







11 Important Database Designing Rules
Rule 1:- What is the Nature of the application(OLTP or OLAP)?
Rule 2:- Break your data in to logical pieces, make life simpler
Rule 3:- Do not get overdosed with rule 2
Rule 4:- Treat duplicate non-uniform data as your biggest enemy
Rule 5:- Watch for data separated by separators.
Rule 6:- Watch for partial dependencies.
Rule 7:- Choose derived columns preciously
Rule 8:- Do not be hard on avoidingredundancy, if performance is the key
Rule 9:- Multidimensional data is a different beast altogether
Rule 10:- Centralize name value table design
Rule 11:- For unlimited hierarchical data self-reference PK and FK

Courtesy: - Image from Motion pictures
Before you start reading this article let me confirm that I am not a guru in database designing. The below 11 points which are listed are points which I have learnt via projects, my own experiences and my own reading. I personally think it has helped me a lot when it comes to DB designing. Any criticism welcome.
The reason why I am writing a full blown article is, when developers sit for designing a database they tend to follow the three normal forms like a silver bullet. They tend to think normalization is the only way of designing. Due this mind set they sometimes hit road blocks as the project moves ahead.
In case you are new to normalization, then click and see3 normal forms in action which explains all three normal forms step by step.
Said and done normalization rules are important guidelines but taking them as a mark on stone is calling for troubles. Below are my own 11 rules which I remember on the top head while doing DB design.
Rule 1:- What is the Nature of the application(OLTP or OLAP)?
When you start your database design the first thing to analyze is what is the natureof theapplication you are designing for, is it Transactional or Analytical. You will find many developers by default applying normalization rules without thinking about the nature of the application and then later getting in to performance and customization issues. As said there are 2 kinds of applications transaction based and analytical based,let's understand what these types are.
Transactional: - In this kind of application your end user is more interested in CRUD i.e. Creating, reading, updating and deleting records. The official name for such kind of database is called as OLTP.
Analytical: -In these kinds of applications your end user is more interested in Analysis, reporting, forecasting etc. These kinds of databases have less number of inserts and updates. The main intention here is to fetch and analyze data as fast as possible. The official name for such kind of databases is OLAP.

So in other words if you think insert, updates and deletes are more prominent then go for normalized table design or else create a flat denormalized database structure.
Below is a simple diagram which shows how the names and address in the left hand side is a simple normalized table and by applying denormalized structure how we have created a flat table structure.

Rule 2:- Break your data in to logical pieces, make life simpler
This rule is actually the 1st rule from 1st normal formal. One of the signs of violation of this rule is if your queries are using too many string parsing functions like substring, charindexetc , probably this rule needs to be applied.
For instance you can see the below table which has student names , if you ever want to query student name who is having "Koirala" and not "Harisingh" , you can imagine what kind of query you can end up with.
So the better approach would be to break this field in to further logical pieces so that we can write clean and optimal queries.

Rule 3:- Do not get overdosed with rule 2
Developers are cute creatures. If you tell them this is the way, they keep doing it; well they overdo it leading to unwanted consequences. This also applies to rule 2 which we just talked above. When you think about decomposing, give a pause and ask yourself is it needed. As said the decomposition should be logical.
For instance you can see the phone number field; it's rare that you will operate on ISD codes of phone number separately(Until your application demands it). So it would be wise decision to just leave it as it can lead to more complications.

Rule 4:- Treat duplicate non-uniform data as your biggest enemy
Focus and refactor duplicate data. My personal worry about duplicate data is not that it takes hard disk space, but the confusion it creates.
For instance in the below diagram you can see "5th Standard" and "Fifth standard" means the same. Now you can say due to bad data entry or poor validation the data has come in to your system. Now if you ever want toderive a report they would show them as different entities which is very confusing from end user point of view.

One of the solutions would be to move the data in to a different master table altogether and refer then via foreign keys. You can see in the below figure how we have created a new master table called as "Standards" and linked the same using a simple foreign key.

Rule 5:- Watch for data separated by separators.
The second rule of 1st normal form says avoid repeating groups. One of the examples of repeating groups is explained in the below diagram. If you see the syllabus field closely, in one field we have too much data stuffed.These kinds of fields are termed as "Repeating groups". If we have to manipulate this data, the query would be complex and also I doubt performance of the queries.

These kinds of columns which have data stuffed with separator's need special attention and a better approach would be to move that field to a different table and link the same with keys for better management.
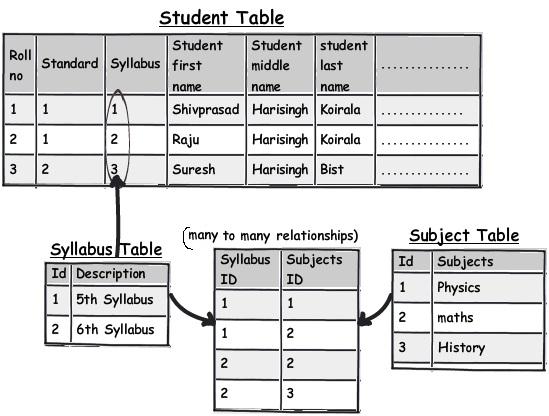
So now let's apply the second rule of 1st normal form "Avoid repeating groups". You can see in the above figure I have created a separate syllabus table and then made a many-to-many relationship with the subject table.
With this approach the syllabus field in the main table is no more repeating and having data separators.
Rule 6:- Watch for partial dependencies.
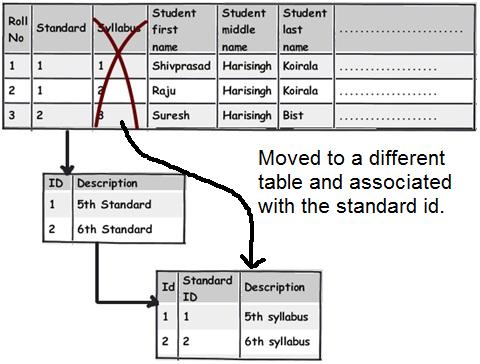
Watch for fields which are depending partially on primary keys. For instance in the above table we can see primary key is created on roll number and standard. Now watch the syllabus field closely. Syllabus field is associated with a standard and not with a student directly (roll number).
Syllabus is associated with the standard in which the student is studying and not directly with the student. So if tomorrow we want to update syllabus we have to update for each student which is pain staking and not logical. It makes more sense to move these fields out and associate them with the standard table.
You can see how we have move the syllabus field and attached the same to standards table.
This rule is nothing but second normal form "All keys should depend on the full primary key and not partially".
Rule 7:- Choose derived columns preciously

If you are working on OLTP applications must be getting rid of derive columns would be good thought, until there is some pressing reason of performance. In case of OLAP where we do lot of summations, calculations these kinds of fields are necessary to gain performance.
In the above figure you can see how average field is dependent on marks and subject. This is also one of form of redundancy. So for such kind of fields which are derived from other fields give a thought are they really necessary.
This rule is also termed as 3rd normal form "No columns should depend on other non-primary key columns". My personal thought is do not apply this rule blindly see the situation; it's not that redundant data is always bad. If the redundant data is calculative data , see the situation and then decide do you want to implement the third normal form.
Rule 8:- Do not be hard on avoidingredundancy, if performance is the key

Do not make it a strict rule that you will always avoid redundancy. If there is a pressing need of performance think about de-normalization. In normalization you need to make joins with many table and in denormalization the joins reduces and thus increasing performance.
Rule 9:- Multidimensional data is a different beast altogether
OLAP projects mostly deal with multidimensional data. For instance you can see the below figure, you would like to get sales as per country, customer and date. In simple words you are looking at sales figure which have 3 intersections of dimension data.

For such kind of situations a dimension and fact design is a better approach. In simple words you can create a simple central sales fact table which has the sales amount field and he makes a connection with all dimension tables using a foreign key relationship.


Rule 10:- Centralize name value table design
Many times I have come across name value tables. Name and value tables means it has key and some data associated with the key. For instance in the below figure you can see we have currency table and country table. If you watch the data closely they actually only have Key and value.

For such kind of table creating one central table and differentiating the data by using a type field makes more sense.
Rule 11:- For unlimited hierarchical data self-reference PK and FK
Many times we come across data with unlimited parent child hierarchy. For instance consider a Multi-level marketing scenario where one sales person can have multiple sales people below them. For such kind of scenarios using a self-referencing primary key and foreign key will help to achieve the same.

This article is not meant to say that do not follow normal forms , but do not follow them blindly , look at your project nature and type of data you are dealing with.

Out of full respect, below is a video which explains 3 normal forms step by step using a simple school table.
Rule 1:弄清(OLTP或OLAP)应用的本质是什么?
当开始制作数据表单设计时,首先,要分析你设计的这个程序的本质是什么?是事务性还是分析性的?你会发现许多开发者会默认应用常规化规则,随后才考虑性能问题而不考虑应用的本质。
关于事务性和分析性,一起来看下两者区别。
Transactional:这种应用,用户对CRUD较为感兴趣,即创建、读取、更新和删除记录。这种数据,官方名称之位OLTP。
Analytical:用户对分析、报告、预测等方面感兴趣。这类数据库很少有嵌入和更新。主要目的是为了尽快获取和分析数据。官方名称之为OLAP。

换句话说,如果你想以嵌入、更新、删除为重点,可选择常规化的表单设计或者创建一个简单的非常规化的数据架构。
下面是一个简单的图表,左侧显示名称和地址,采用非规范化结构设计出的一款简单的常规表单。

Rule 2:将数据按照逻辑思维分成不同的块,让生活更简单
这个规则其实就是 “三范式” 中的第一范式。这样设计的目标,是为了当你需要查询套多的字符串解析功能时,如子串,charindexetc,它能为你提供这项功能。
例如,注意观看下面的图表,如果你想查询某个学生的姓名,通过“Koirala”和“Harisingh”来进行区分。

因此,更好的方法就是打破数据逻辑思维,以便我们编写更加简洁、容易查询的表单。
Rule 3:当数据太多时,rule 2不可用
开发者们的思维有时很单一,如果你告诉他们某种方式,他们会一直这么做下去,要知道过度的使用会造成不必要的麻烦。正如我们之前谈到的rule 2,首先要进行分解,明确自己的需求。例如,当你看到电话号码字段时,你可以在ISD代码上进行操作区分这些电话号码(直到满足你的需求)。尽管这是不错的方法,但会给你带来更多的并发症。

Rule 4:将重复、不统一的数据视作你最大的敌人
聚焦和重构复制数据。我比较担心的不是复制数据所需要的磁盘空间而是它因此而造成的混乱。
从下面的图表中,“5th Standard”和“Fifth standard”意思是相同的,你可以说是因为数据或者验证数据录入到你的系统原因,如果你想通过报表来显示他们的不同之处,从用户的角度开看,这是非常困难的。

其中一个解决方法就是将不同的任务栏把相同的数据通过新建一个键入值联接在一起。如图。我们通过创建一个新的条目“Standards”即可将数据重新排,显示相同的部分。

Rule 5:注意被分隔符分割的数据
前面的规则2即“第一范式”提到避免数组重复,如图所示。如果你看到教学大纲紧密排列在一起,这个领域中需要很多数据来填充,这种我们称之为“重复数组”。如果我们必须操纵这些数据,单凭查询是很困难的,我甚至还怀疑是否具备这个查询功能。

这些带分隔符的数据需要特别注意,如何利用更好的方法将这些数据移动到一个不同的任务栏中,以便更好的分类呢?如图:

如图所示,可以看到我创建了一个独立的教学科目条目,然后列出了与之有相关联的科目。这种方法主要适用于在教学大纲领域,避免过多的重复和数据分隔符中。
Rule 6:当心数据依赖

观察该领域中的部分列表。如图,我们创建了roll number和standard,可以看到教学科目紧密联系在一起,但与学生学习的科目没有直接关联。如果我们想给每位学生更新教学科目,这似乎看起来是不符合逻辑的,但是通过键入standard条目转换这些数据就可达到目的。
这个规则告诉我们“所有的键入都应该依赖主键”。All keys should depend on the full primary key and not partially。
Rule 7:选择派生列

如果你想进行OLTP应用首先得筛选出派生列,在OLAP中我们需要做一些求和,方可获得uixie很好的性能。如图,求的平均数需要利用marks和subject两列。
这个规则被称为第三范式,“不应该有依赖于非主键的列”(No columns should depend on other non-primary key columns)我个人认为是不能盲目使用此规则。如果该数据是计算过的数据,看清状况然后在决定实施第三范式。
Rule 8:如果性能很关键,不要避开冗余数据

如果你迫切的考虑到性能规范化问题,通常情况下需要连接许多列表以及减少增加非规范化的列表以便来提高数据图表性能。
Rule 9:数据多、繁杂

OLAP项目主要是为了处理数据繁多,例如,如图所示,假如你想获得每个国家、每个用户、每年的销售额度。对于这种情况,你可以创建一个实际销售列表条目(sales fact table)。


Rule 10:设计name value table列表
明值表意味着它有一些键,这些键被其他数据关联着。如图所示,我们需要弄清楚currency table (货币列)和country table(国家列),图中键入值(数字部分)显示的就是我们所需要的数据。

通过创建键入值(Type)来显示出不同区域的数据。
Rule 11:无限制结构数据,自定义PK和FK
我们会经常碰到一些无限父子分级结构的数据。例如:考虑到一个多层次的营销方案,其中一个销售人员可以领导多个销售人员。在这种情况下,你可以使用自定义的主键和设置外键来帮助你实现统一。

您可以根据自身的项目需求选择不同的数据处理方法。如下所示:三种常规范式。
















 424
424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









