







Hadoop-MapReduce学习
摘要
本文简要介绍MapReduce,重点是Shuffle部分。
1 MapReduce-Mapper侧
1.1 简介
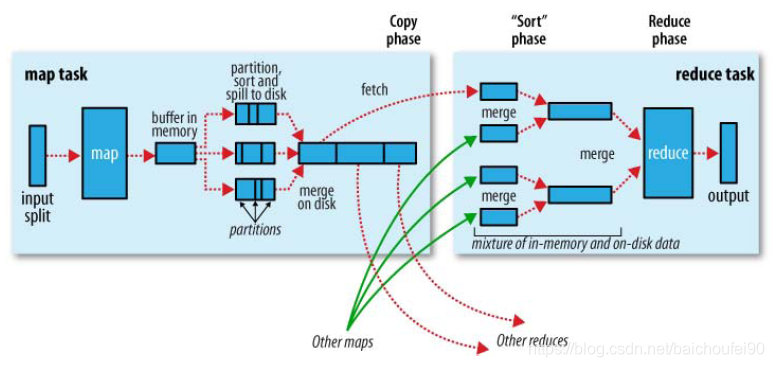
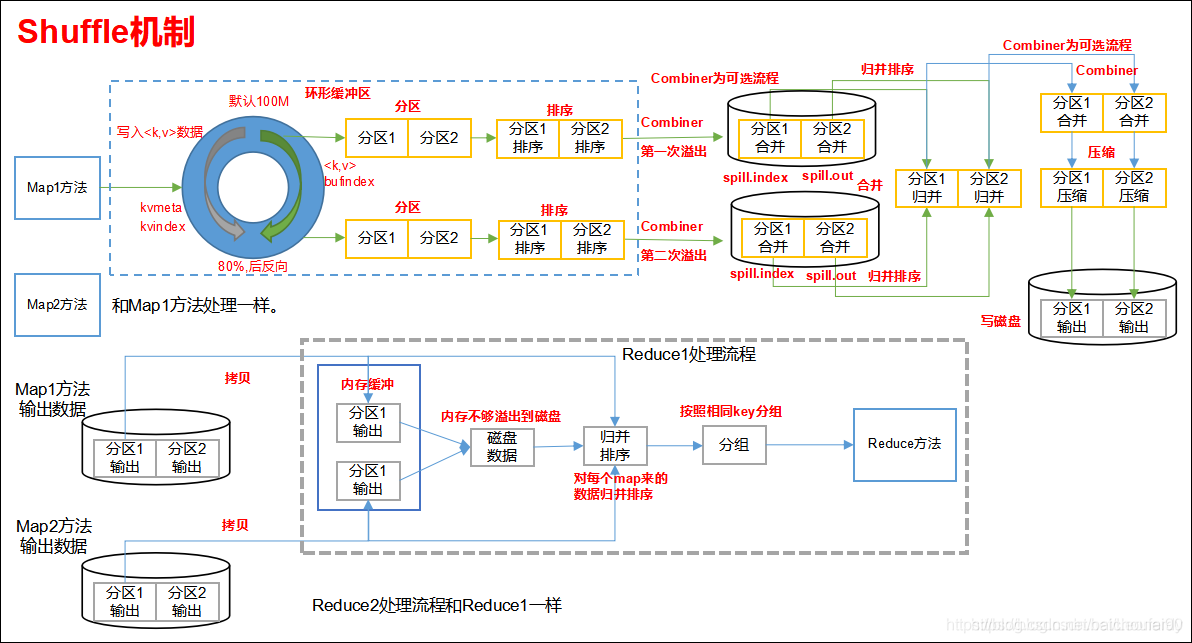
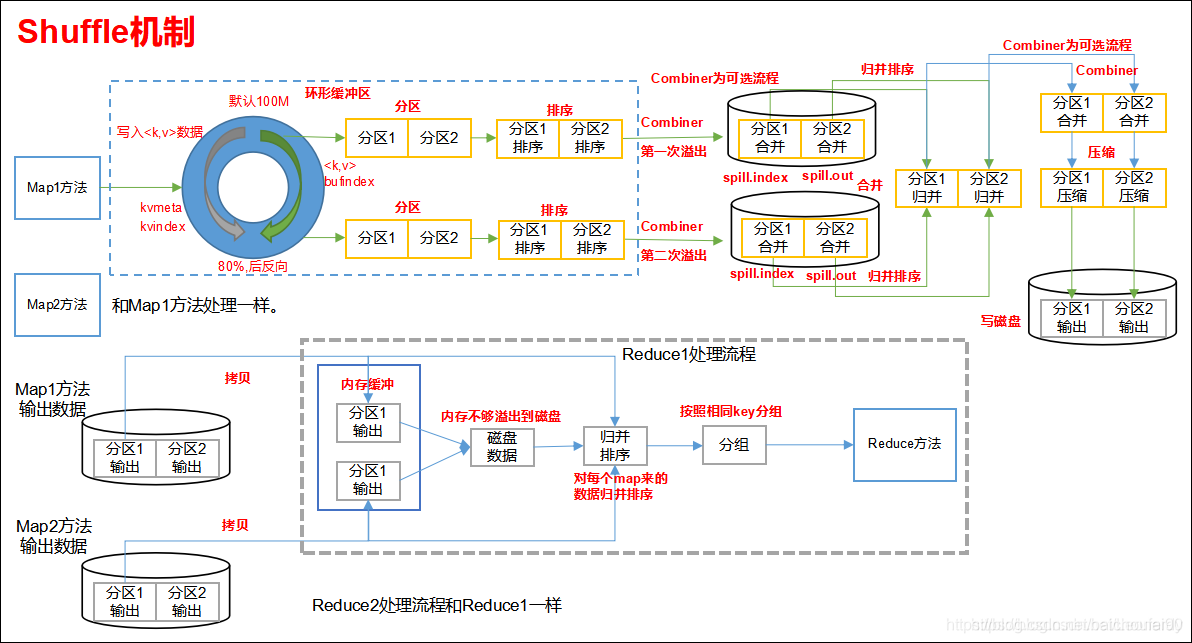
以上是一张Hadoop官方创作的MR过程图示。我们以大数据届的HelloWorld-WordCount为例讲述下MR过程。
再来一张网络图片:
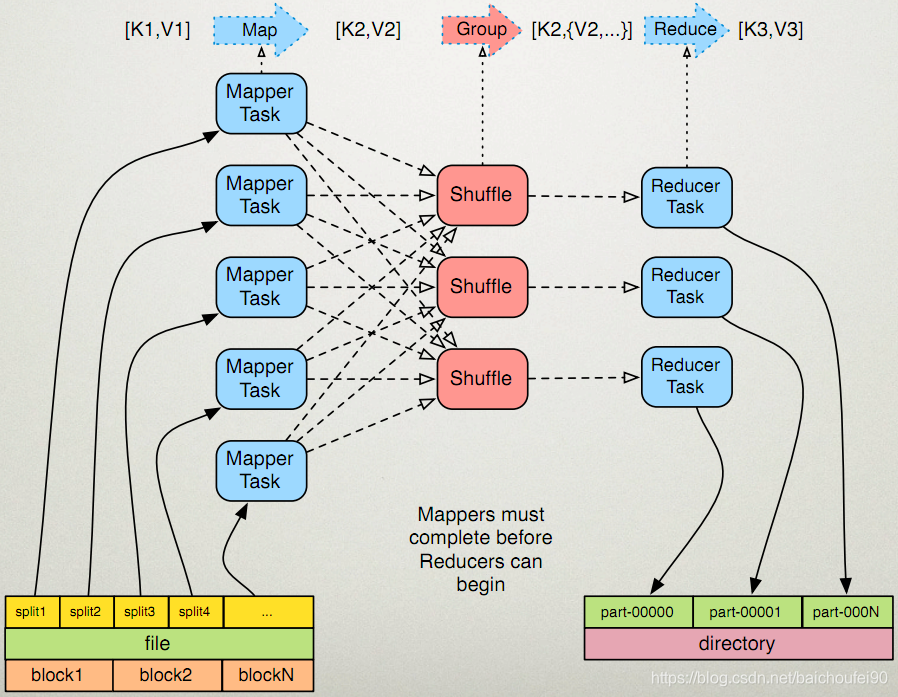
1.2 Split-分片
1.2.1 Split简述
-
会在客户端运行文件切片工作,以决定mapper数量等信息。分片信息会写入HDFS,以便后续map任务使用。
-
在运行Mapper前,
FileInputFormat会将输入文件分割成多个split(split属于逻辑上的概念),1个split至少包含1个Block(HDFS Block,默认大小为128M)。计算分片的工作是由Client做的,并复制到HDFS内,以便执行task时拉取。
申请资源时,会附带上此分片信息创建AM,AM根据此信息来申请Mapper。
-
为每一个Split运行一个map进行处理。比如把一个258MB的文件上传到HDFS上,假设block块大小是128MB,那么它就会被分成三个block块,与之对应产生三个split,所以最终会产生三个map task。
-
split阶段完成后得到的就是
<key,value>:- key为此行的开头相对于文件的起始位置的offset
- value就是此行的字符文本
1.2.2 Split详细流程
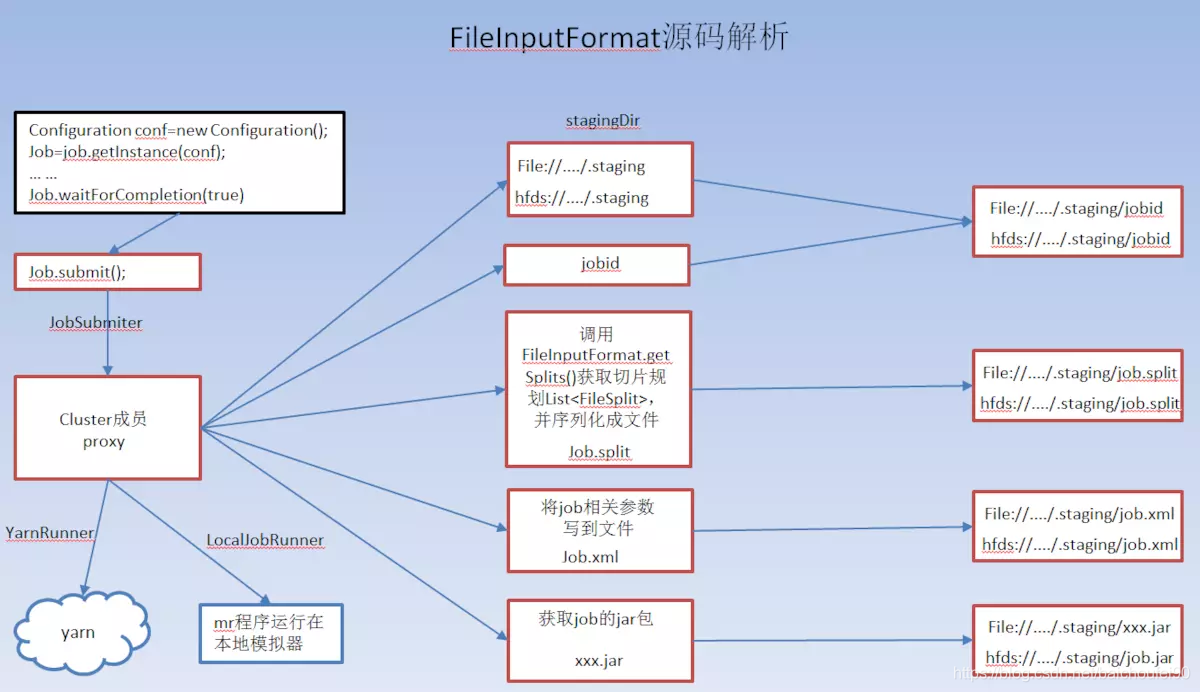
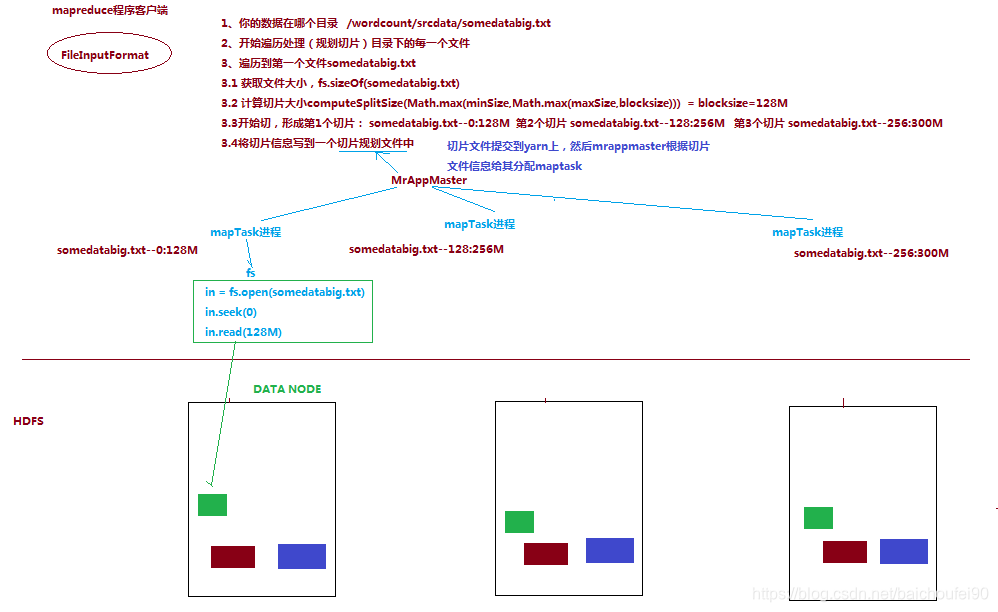
-
验证这个任务的输入规格
-
使用InputFormat具体的实现类,不同的输入有不同的分隔逻辑。如默认的FileInputFormat来将输入文件分配为多个逻辑上的split,并把该分片规划信息写入HDFS。具体来说,在split时会调用TextInputFormat的getSplits方法,根据具体的InputFormat进行文件Block拆分,最后的拆分规划会包含文件大小、拆分方式、文件路径、主机地址、是否在内存等信息,保存到HDFS上以供后续任务使用。这些数据在任务完成后被清除。
所谓的切片并不是真正的切片,只是记录文件的Block信息而已,构成逻辑上的Split对象而已。
-
Client会将对应split数创建一个变量来记录map任务数。
-
AppMaster会根据以上信息创建mapper
-
mapper使用
CreateRecordReader方法创建RecordReader,用来读取逻辑split所对应的数据
注意:这个地方就决定了map任务数
关于切片策略,可参考FileInputFormat切片机制
也可查看源码:
org.apache.hadoop.mapreduce.JobSubmitter的writeSplits方法。- Hadoop-2.4.1源码分析–MapReduce作业切片(Split)过程
- Hadoop文件分片split的原理解析
1.2.3 关于InputFormat
Hadoop内置的输入文件格式类有:
-
FileInputFormat<K,V>
顶层父类,用户自定义的File-Based的输入格式类,需要继承他。 -
TextInputFormat<LongWritable,Text>
这个是默认的数据格式类。key代表当前行数据距离文件开始的偏移量,value代码当前行的字符串。 -
SequenceFileInputFormat<K,V>
序列化文件输入格式,可以提高效率,但不便于查看结果。处理过程中可使用序列文件,
最后展示时使用可视化输出。 -
KeyValueTextInputFormat<Text,Text>这个是读取以
Tab(即\t)分隔的数据,每行数据内部如果以\t分隔,那么使用这个读入,就可以自动把\t前面的当做key,后面的当做value。 -
CombineFileInputFormat<K,V>合并大量小文件时使用。
它的原理是将多个小文件打包到一个Split中,减少生成的mapper数量,一个map任务能处理更多小文件。
但注意是尽量不要用hdfs放大量小文件,原因
- Namenode内存开销大
- Map任务寻址次数增加
解决方法是用sequenceFile将这些小文件合并为若干大文件,可将文件名作为key,内容作为value
-
MultipleInputs,用于使MR支持多个输入路径,每个Mapper可使用不同的输入路径。
1.2.4 SplitSize计算源码
protected long computeSplitSize(long blockSize, long minSize,
long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}
- minSize=Math.max(1, conf(mapreduce.input.fileinputformat.split.minsize,默认值为0)) = 1
- maxSize=mapreduce.input.fileinputformat.split.maxsize(默认未设置,所以取Long.MAX_VALUE)
- 所以一般而言SplitSize取值就是HDFS blockSize,默认128MB
关于SplitSize探讨,可参考大数据学习(5)MapReduce切片(Split)
1.3 Map
1.3.1 Map简述
-
Mapper对输入的Split中的每个
<key,value>调用map()函数进行运算,然后输出一个结果键值对<key,value>。 -
Partitioner:对map()的输出
<key,value>进行partition,即根据key或value及Reducer的数量来决定该key/value对最终应该交由哪个Reducer处理。得到的结果为partitionIdx。默认是对key Hash计算后再对Reducer数量取模,默认的取模方式只是为了避免数据倾斜。
-
然后该key/value对以及partitionIdx的结果都会被写入环形缓冲区。
-
Map阶段的key/value对的格式是由输入的格式所决定的,如果是默认的TextInputFormat,则将每行作为一个记录进程处理。可以用
StringTokenizer或string.split("")对该行数据按空格拆分再处理。
1.3.2 Map示例
输入:来自split的<key为就是每一行的偏移值,value为该行的内容>
输出:<word,1>
/**
* Map task
* 规定map中用到的数据类型,
* 这里的Text相当于jdk中的String,IntWritable相当于jdk的int类型,
* 不用Java数据类型而是hadoop自定义的类型的原因主要是为了可优化网络序列化传输。
* 为了让键值对可以在集群上移动,Hadoop提供了一些实现了WritableComparable接口的基本数据类型,以便用这些类型定义的数据可以被序列化进行网络传输、文件存储与大小比较。
* 模板参数:
* 第一个Object表示输入的key的类型;
* 第二个Text表示输入的value的类型;
* 第三个Text表示输出的key的类型;
* 第四个IntWritable表示输出的value的类型。
*/
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
//声明一个IntWritable变量,作计数用,每出现一个key,给其一个value=1的值
private final static IntWritable one = new IntWritable(1);
//用来暂存map输出中的key值,Text类型的
private Text word = new Text();
/**
* 这就是map函数,它的输入和Mapper抽象类中的相对应的,
* 此处的Object key,Text value的类型和上边的Object,Text是相对应的,而且最好一样,
* 不然的话,多数情况运行时会报错。
*
* map阶段的key-value对的格式是由输入的格式所决定的,
* 如果是默认的TextInputFormat,则每行作为一个记录进程处理,
* 其中key为此行的开头相对于文件的起始位置,value就是此行的字符文本
*
* @param key 输入key 为该行的首字母相对于文本文件的首地址的偏移量
* @param value 输入的value 存储的是文本文件中的一行(以回车符为行结束标记)
* @param context 用于输出内容的写入,保存map运算状态
* @throws IOException
* @throws InterruptedException
*/
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
/**
* map阶段的key-value对的格式是由输入的格式所决定的,
* 如果是默认的TextInputFormat,则每行作为一个记录进程处理,
* 其中key为此行的开头相对于文件的起始位置,value就是此行的字符文本
*/
// StringTokenizer是Java工具包中的一个类,默认以空格作为间隔,
// 故用StringTokenizer辅助做字符串的拆分,也可以用string.split("")。
StringTokenizer itr = new StringTokenizer(value.toString());
//遍历每行字符串中的单词
while (itr.hasMoreTokens()) {
// 将遍历到的每个单词设为key,value为1
word.set(itr.nextToken());
//输出设成的key/value值
context.write(word, one);
}
}
}
1.4 Spill-溢写
1.4.1 Spill简述
- Map任务调用
context.write(word, one)时,输出会先写到环形缓冲区。 - 有一个守护线程
SpillThread,在后台死循环的执行sortAndSpill任务当,即达到一定阈值后启动Spill线程刷入磁盘mapreduce.cluster.local.dir目录的作业特定子目录,在此过程中还会排序和按需进行key combine。
1.4.2 Spill过程

-
写环形缓冲区达到阈值开始Spill
前述Map任务输出结果写入环形缓冲区,当缓冲区达到阈值后(默认当缓冲区满80%)便启动溢写线程开始Spill溢写磁盘了。注意,在Spill过程中map输出会继续写到环形缓冲区,但如果写满就会被阻塞直到Spill完毕。
-
Partition / Sort
在溢写到磁盘之前,线程默认使用HashPartitioner按照(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks的方式将数据按reducer数量来分区,然后在分区内使用快速排序对缓冲区数据按照数据的key进行内存中排序。也就是说,最终数据按一下两个条件有序:- partitionIdx(每个partitionIdx表示一个分区(对应一个Reducer))
- 数据的key
-
Combine
如果设置了Combiner,在Sort之后还会对具有相同key的键值对进行map端合并,减少溢写到磁盘的数据量和传输到下游的数据量。Hive中就能通过hive.map.aggr开启Map端Combine。 -
索引
在输出时,还会产生索引,记录partition数据的起始位置、原始数据长度、压缩之后的数据长度。注意,索引首先放入内存,不够的时候才写盘。 -
Flush
做完前述工作后就开始写盘,一次spill就会产生一个文件如spill12.out(这里的12表示Spill次数),还有可能因为内存不够产生如spill12.out.index的对应所以你文件。所以一般最终完成后有多个Spill File。注意数据记录包含partitionIdx。因为已经经过排序,所以每个文件内部是有序的。
1.4.3 环形缓冲区
每个map任务都有一个用于输出结果的环形缓冲区。他位于内存,是首尾相连的环形数据结构,专门用来存储Key-Value格式的数据。
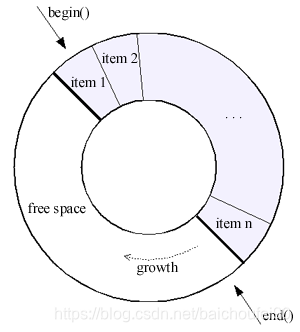
在Hadoop源码实现中,环形缓冲区是一个byte[],实现类位于org.apache.hadoop.mapred.MapTask:
private byte[] kvbuffer;
kvbuffer = new byte[maxMemUsage - recordCapacity];
- Map会在Spill同时继续写数据到环形缓冲区
如果把环形缓冲区的Kvbuffer占用满了再开始Spill,那Map任务就必须阻塞直到Spill完成后才能继续写数据;而MapReducer采用的做法是Kvbuffer占用到一定程度(比如80%,以io.sort.spill.percent控制)开始Spill,那么Map任务还能继续写数据。只要如果Spill够快,Map不需要因为空闲而阻塞。
1.5 Merge-合并
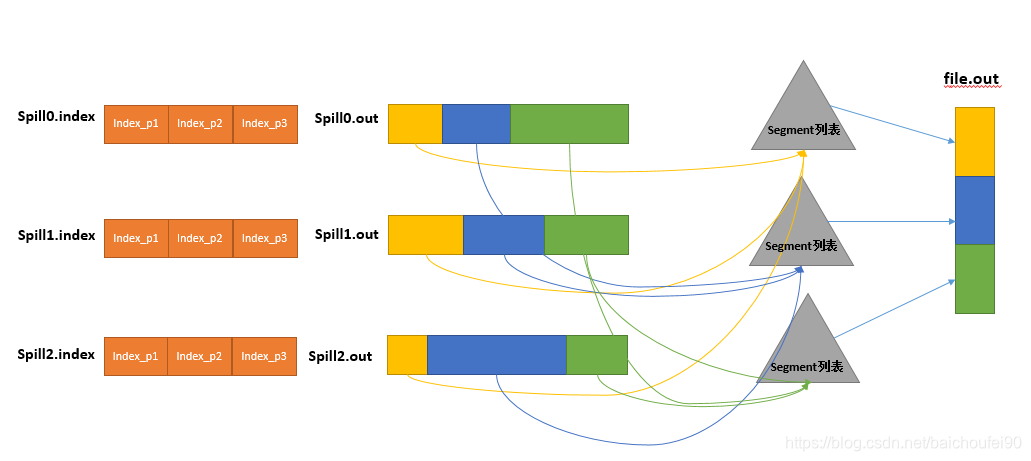
Spill可能会生成多个文件,这时需要将多个文件多次合并。合并的过程中又会不断地进行 sort& combine (按需)操作,最后合并成了一个已按ParitionIdx且已按key排序的文件。
控制每次合并的最大Stream数的参数为mapreduce.task.io.sort.factor,默认值为10。
注意,默认下如果至少存在3个Spill文件(由参数mapreduce.map.combine.minspills指定),则combiner就会在合并后输出文件到磁盘前再次运行。因为如果只有少于3个文件,执行combiner的开销并不值得。
1.6 压缩
默认情况下输出结果无压缩(通过mapreducer.map.output.compress=true可开启压缩,mapreduce.map.output.compress.codec可指定使用的压缩库),可以配置开启写盘时压缩,提升写盘速度,节约空间,并可减少shuffle时传递给Reducer的数据量。
但要注意权衡,因为压缩后后面过程还需要解压缩。
2 Reducer侧
2.1 Copy-拉取map输出
2.1.1 简述
- MR1
Reducer端通过AppMaster启动一些copy线程,通过HTTP方式从各个map端输出的文件中拉取属于自己的部分(比对Spill文件中的partitionIdx)拉取到本地。
每个NM节点都会启动一个常驻的HTTP Server,其中一项服务就是响应Reducer拉取Map数据的请求:当有MapOutput的HTTP请求过来的时候,HTTP server就读取相应的Map输出
文件中对应这个Reducer部分的数据,并通过网络流输出给Reducer。
- MR2
MapReduce2中,拉取数据的线程数不可指定,最大线程数基于机器的数量自动设定,默认为2倍。而且通信方式也由HTTP变为了Nety。
每个map任务的完成时间可能是不一样的,Reduce任务在map任务结束之后会尽快取走输出结果,这个阶段叫copy。
2.1.2 Copy的时机和方式
- Reducer是如何知道要去哪些机器去数据呢?
- 一旦map任务完成之后,就会通过常规心跳通知该应用程序的
Application Master,因此AM需要知道每个Job的map输出和主机位置的映射关系。 - Reducer的一个线程会周期性地向AM询问,直到提取完所有数据。
- 数据被Reducer提走之后,map任务所在节点不会立刻删除数据,这是为了预防reduce任务失败需要重试。因此map输出数据是在整个Reducer作业完成之后才被删除掉的。
- 一旦map任务完成之后,就会通过常规心跳通知该应用程序的
2.1.3 Copy的并行
Reducer有几个copier线程,并行从map任务机器取数据。默认有5个copy线程,可以通过mapreduce.reduce.shuffle.parallelcopies配置。
2.1.4 copy的数据存储
- 如果map输出的数据足够小,则会被拷贝到reduce任务的JVM内存中。
mapreduce.reduce.shuffle.input.buffer.percent配置JVM堆内存的多少比例可以用于存放map任务的输出结果。 - 如果数据太大容不下,则会拷贝到reduce任务所在节点的磁盘上。
- 总之,有些Map的数据较小是可以放在内存中的;有些数据较大需要放在磁盘上。也就是说,最终Reduce任务拉过来的数据有些在内存、有些放在磁盘上,最后会对这些来一个全局合并。
2.2 Merge-合并
-
Reducer任务Copy某个Map对应的数据,如果在内存中能放得下这次数据的话就直接把数据写到内存中。
-
Reduce要向每个Map拉取数据,在Reducer内存中每个Map对应一块数据。当内存中存储的Map数据占用空间达到一定程度的时候,开始
merge,把内存中的数据merge后flush到磁盘上的一个文件中(与map端类似,溢写过程会执行 sort & combine)。 -
如果在内存中不能放得下这个Map的数据的话,直接把Map数据写到磁盘上,在本地目录创建一个文件,从HTTP流中读取数据然后写到磁盘,使用的缓存区大小默认是64K。拉取一个Map数据过来后,就会创建一个文件。
-
如果生成了多个溢写文件,当文件数量达到一定阈值时,它们会被merge成一个有序的最终文件。合并时,如果文件压缩必须进行解压。
这个过程也会不停地执行 sort & combine 操作。
如果有50个mapper,合并因子
mapreduce.task.io.sort.factor为10,则每次合并10个文件,5趟后合并出了5个文件。
这里合并系数,并不是每次都合并固定数量文件,而是只要满足最后一次发送到reducer进行合并的文件等于合并系数即可。
比如40个文件,合并系数为10,则合并过程如下:
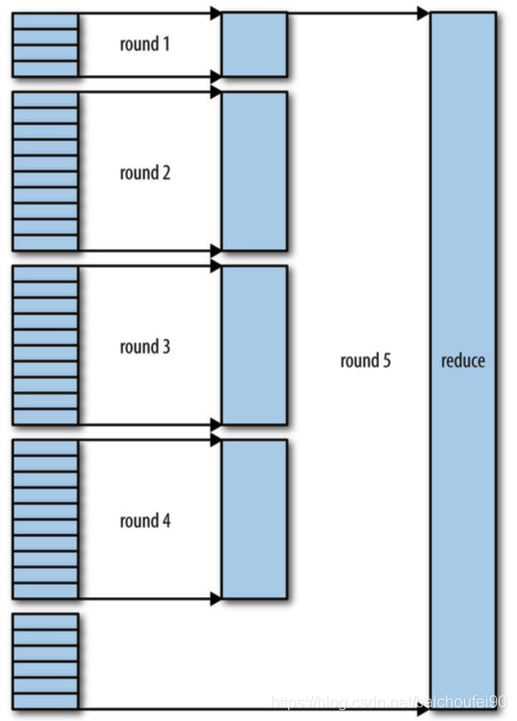
即第一趟合并4个文件,后3趟分别合并10个文件,最后得到4个已合并的文件和6个未合并文件,共十个留给reducer进行合并。
这样做的目的是尽量减少合并写入磁盘的数据量,因为最终总是会在内存合并后喂给reducer。
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
//由于map的打散,这里会得到如,{key,values}={"hello",{1,1,....}},这样的集合
for (IntWritable val : values) {
//这里需要逐一将它们的value取出来予以相加,取得总的出现次数,即为汇和
sum += val.get();
}
result.set(sum); //将values的和取得,并设成result对应的值
//此时的key即为map打散之后输出的key,没有变化,变化的是result,以前得到的是一个数字的集合,
//已经给算出和了,并做为key/value输出。
context.write(key, result);
}
最终输出的:
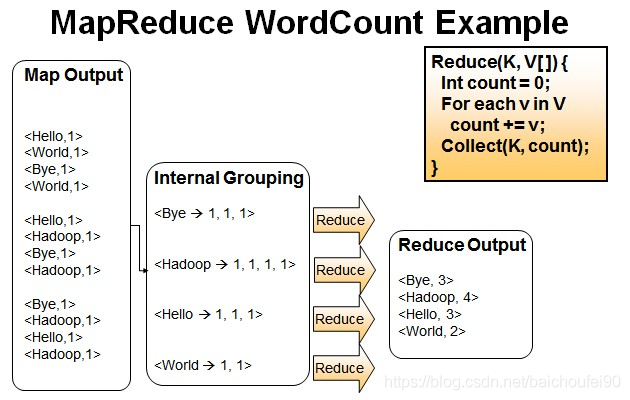
注意到,在Reduce输出前已经聚合
2.3 Reduce任务
在Merge完成后的几个文件,将会直接喂给Reducer函数,省去一次磁盘文件Merge开销。
在Reducer阶段,可有已放入内存的文件和尚在磁盘上的文件的混合Merge。
对已排序的每一个key/value对调用reduce()方法,并将最终结果写入HDFS。
2.4 示例
/**
* Reduce task
* a.Shuffle
* 1.Copy过程:
* Reduce端启动一些copy线程,通过HTTP方式将map端输出文件中属于自己的部分拉取到本地。
* Reduce会从多个map端拉取数据,并且每个map的数据都是有序的。
*
* 2.Merge过程:
* Copy过来的数据会先放入内存缓冲区中,这里的缓冲区比较大;
* 当缓冲区数据量达到一定阈值时,将数据溢写到磁盘(与map端类似,溢写过程会执行 sort & combine)。
* 如果生成了多个溢写文件,它们会被merge成一个有序的最终文件。这个过程也会不停地执行 sort(归并排序) & combine 操作。
*
* Reduce阶段:Shuffle阶段最终生成了一个有序的文件作为Reduce的输入,对于该文件中的每一个键值对调用reduce()方法,并将结果写到HDFS。
*
* b.调优
*
* reduce的静态类,这里和Map中的作用是一样的,设定输入/输出的值的类型
* 其中模板参数同Map一样,依次表示是输入键类型,输入值类型,输出键类型,输出值类型。
*
* wordCount例子中
* 第一个Text表示输入的key的类型;
* 第二个IntWritable表示输入的value的类型;
* 第三个Text表示输出的key的类型;
* 第四个IntWritable表示输出的value的类型。
*
*/
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
// 记录结果
private IntWritable result = new IntWritable();
/**
*
* @param key 为某个单词
* @param values 单词对应的单词个数迭代器,即是由各Mapper上对应单词的计数值所组成的列表
* 具体来说,是一个实现了 Iterable 接口的变量,
* 可以理解成 values 里包含若干个 IntWritable 整数,可以通过迭代的方式遍历所有的值
* @param context 和map context类似,记录输出
* @throws IOException
* @throws InterruptedException
*/
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
//由于map的打散,这里会得到如,{key,values}={"hello",{1,1,....}},这样的集合
for (IntWritable val : values) {
//这里需要逐一将它们的value取出来予以相加,取得总的出现次数,即为汇和
sum += val.get();
}
//将values的和取得,并设成result对应的值
result.set(sum);
//此时的key即为map打散之后输出的key,没有变化,
// 变化的是result,以前得到的是一个数字的集合,而这里是一个IntWritable结果
// 而这里是一个IntWritable结果,并做为key/value输出。
// 即最后输出的是<key, 出现次数>
context.write(key, result);
}
}
2.5 shuffle示例
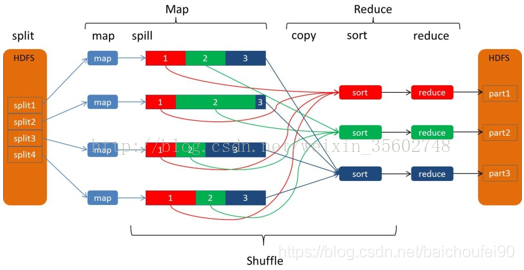
上图展示了一次简单的MapReduce任务shuffle流程。
- 4个map任务从各自的split读取数据
- map任务计算完成后,得到
<key,value>对输出到环形缓冲区,达到阈值后排序、combine后溢写到磁盘。此时磁盘里的数据就已经按partition和key排序。上图显示有3个partition,分别对应三个Reducer - Map任务完成后,通知AM
- Reducer周期性地向AM发起询问,如果有完成的map任务,就向该节点发请求获取数据。上图展示了所有Reducer拉取完成后,每个都拥有自己那部分数据
3 MapReduce优化
3.1 概述
本章主要记录Hadoop 2.x版本中MapReduce参数调优,不涉及Yarn的调优。
Hadoop默认的配置文件
- core-default.xml
- hdfs-default.xml
- mapred-default.xml
3.2 操作系统调优
3.2.1 思想
增加性能上限,关闭swap,加大预读缓存区
3.2.2 优化策略
- 增大打开文件数据和网络连接上限,调整内核参数
net.core.somaxconn,提高读写速度和网络带宽使用率 - 适当调整epoll的文件描述符上限,提高Hadoop RPC并发
- 关闭swap。如果进程内存不足,系统会将内存中的部分数据暂时写入磁盘,当需要时再将磁盘上的数据动态换置到内存中,这样会降低进程执行效率
- 增加预读缓存区大小。预读可以减少磁盘寻道次数和I/O等待时间
- 设置openfile
3.3 HDFS调优
3.3.1 思想
增加文件读写缓存大小,根据情况修改block大小
3.3.2 优化策略
3.3.2.1 core-default.xml:
-
hadoop.tmp.dir:
默认值: /tmp
说明: 尽量手动配置这个选项,否则的话都默认存在了里系统的默认临时文件/tmp里。
并且手动配置的时候,如果服务器是多磁盘的,每个磁盘都设置一个临时文件目录,这样便于mapreduce或者hdfs等使用的时候提高磁盘IO效率。 -
fs.trash.interval:
默认值: 0
说明: 这个是开启hdfs文件删除自动转移到垃圾箱的选项,值为垃圾箱文件清除时间。
一般开启这个会比较好,以防错误删除重要文件。单位是分钟。 -
io.file.buffer.size:
默认值:4096
说明:SequenceFiles在读写中可以使用的缓存大小,可减少 I/O 次数。
在大型的 Hadoop cluster,建议可设定为 65536 到 131072。
3.3.2.2 hdfs-default.xml:
-
dfs.blocksize:
默认值:134217728
说明: 这个就是hdfs里一个文件块的大小了,CDH5中默认128M。
太大的话会有较少map同时计算;太小的话也浪费可用map个数资源,而且文件太小namenode就浪费内存多。根据需要进行设置。 -
dfs.namenode.handler.count:
默认值:10
说明:设定namenode server threads的数量,这些 threads 会用 RPC 跟其他的datanodes通信。
当 datanodes 数量太多时会发现很容易出现 RPC timeout,解決方法是提升网络速度或提高这个值,
但要注意的是 thread 数量多也表示 namenode 消耗的内存也随着增加
3.4 MapReduce调优
3.4.1 Mapper端优化
3.4.1.1 思想
增加mapper环形缓冲区大小,减少spill磁盘次数;合理设置combiner合并因子减少合并到文件数目;结果压缩.
3.4.1.2 Mapper优化策略
-
增加环形缓存大小,减少spill磁盘次数
《hadoop权威指南》提到,map端可通过避免多次spill到磁盘来获得最佳性能,一次是最佳情况。
可以用MapReduce计数器(Spilled records 8.1节提到) 来计算在作业运行整个阶段中spill到磁盘的记录数。
估算出map输出大小后,可以合理设置io.sort.* 如增加io.sort.mb来扩大spill前的环形缓冲的值 -
合理设置combiner合并因子减少合并到文件数目
合并因子io.sort.factor控制在文件排序时,一次最多合并的流数。在Reduce中也会用到,很多人设为100。比如map端在任务写完最后一个输出记录后,会有几个spill文件,会将他们合并为一个已分区且已排序的输出文件,这个时候就要靠这个参数来调优。
注意,如果至少存在3个spill文件时,combiner就会在合并后的输出文件写到磁盘前再次运行(这就是map端的第二次combine)。而Reduce端在所有map任务都被复制过来后,开始文件合并。
比如有50个文件,
io.sort.factor=10,那就会合并5次,每次合并10个文件。最后得到5个中间文件。这个时候不会再合并,因为可以将这次合并在内存和磁盘中统一进行。最后Reducer去对每个key调用reduce函数,然后输出到fileSystem,避免不必要的combiner,比如在合并开销大于不合并直接处理时。还有min.num.spills.for.combine 指定运行combiner所需的最少spill文件数(如果已经指定combiner)
-
对结果压缩
最后,输出文件到磁盘前运行压缩十分重要,可以节约磁盘空间、减少传给reduce数据量。默认情况未开启压缩.
要根据实际情况,开启压缩和不开启哪个开销更小来决定,因为压缩后reduce还需要解压。
3.4.2 Reducer优化策略
3.4.2.1 思想
可以在数据量小时加大接收shuffle结果的缓存区减少写磁盘;设置combiner来减少写入磁盘的数据量;增加shuffle接收并发线程数
3.4.1.2 Reducer优化策略
-
增加shuffle接收缓存,尽量避免写盘或少写盘
在一个map任务完成后,会通知AppMaster,Reducer会有一个线程定时询问AppMaster来获取map情况,并拉取数据(只要有一个map任务完成就开始)如果map输出相当小,就会被直接复制到reduce任务的jvm内存(缓存区所占堆内存百分比大小可调),否则就会被复制到磁盘,当缓存达到阈值就会spill到磁盘。
也就是说,在reduce要处理数据量较小(也就是说map过来的数据少,缓存能放下)就设置尽可能多的内存给reduce接收从Map过来的数据的缓存使用
-
使用combiner减少写入磁盘数据量
如果指定了combiner,就可以在Reducer合并期间运行combiner,这样可以降低写入磁盘数据量。 -
io.sort.factor合并因子
Reducer同样需要合并文件。合理设置排序文件时一次最多合并的流的数量,使得尽量少的文件合并写入到磁盘(尽量让最后一次合并最多的文件,因为会合并到Reducer内存中进行下一步的reduce方法调用,而不是像前几次那样写入磁盘) -
增加Reducer拉取map数据的线程数
-
合理设置reducer个数。
当不需要reducer时,甚至可设置job.setNumReduceTasks(0)。如果reducer数量超过partitoner划分后数量,则一些reducer的输出为空。
3.5 任务优化
3.5.1 避免不必要排序
对于一些不需要排序的应用,比如hash join或者limit n,可以将排序变为可选环节,这样可以带来一些好处:
- 在Map Collect阶段,不再需要同时比较partition和key,只需要比较partition,并可以使用更快的计数排序(O(n))代替快速排序(O(NlgN))
- 在Map Combine阶段,不再需要进行归并排序,只需要按照字节合并数据块即可。
- 去掉排序之后,Shuffle和Reduce可同时进行,这样就消除了Reduce Task的屏障(所有数据拷贝完成之后才能执行reduce()函数)。
3.5.2 Shuffle阶段内部优化
- Map端–用Netty代替Jetty
- Reduce端–批拷贝
- 将Shuffle阶段从Reduce Task中独立出来
3.5.3 map join
采用map端join,引入mapreduce的输入缓存机制
基本思路:
- 需要join的两个文件,一个存储在HDFS中,一个使用
DistributedCache.addCacheFile()将需要join的另外一个文件加入到所有Map缓存中(小文件放缓存,就不用reducer了)。 - 在Map函数里读取该文件,进行join
- 将结果输出到reduce
- 注意,DistributedCache.addCacheFile()需要在作业提交前设置。
3.6 DistributedCache
3.6.1 概述
DistributedCache是为了方便用户进行应用程序开发而设计的文件分发工具。它能够将只读的外部文件进行自动分发到各个节点上进行本地缓存,以便task运行时加载。
具体来说,当用户启动Job时,会把-files -archives -libjars等指定的文件复制到HDFS,然后在任务运行前NM将文件从HDFS复制到本节点磁盘缓存中,并为任务的工作目录建立到这些文件的符号连接,以实现本地化。
-libjars就是指定文件还会在任务启动前添加到任务的classpath中。
NM还未缓存中各文件维护了一个Counter,任务启动时加一,执行完时减一,仅当计数降为0时才能删除这些文件。
缓存逐出原则是LRU。
3.6.2 DistributedCache的使用步骤
- 在HDFS中上传文件(文本文件、压缩文件、jar包等)
- 调用相关API添加文件信息
- task运行前直接调用文件读写API获取文件。
3.6.3 需要注意的点
采用mapjoin时,可以不使用reduce,这个时候可以设置reducetask 的数量为0
4 例子
4.1 代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.StringTokenizer;
/**
* Created by chengc on 2017/10/29
*
* Map:<k1, v1> ——> list(<k2, v2>)
* Reduce:<k2, list(v2)> ——> list(<k3, v3>)
*/
public class MyWordCount2
{
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
/**
* 默认用的这个partitioner
* partitione个数不能大于reducer的个数
* 即partitionerNum <= reducerNum
* 当partitionerNum < reducerNum ,多余的reducer会输出空文件
* @param <K>
* @param <V>
*/
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME", "hdfs");
// 取得系统的参数
// 如:core-site.xml、hdfs-site.xml和mapred-site.xml等
// 配置文件所有内容会在真正提交Job前写入HDFS的该任务临时目录下的job.xml文件中
Configuration conf = new Configuration();
// conf.set("fs.default.name", "hdfs://jmbigdatacluster");
// 设置MR运行参数
conf.set("mapreduce.app-submission.cross-platform", "true");
// 本地模式测试
conf.set("mapreduce.framework.name", "local");
// conf.set("mapreduce.framework.name", "yarn");
conf.set("mapreduce.job.jar","/Users/chengc/cc/work/projects/hadooptraining/hadoop/target/wordcount-0.1.0-SNAPSHOT.jar");
/*String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
//判断一下命令行输入路径/输出路径是否齐全,即是否为两个参数
System.err.println("Usage: wordcount <in> <out>");
System.exit(2); //若非两个参数,即退出
}*/
// 也可以在代码里写死路径
String inputPath = "/user/chengc/test/wordcount/input/kafka.txt";
String outputPath = "/user/chengc/test/wordcount/output/output5";
String[] otherArgs = {inputPath,outputPath};
/**
* 1.分片(Split):
* map阶段的输入通常是HDFS上文件,在运行Mapper前,FileInputFormat会将输入文件分割成多个split(逻辑) ——
* 1个split至少包含1个HDFS的Block(默认为128M);然后每一个分片运行一个map进行处理。
* 得到的就是<key,value> key为此行的开头相对于文件的起始位置,value就是此行的字符文本
* 详细过程如下:
* 1.1 验证这个任务的输入规格
* 1.2 将输入文件分配为多个逻辑上的split
* 1.3 将每个split分发给单独的mapper
* 1.4 mapper使用CreateRecordReader方法创建RecordReader,用来读取逻辑split所对应的数据
*
* 注意:这个地方就决定了map任务数
*/
// 构建一个MR job,除了配置还需传入Job名
Job job = Job.getInstance(conf, "word count");
// 要执行的MyWordCount2.class
job.setJarByClass(MyWordCount2.class);
/**
* 2.执行(Map):
* 对输入分片中的每个键值对调用map()函数进行运算,然后输出一个结果键值对。
* map阶段的key-value对的格式是由输入的格式所决定的,如果是默认的TextInputFormat,则每行作为一个记录进程处理,
*
* 在这个job中,我用TokenizerMapper这个类的map函数
*/
job.setMapperClass(TokenizerMapper.class);
/**
* 3.溢写(Spill):
* 注意:溢写到磁盘过程中map输出会继续输出到缓冲区,如果此过程中缓冲区被写满,那么map任务会被阻塞直到溢写过程完毕
*
* 3.1:Partition: 在溢写到磁盘之前,线程首先根据数据最终要传的reducer数量来讲数据划分成相应的分区
*
* 3.2: Sort:使用快排对每个分区内的数据进行排序
* 1.partitionIdx(每个partitionIdx表示一个分区,一个分区对应一个reduce)
* 2.数据的key
* 根据以上两个来进行排序
* 3.3: Combiner:如果设置了Combiner,那么在Sort之后,还会对具有相同key的键值对进行合并,减少溢写到磁盘的数据量。(<a,1>,<a,1> => <a,2>)
* 3.4: Map输出写在内存中的环形缓冲区
* 3.5: 默认当缓冲区满80%,启动溢写线程,将缓冲的数据写出到磁盘(一次spill产生一个文件,数据记录包含partitionIdx)
*/
/**
* 4.合并(Merge):
* spill可能会生成多个文件,这时需要将多个文件合并成一个文件。
* 合并的过程中会不断地进行 sort(归并排序) & combine 操作,最后合并成了一个已分区且已排序的文件。
*/
//指定combiner
job.setCombinerClass(IntSumReducer.class);
//在这个job中,我用IntSumReducer这个类的reduce函数
job.setReducerClass(IntSumReducer.class);
// 可设置使用的partitioner
job.setPartitionerClass(HashPartitioner.class);
//在map reduce的输出时,key的输出类型为Text
job.setOutputKeyClass(Text.class);
//在map reduce的输出时,value的输出类型为IntWritable
job.setOutputValueClass(IntWritable.class);
/**
* Hadoop内置的输入文件格式类有:
1)FileInputFormat<K,V>这个是基本的父类,自定义文件基础的输入格式类就直接使用它作为父类。
2)TextInputFormat<LongWritable,Text>这个是默认的数据格式类。key代表当前行数据距离文件开始的偏移量,value代码当前行字符串。
3)SequenceFileInputFormat<K,V>这个是序列文件输入格式,使用序列文件可以提高效率,但是不利于查看结果,建议在过程中使用序列文件,最后展示可以使用可视化输出。
4)KeyValueTextInputFormat<Text,Text>这个是读取以Tab(也即是\t)分隔的数据,每行数据如果以\t分隔,那么使用这个读入,就可以自动把\t前面的当做key,后面的当做value。
5)CombineFileInputFormat<K,V>合并大量小文件时使用。
它的原理是将多个小文件打包到一个分片中,减少生成的map数量,一个map能处理更多小文件。
但是尽量不要用hdfs放大量小文件,原因
a.namenode内存开销大
b.map任务寻址次数增加
解决方法是用sequenceFile将这些小文件合并为若干大文件,可将文件名作为key,内容作为value
6)MultipleInputs,多种输入,可以为每个输入指定逻辑处理的Mapper。
*/
//默认的输入格式,输出<行offset,行内容>的键值对
// spilit的时候会用具体的InputFormat的实现类TextInputFormat来读取文件进行划分
// 具体来说,在split时会调用TextInputFormat的getSplits方法
// 拿到的划分后的文件,会获取到文件大小、主机地址、是否在内存等信息
// 然后就根据split数确认了map任务数量
// 分片信息会写入HDFS,以便后续map任务使用
job.setInputFormatClass(TextInputFormat.class);
//按需设置排序函数
// job.setSortComparatorClass();
// 设置reducer数量
job.setNumReduceTasks(3);
//初始化要计算word的文件的路径
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
//初始化要计算word的文件的之后的结果的输出路径
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
//提交job到hadoop上去执行了,
// 意思是指如果这个job真正的执行完了则主函数正常退出,若没有真正的执行完就异常退出了。
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
4.2 运行结果
运行结果的输出目录如下:
-rw-r--r-- 1 chengc admin 8 10 16 13:27 ._SUCCESS.crc
-rw-r--r-- 1 chengc admin 12 10 16 13:26 .part-r-00000.crc
-rw-r--r-- 1 chengc admin 12 10 16 13:26 .part-r-00001.crc
-rw-r--r-- 1 chengc admin 12 10 16 13:27 .part-r-00002.crc
-rw-r--r-- 1 chengc admin 0 10 16 13:27 _SUCCESS
-rw-r--r-- 1 chengc admin 492 10 16 13:26 part-r-00000
-rw-r--r-- 1 chengc admin 388 10 16 13:26 part-r-00001
-rw-r--r-- 1 chengc admin 469 10 16 13:27 part-r-00002
因为我们使用job.setNumReduceTasks(3);设置了Reducer数为3,所以这里结果也分为了3个part。.crc结尾的表示校验码文件。
每个part-r-00000文件中就是结果:
API 4
Kafka's 1
Producer 1
We 1
What 2
allows 4
application: 1
applications 3
as 4
between 1
bottom 1
called 1
concepts: 1
core 1
data 4
database 1
exactly 1
example, 1
fault-tolerant 1
get 1
good 1
having 1
in 3
input 2
it 1
key 1
let's 1
lets 3
message 1
occur. 1
on 1
platform 1
process 2
react 1
real-time 2
records 5
run 1
running 1
store 1
stream 5
streams. 1
subscribe 2
system. 1
systems 1
them. 1
think 1
this 1
three 1
timestamp. 1
to 14
topics, 1
transform 1
up. 1
value, 1
way. 1
可以看到,结果是有序的。
4.3 命令行提交
参考
https://blog.csdn.net/weixin_42083008/article/details/109861241
更多好文
- mapred-default.xml
- core-default.xml
- yarn-default.xml
- 源码走读-Yarn-ResourceManager01-基础概念
- 源码走读-Yarn-ResourceManager05-MR任务提交-客户端侧分析
源码角度分析MR任务提交流程 - Yarn学习
详细描述了MR On Yarn提交流程 - hadoop的mapReduce和Spark的shuffle过程的详解与对比及优化














 3205
3205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









