






微服务架构上通过业务来划分服务的,通过REST调用,对外暴露的一个接口,可能需要很多个服务协同才能完成这个接口功能,如果链路上任何一个服务出现问题或者网络超时,都会形成导致接口调用失败。随着业务的不断扩张,服务之间互相调用会越来越复杂,在项目中引入sleuth可以方便程序进行调试。
Spring Cloud Sleuth为服务之间调用提供链路追踪。通过Sleuth可以很清楚的了解到一个服务请求经过了哪些服务,每个服务处理花费了多长。从而让我们可以很方便的理清各微服务间的调用关系。此外Sleuth可以帮助我们:
- 耗时分析: 通过Sleuth可以很方便的了解到每个采样请求的耗时,从而分析出哪些服务调用比较耗时;
- 可视化错误: 对于程序未捕捉的异常,可以通过集成Zipkin服务界面上看到;
- 链路优化: 对于调用比较频繁的服务,可以针对这些服务实施一些优化措施。
改造前面的feign、service(服务)
pom增加:
<!--sleuth跟踪-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>feign增加日志:
@Autowired
private IFeignService feignService;
private static Logger log = LoggerFactory.getLogger(FeignController.class);
@RequestMapping("/index")
public String index(){
log.info("feign info"); return feignService.index(); // @FeignClient(value = "service-hello")
}
service增加日志:
private static Logger log = LoggerFactory.getLogger(HelloController.class);
@RequestMapping("/index")
public String index() {
log.info("service info");
System.err.println("服务提供者client:" + name + "服务端口:" + port);
return "服务提供者client:" + name + "服务端口:" + port;
}
启动测试,打开eureka、feign、service

打开页面,正常

显示的日志如下:
2018-12-29 16:24:26.048 INFO [service-feign,1d270312e94cab85,1d270312e94cab85,false] 10692 --- [nio-8886-exec-8] c.e.fegin.controller.FeignController : feign info
2018-12-29 16:24:26.056 INFO [service-hello,1d270312e94cab85,5e23c30b75ee6755,false] 6560 --- [nio-8883-exec-5] c.e.e.controller.HelloController : service info[appname,traceId,spanId,exportable],也就是Sleuth的跟踪数据。其中:
- appname: 为微服务的服务名称;
- traceId\spanId: 为Sleuth链路追踪的两个术语,后面我们再仔细介绍;
- exportable 是否是发送给Zipkin
整合Zipkin服务
Zipkin是一个致力于收集分布式服务的时间数据的分布式跟踪系统。其主要涉及以下四个组件:
- collector: 数据采集;
- storage: 数据存储;
- search: 数据查询;
- UI: 数据展示.
Zipkin提供了可插拔数据存储方式:In-Memory、MySql、Cassandra以及Elasticsearch。接下来的测试为方便直接采用In-Memory方式进行存储,个人推荐Elasticsearch,特别是后续当我们需要整合ELK时。
构建zipkin项目
用的springboot2,所以构建zipkin没有找到适合的方法(@EnableZipkinServer....失效),所以直接在官网https://zipkin.io/下载了jar包运行:
打开http://localhost:9411
修改feign、service:
<!--sleuth跟踪-->
<!--<dependency>-->
<!--<groupId>org.springframework.cloud</groupId>-->
<!--<artifactId>spring-cloud-starter-sleuth</artifactId>-->
<!--</dependency>-->
<!-- Zipkin 已包含spring-cloud-starter-sleuth -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>properties配置:
spring.zipkin.base-url=http://localhost:9411spring.sleuth.sampler.percentage=1.0 # 默认
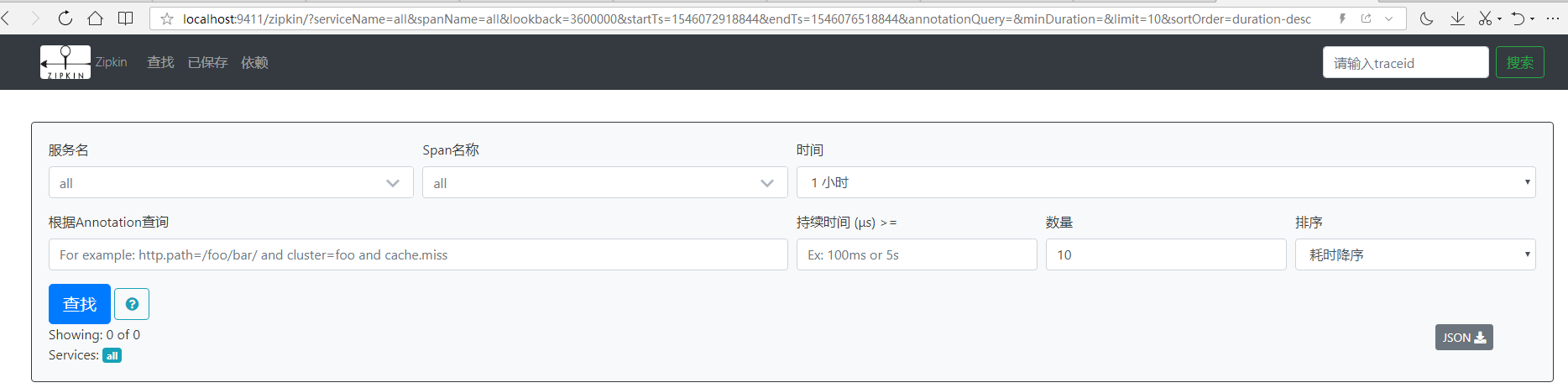
我们在浏览器中访问几次服务http://localhost:8886/index,然后转到Zipkin服务器

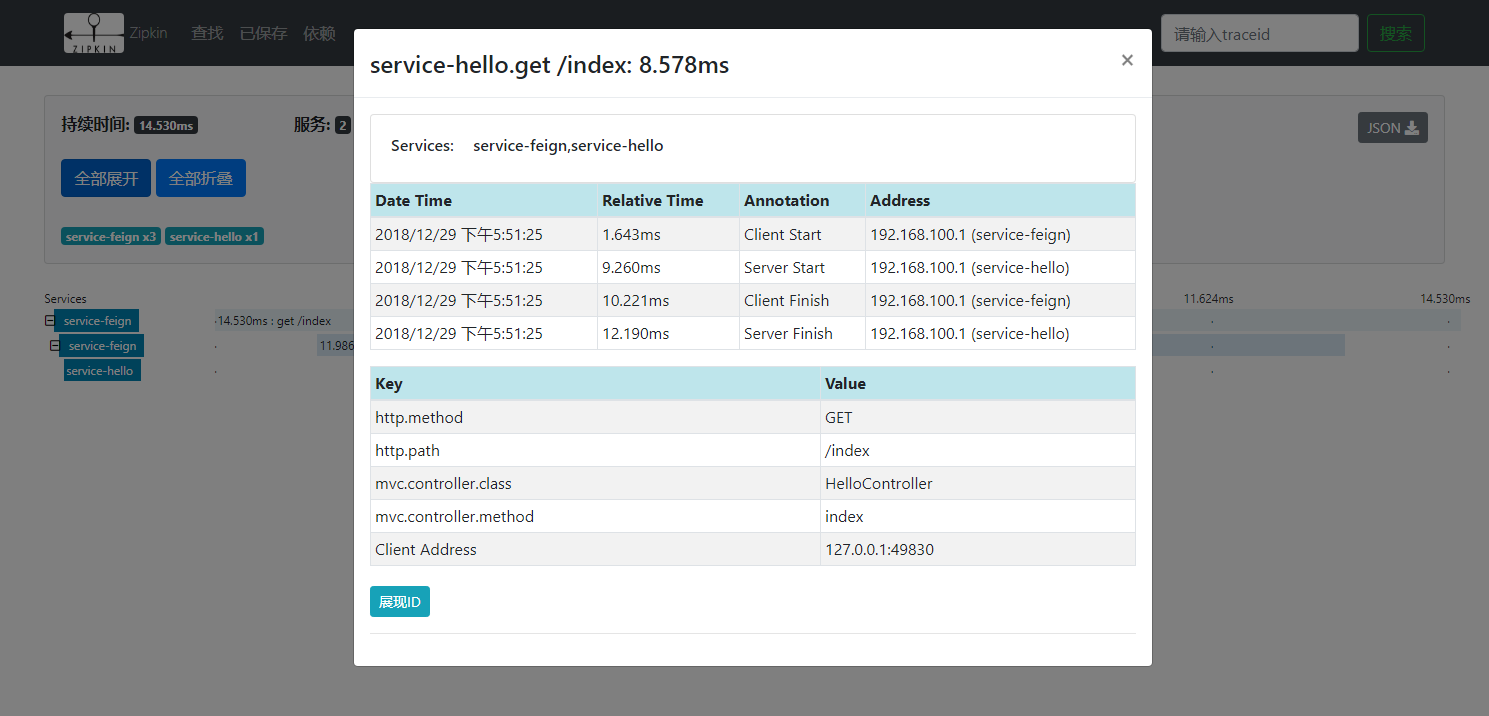
该界面对本次请求进行了更详细的展现。同样我们还可以再点击,以查看更为详细的数据,可以看到如下界面
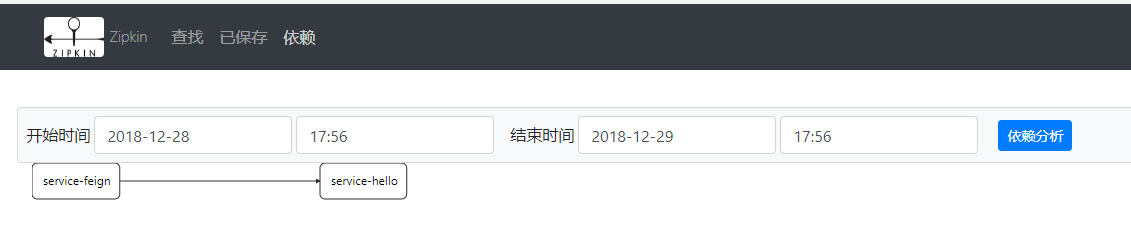
在Zipkin界面中我们还可以查看各服务之间的依赖关系
错误信息
Zipkin可以在跟踪记录中显示错误信息。当异常抛出并且没有捕获,Zipkin就会自动的换个颜色显示。在跟踪记录的清单中,当看到红色的记录时,就表示有异常抛出了。
关掉service-hello
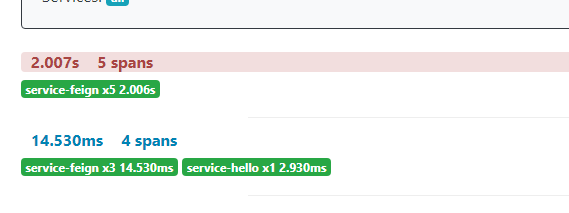
点击进去以获取更详细的错误信息。

采样率
在生成环境中,由于业务量比较大,所产生的跟踪数据可能会非常大,如果全部采集一是对业务有一定影响,二是对存储压力也会比较大,所以采样变的很重要。一般来说,我们也不需要把每一个发生的动作都进行记录。
Spring Cloud Sleuth有一个Sampler策略,可以通过这个实现类来控制采样算法。采样器不会阻碍span相关id的产生,但是会对导出以及附加事件标签的相关操作造成影响。 Sleuth默认采样算法的实现是Reservoir sampling,具体的实现类是PercentageBasedSampler,默认的采样比例为: 0.1(即10%)。
我们可以通过spring.sleuth.sampler.percentage来设置,所设置的值介于0.0到1.0之间,1.0则表示全部采集。
也可以通过实现bean的方式来设置采样为全部采样(AlwaysSampler)或者不采样(NeverSampler)
链接:https://www.jianshu.com/p/c3d191663279
來源:简书















 668
668











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









