






rownumber() over(partition by col1 order by col2)去重的方法,很不错,在此记录下:
row_number() OVER ( PARTITION BY COL1 ORDER BY COL2) 表示根据COL1分组,在分组内部根据 COL2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的).
直接查询,中间很多相同的,但我只想取createdate时间最大的一条
select fromid,subunstall,kouchu,creatdate,syncdate,relate_key from BoxCount_Froms_Open
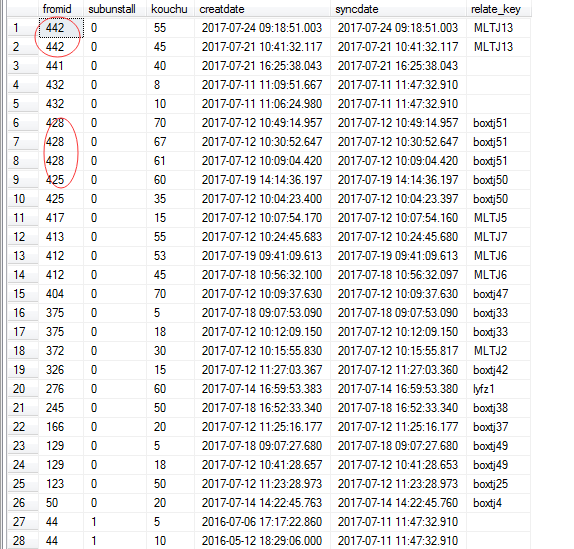
使用 PARTITION BY fromid ORDER BY creatdate DESC 根据中的 fromid分组,根据creatdate组内排序
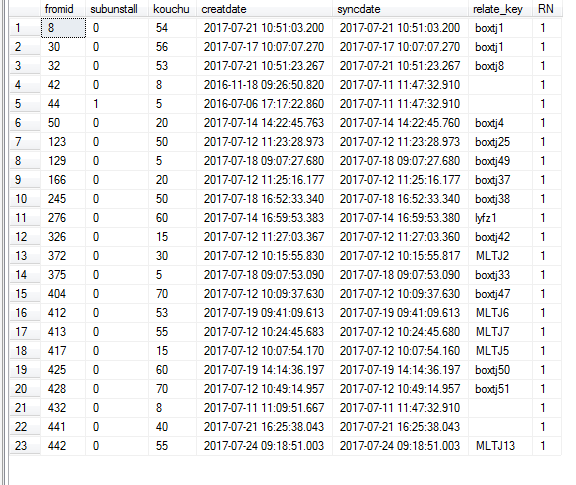
WHERE RN= 1;取第一条数据
SELECT * FROM (SELECT fromid,subunstall,kouchu,creatdate,syncdate,relate_key,ROW_NUMBER() OVER( PARTITION BY fromid ORDER BY creatdate DESC)RN FROM BoxCount_Froms_Open ) T WHERE RN= 1;















 3767
3767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









