们可以通过Hive对其进行分析,关于Hive的介绍与安装配置,请读者参考相应章节。
看过本书Hive章节的读者应该知道,Hive的HQL操作都是基于“表”的操作,所以为了通过Hive完成数据的分析,我们需要首先需要创建3张表,分别对应上面处理后的HDFS上的3个文件“userinfo”, ”brandinfo”, ” recordsinfo”。在此我们创建的是外部表,关于外部表和内部表的区别,读者可以查看相关章节。
创建user外部表外部表的相关语句如下:
create external table if not exists userinfo(
userid STRING,
username STRING,
gender STRING,
birthdate DATE,
province STRING
)ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
location 'hdfs://localhost:9000/flume/user/';
在hive中执行以上代码,提示“OK”字样,则代表创建成功。
hive> create external table if not exists userinfo(
> userid STRING,
> username STRING,
> gender STRING,
> birthdate DATE,
> province STRING
> )ROW FORMAT DELIMITED
> FIELDS TERMINATED BY ','
> location 'hdfs://localhost:9000/flume/user/';
OK
Time taken: 0.608 seconds
在以上创建表的代码中,localhost是namenode的本机地址;FIELDS TERMINATED BY ',',代表每个字段以逗号‘,’隔开;location 'hdfs://localhost:9000/flume/user/' 代表hdfs上面的数据位置,通过location的设置,最终会将表和文件user.list中的数据完成映射,由于之前我们将数据传到了/flume/user/下面,所以这里的location就指向了/flume/user/。
完成了表的创建也完成了表和文件的映射关系,接下来,我们就可以查看数据了,为了避免显示数据过多,在这里我们通过limit 10来限制显示条数为10条,执行命令及结果如下所示:
hive> select * from userinfo limit 10;
OK
00000000McdanielF1980-04-12BeiJing
00000001HarrellF1989-05-12HuNan
00000002RobinsonF1972-07-17JiangXi
00000003BlankenshipM2004-05-11SiChuan
00000004MilesM1975-09-20TaiWan
00000005HughesM1997-01-12SiChuan
00000006HaleF2001-01-27YunNan
00000007JacksonM1987-03-05XinJiang
00000008BrooksM1990-03-20SiChuan
00000009JohnstonF1985-02-19GuangXi
Time taken: 0.091 seconds, Fetched: 10 row(s)
为了完成后续的数据分析,单单有userinfo表是不够的,还需要再创建brandinfo表和recordsinfo表,为了确认表创建完成后和相应数据进行了关联,我们在创建完表后,均进行简单的查询来确保数据映射没有问题。
首先,创建外部表brandinfo:
create external table if not exists brandinfo (
brandid STRING,
category STRING,
brandname STRING
)ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
location 'hdfs://localhost:9000/flume/brand/';
表创建完成后,通过hive查看brandinfo中的数据:
hive> select * from brandinfo limit 10;
OK
00000000sportsPUMA
00000001clothesZARA
00000002foodNIULANSHAN
00000003televisionSAMSUNG
00000004computerSONY
00000005sportsANTA
00000006sportsKAPPA
00000007cosmeticMEIFUBAO
00000008sportsNB
00000009computerLENOVO
Time taken: 0.087 seconds, Fetched: 10 row(s)
接着,创建外部表recordsinfo:
create external table if not exists recordsinfo(
recordid STRING,
userid STRING,
brandid STRING,
trancation_date TIMESTAMP,
price INT,
from_province STRING,
to_province STRING,
website STRING,
express_number STRING,
express_company STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
location 'hdfs://localhost:9000/flume/record/2018-04-27/0930/';
表创建完成后,通过hive查看recordsinfo中的数据:
hive> select * from recordsinfo limit 10;
OK
00000442220000011600000916NULL437NingXiaFuJianTAOBAO86997NULL
00000000000000046800000030NULL347HaiNanLiaoNingTIANMAO869905775627268YUANTONG
00000000010000002600000448NULL339YunNanHeBeiTIANMAO675929469467SHENTONG
00000000020000054300000081NULL332SiChuanTaiWanTIANMAOCHAOSHI4010167066854172SHENTONG
00000000030000039700000217NULL669YunNanGuangXiTIANMAO342636875611434SHUNFENG
00000000040000054300000342NULL472HeBeiGuiZhouTAOBAO371933698610006SHUNFENG
00000000050000008800000177NULL834XiangGangNeiMengGuTAOBAO6011254950459740SHENTONG
00000000060000045100000486NULL309NeiMengGuShangHaiTAOBAO180032521959143EMS
00000000070000051500000926NULL758NeiMengGuHuNanTAOBAO4214464510259775ZHONGTONG
00000000080000040900000678NULL978ShanXi3AomenTAOBAO4174495333403156YUNDA
Time taken: 0.139 seconds, Fetched: 10 row(s)
目前为止,我们已经将3张Hive表创建完成,而且可以分别从3张表中查询数据,接下来就可以通过建立模型进行数据分析了。
建立模型
在建立模型之前,先要了解有哪些需求,我们现在主要有3个需求,分别是“查询各年龄段用户消费总额”,“ 查询各品牌销售总额”, “查询各省份消费总额”。
1、各年龄段用户消费总额
首先,读者需要考虑两个关键词,一是“年龄”,二是“总额”,我们知道“年龄”在userinfo表中,“总额”在recordsinfo表中,因此至少需要userinfo和recordsinfo表进行关联,以下是HQL语句:
select cast(DATEDIFF(CURRENT_DATE,birthdate)/365 as int) as age,sum(price) as totalprice from recordsinfo
join userinfo on recordsinfo.userid=userinfo.userid group by
cast(DATEDIFF(CURRENT_DATE,birthdate)/365 as int) order by totalPrice desc
其中,DATEDIFF函数是用于计算当前时间和birthdate字段的差别天数,cast是DATEDIFF得到的结果转化成int类型。
在Hive中执行以上命令。
hive> select cast(DATEDIFF(CURRENT_DATE,birthdate)/365 as int) as age,sum(price) as totalprice from recordsinfo
> join userinfo on recordsinfo.userid=userinfo.userid group by
> cast(DATEDIFF(CURRENT_DATE,birthdate)/365 as int) order by totalPrice desc
执行完毕后,会输出以下结果,上半部分是MapReduce执行的描述,后续是年龄和销量的统计,左边是年龄,右边是销量。
2018-04-27 10:10:35,983 Stage-3 map = 100%, reduce = 100%
Ended Job = job_local1359080733_0002
MapReduce Jobs Launched:
Stage-Stage-2: HDFS Read: 9950780 HDFS Write: 0 SUCCESS
Stage-Stage-3: HDFS Read: 9950780 HDFS Write: 0 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
39707080
13679280
1679279
41649885
44635443
24595125
14589813
16587366
9586603
…
2、查询各品牌销售总额
与第一个需求的分析逻辑类似,品牌在“brandinfo”表,“销售”在recordsinfo表,所以需要brandinfo和recordsinfo进行关联,相关查询各品牌销售额度的HQL如下所示。
select brandname,sum(price) as totalprice from recordsinfo join
brandinfo on recordsinfo.brandid=brandinfo.brandid group by
brandinfo.brandname order by totalPrice desc
在hive执行以上命令。
hive> select brandname,sum(price) as totalprice from recordsinfo join
> brandinfo on recordsinfo.brandid=brandinfo.brandid group by
> brandinfo.brandname order by totalPrice desc
执行结束后,出现“OK”字样,则代表成功,查询结果左列是品牌名,右侧是销量。
2018-04-27 10:14:16,509 Stage-3 map = 100%, reduce = 100%
Ended Job = job_local873791642_0004
MapReduce Jobs Launched:
Stage-Stage-2: HDFS Read: 19773134 HDFS Write: 0 SUCCESS
Stage-Stage-3: HDFS Read: 19773134 HDFS Write: 0 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
SAMSUNG742665
TCL657428
HLA599171
DELL566776
ASUS560944
SONY545402
APPLE520915
MOTOROLA474754
DHC472575
3、查询各省份消费总额
查询省份的逻辑和前两项是类似的,身份在userinfo表,消费在recordsinfo,所以将userinfo和recordsinfo进行关联,HQL如下所示。
select province,sum(price) as totalprice from recordsinfo
join userinfo on recordsinfo.userid=userinfo.userid
group by userinfo.province order by totalPrice desc
在Hive中执行以上命令。
hive> select province,sum(price) as totalprice from recordsinfo
> join userinfo on recordsinfo.userid=userinfo.userid
> group by userinfo.province order by totalPrice desc
得到相应结果,左边是省份,右边是消费额,并且消费额按照从高到底进行了排序。
2018-04-27 10:15:47,751 Stage-3 map = 100%, reduce = 100%
Ended Job = job_local1940751870_0006
MapReduce Jobs Launched:
Stage-Stage-2: HDFS Read: 29595488 HDFS Write: 0 SUCCESS
Stage-Stage-3: HDFS Read: 29595488 HDFS Write: 0 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
SiChuan1322949
TaiWan992801
NeiMengGu914987
QingHai846420
JiLin820037
HuNan767805
HeNan758084
XinJiang749827
TianJin735897
根据以上的分析和运行HQL,我们已经得到了查询结果,为了避免重复查询和完成后续的数据可视化,我们可以将查询结果插入一张临时表,并将临时表中的数据通过Sqoop导入到MySQL关系型数据库中。
4、使用Sqoop将数据导入到MySQL数据库
为了将数据存到MySQL中,我们需要3步走,对应每一个分析结果创建一张Hive内部表和MySQL表,最终将数据导入到MySQL中存储。步骤如下,第1步,在Hive中创建内部表;第2步,将分析结果插入到临时表;第3步,通过Sqoop将Hive内部表中的数据再导入到MySQL。在此我们只讨论“查询各省份消费总额”需求,另外2个是类似的,读者可以自行研究。
1.在hive上创建内部表,并通过location设置在HDFS上面的位置
Create table if not exists t_statisticsbyprovince (
province STRING,
totalspending float
)ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
location 'hdfs://localhost:9000/flume/result/province/';
上面建表语句中的location指向了hdfs://localhost:9000/flume/result/province/,所以最终插入进来的数据最终会存放到/flume/result/province /下面。
2.在mysql中创建一张对应的表,用来与hive中的表对应起来,最终便于通过Sqoop完成数据从Hive导入MySQL对应表
mysql> create table tbl_statisticsbyprovince(statisticsid int not null auto_increment, province varchar(20),totalspending float,primary key(statisticsid));
Query OK, 0 rows affected (0.01 sec)
3.将查询结果插入到hive内部表中
insert into t_statisticsbyprovince5
select province,sum(price) as totalSpending from recordsinfo
join userinfo on recordsinfo.userid=userinfo.userid
group by userinfo.province order by totalSpending desc
执行完后,就可以在t_statisticsbyprovince中的数据了。
hive> select * from t_statisticsbyprovince;
OK
SiChuan1322949.0
TaiWan992801.0
NeiMengGu914987.0
QingHai846420.0
JiLin820037.0
HuNan767805.0
HeNan758084.0
目前数据已经近了hive的内部表,接着我们可以使用Sqoop将数据导入到MySQL中。
4.通过Sqoop将hive数据导入到MySQL数据库中
sqoop export --connect jdbc:mysql://localhost:3306/loganlysis --username root --password root --table tbl_statisticsbyprovince4 --columns province,totalspending --export-dir hdfs://localhost:9000/flume/result/province/000000_0 -m 1
运行结果如下:
18/04/27 10:38:26 INFO mapreduce.Job: map 100% reduce 0%
18/04/27 10:38:26 INFO mapreduce.Job: Job job_local527674974_0001 completed successfully
18/04/27 10:38:26 INFO mapreduce.Job: Counters: 20
File System Counters
FILE: Number of bytes read=18029260
FILE: Number of bytes written=18531346
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=582
HDFS: Number of bytes written=0
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=0
Map-Reduce Framework
Map input records=34
Map output records=34
Input split bytes=133
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=0
Total committed heap usage (bytes)=150470656
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=0
18/04/27 10:38:26 INFO mapreduce.ExportJobBase: Transferred 582 bytes in 2.7284 seconds (213.3157 bytes/sec)
18/04/27 10:38:26 INFO mapreduce.ExportJobBase: Exported 34 records.
5.查看MySQL中数据
通过以下查询结果可以看出从Hive中的数据已经通过Sqoop导入到了MySQL中。
mysql> select * from tbl_statisticsbyprovince4;
+--------------+--------------+---------------+
| statisticsid | province | totalspending |
+--------------+--------------+---------------+
| 1 | SiChuan | 1322950 |
| 2 | TaiWan | 992801 |
| 3 | NeiMengGu | 914987 |
| 4 | QingHai | 846420 |
| 5 | JiLin | 820037 |
| 6 | HuNan | 767805 |
| 7 | HeNan | 758084 |
| 8 | XinJiang | 749827 |
数据可视化
按照大数据的整体流程,接下来就要完成数据可视化了,关于数据可视化可以使用echarts,网址是:http://echarts.baidu.com ,官网实例如下,如图8所示。
图8 官网实例
在官网中有很多案例,包括Line(线图)、Bar(柱状图)、Pie(饼状图)等常用的图形都包括了。
下面我们找到柱状图案例,如图9所示。
图.9 柱状图案例
我们只要改变左边的数据,右边的图形就会发生改变,如上例代码
option = {
xAxis: {
type: 'category',
data: ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun']
},
yAxis: {
type: 'value'
},
series: [{
data: [120, 200, 150, 80, 70, 110, 130],
type: 'bar'
}]
};
其中,xAxis代表是x轴,yAxis代表y轴只要我们修改xAxis中的data和yAxis中的data,需要两者数据对应起来,比如以上实例中Mon是120单位,Tue是200单位等等。
接着我们想把省份和销量通过柱状图呈现出来,过程非常简单,先把官方案例下载下来,我们下载bar-simple.html,bar-simple.html的内容动态修改成上述的查询结果后,bar-simple.html内容如下:
<!DOCTYPE html>
<html style="height: 100%">
<head>
<meta charset="utf-8">
</head>
<body style="height: 100%; margin: 0">
<div id="container" style="height: 100%"></div>
<script type="text/javascript"
src="http://echarts.baidu.com/gallery/vendors/echarts/echarts.min.js"></script>
<script type="text/javascript"
src="http://echarts.baidu.com/gallery/vendors/echarts-gl/echarts-gl.min.js"></script>
<script type="text/javascript"
src="http://echarts.baidu.com/gallery/vendors/echarts-stat/ecStat.min.js"></script>
<script type="text/javascript"
src="http://echarts.baidu.com/gallery/vendors/echarts/extension/dataTool.min.js"></script>
<script type="text/javascript"
src="http://echarts.baidu.com/gallery/vendors/echarts/map/js/china.js"></script>
<script type="text/javascript"
src="http://echarts.baidu.com/gallery/vendors/echarts/map/js/world.js"></script>
<script type="text/javascript"
src="http://api.map.baidu.com/api?v=2.0&ak=ZUONbpqGBsYGXNIYHicvbAbM"></script>
<script type="text/javascript"
src="http://echarts.baidu.com/gallery/vendors/echarts/extension/bmap.min.js"></script>
<script type="text/javascript"
src="http://echarts.baidu.com/gallery/vendors/simplex.js"></script>
<script type="text/javascript">
var dom = document.getElementById("container");
var myChart = echarts.init(dom);
var app = {};
option = null;
option = {
xAxis: {
type: 'category',
data: ['SiChuan', 'TaiWan', 'NeiMengGu', 'QingHai', 'JiLin', 'HuNan', 'HeNan']
},
yAxis: {
type: 'value'
},
series: [{
data: [1322950, 992801, 914987, 846420, 820037, 767805, 758084],
type: 'bar'
}]
};
;
if (option && typeof option === "object") {
myChart.setOption(option, true);
}
</script>
</body>
</html>
运行上述文件,可以直观看出每个省份的销售额度,如图10所示。
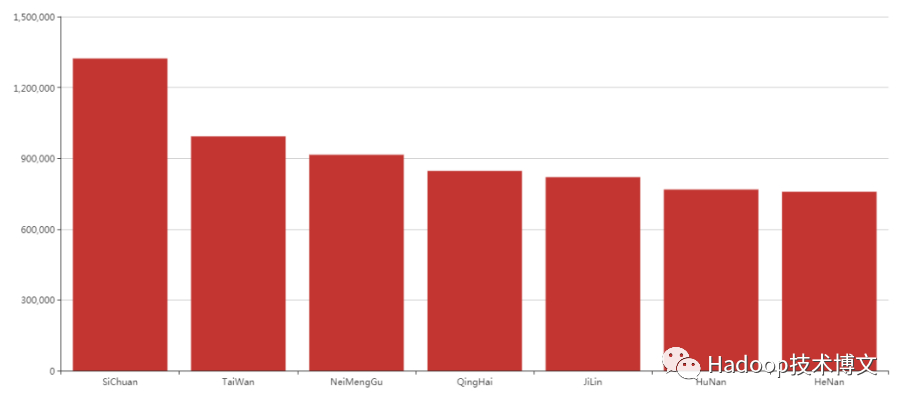
图10 每个省份的销售额度
以上是一个简化的过程,实际工作中可以和前后端技术整合起来,此处不做赘述。
本文章摘自--《从零开始学Hadoop大数据分析》一文中,点击阅读原文京东购买
赠书福利
【1】关注本公众号(Hadoop技术博文,ID:iteblog_hadoop),并在评论区留言获点赞数最高前6名将赠送《从零开始学Hadoop大数据分析》1本,共送出6本;
【2】活动时间:即日起至4月17日18:00点;
【3】活动结束后,收到中奖通知的用户请在公众号私信:微信号 + 姓名 + 地址+ 电话 + 邮编;
【4】本活动解释权归Hadoop技术博文所有。














 358
358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









