







其实我阅读完原文后,本来想翻译出来,但是网上有很多这样的译文,我就没有翻译,直接转载了。
转载地址:https://blog.csdn.net/u014568072/article/details/78557837?locationNum=4&fps=1
Yoshua Bengio 2003
Abstract
统计语言模型建模(Statistical Language Modeling)目标是学习一种语言中单词序列的联合概率函数。维度限制会导致:模型中测试的单词序列与训练集中的单词序列不同。本文提出通过学习单词的分布式表示来解决维度问题。模型通过训练语句对指数级语义相关的句子进行建模。同时学习(1)每个单词的分布式表示(2)单词序列的概率函数。泛化(Generalization)是指从未出现的单词序列,可以通过类似的词的组成的已经出现的句子来获得较高的概率。本文介绍了使用神经网络的概率函数的实验,改进了n-gram模型,可以利用更长的上下文,并在两个文本预料上都显示了很好的效果。
关键词: 统计语言模型 人工神经网络 分布式表示 维数灾难
1 Introduction
当要模拟许多离散的随机变量之间的联合分布时,如句子中的单子和数据挖掘中的离散属性,维度灾难尤其明显。对于离散空间,泛化结构不明显:任何离散变量的变化都可能对估计函数造成重大影响。而每个离散变量的取值数目很大时,大多数观察对象的汉明距离就几乎是最远的。
根据给定的前t−1个词,统计语言模型可以由第t个词的条件概率表示
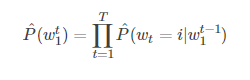
其中,wt是第t个单词,将子序列写为wji=(wi,wi+1,…,wj−1,wj)。这种统计语言模型被证明在设计自然语言的许多技术应用中非常有用,如语音识别、语言翻译个信息检索。
建立自然语言模型时可以利用词序显著降低建模问题的难度。对于大量上下文中的n−1个单词组合,n-gram模型为下一个单词构造条件概率函数:
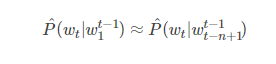
我们只考虑语料库中实际出现的连续词组合,或者频繁出现的连续词组合。
对于语料库中未出现的n元单词新组合,为避免为其分配零概率,考虑back-off trigram models (Katz, 1987)或者smoothed (or interpolated) trigram models(Jelinek and Mercer, 1980)中使用的方法:使用更小的语料进行概率预测。获得新的单词序列的方法主要是与插值(interpolated)或者n元回退(backoff n-gram)模型相关的生成模型,通过“粘合(gluing)”训练数据中短且重复的长度为1,2甚至n个频繁出现的单词来生成新的单词序列。
1.2 Previous Work
利用神经网络对高维离散的分布进行建模,对于学习Z1…Zn的联合概率分布有很大用处(Bengio and Bengio, 2000a,b)。在该模型中,联合概率分布被分解为条件概率的乘积:
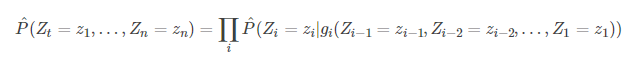
使用神经网络进行语言建模:Miikkulainen and Dyer, 1991;基于字符的文本压缩,利用神经网络预测下一个字符的概率(Schmidhuber, 1996);模型由于没有隐藏单元和单个输入词而被限制为捕获单数据和二元数据统计(Xu and Rudnicky, 2000)
发现单词相似关系获得新序列的泛化:基于学习词汇聚类的方法(Brown et al., 1992, Pereira et al., 1993, Niesler et al., 1998, Baker and McCallum, 1998)
向量空间表示方法在文本中的使用:信息检索(Schutze, 1993)
2 A Neural Model
模型: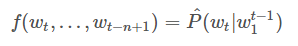
其中,训练集由w1…wt序列组成,wt∈V单词V是有限的集合。将模型分解为两个部分:
将词汇表VV中的元素ii映射到实向量C(i)∈RC(i)∈R中,该向量表示词汇表中每个词的分布式特征向量。C(i)C(i)是一个大小为|V|×m|V|×m的自由参数矩阵。
函数g将上下文单词的特征向量(C(wt−n+1),…,C(wt−1))(C(wt−n+1),…,C(wt−1))作为输入序列,将它们映射为V中下一个单词wt的条件概率分布。g的输出是第ii个单词的估计概率向量P(wt=i|wt−11)P(wt=i|w1t−1)。如下图所示
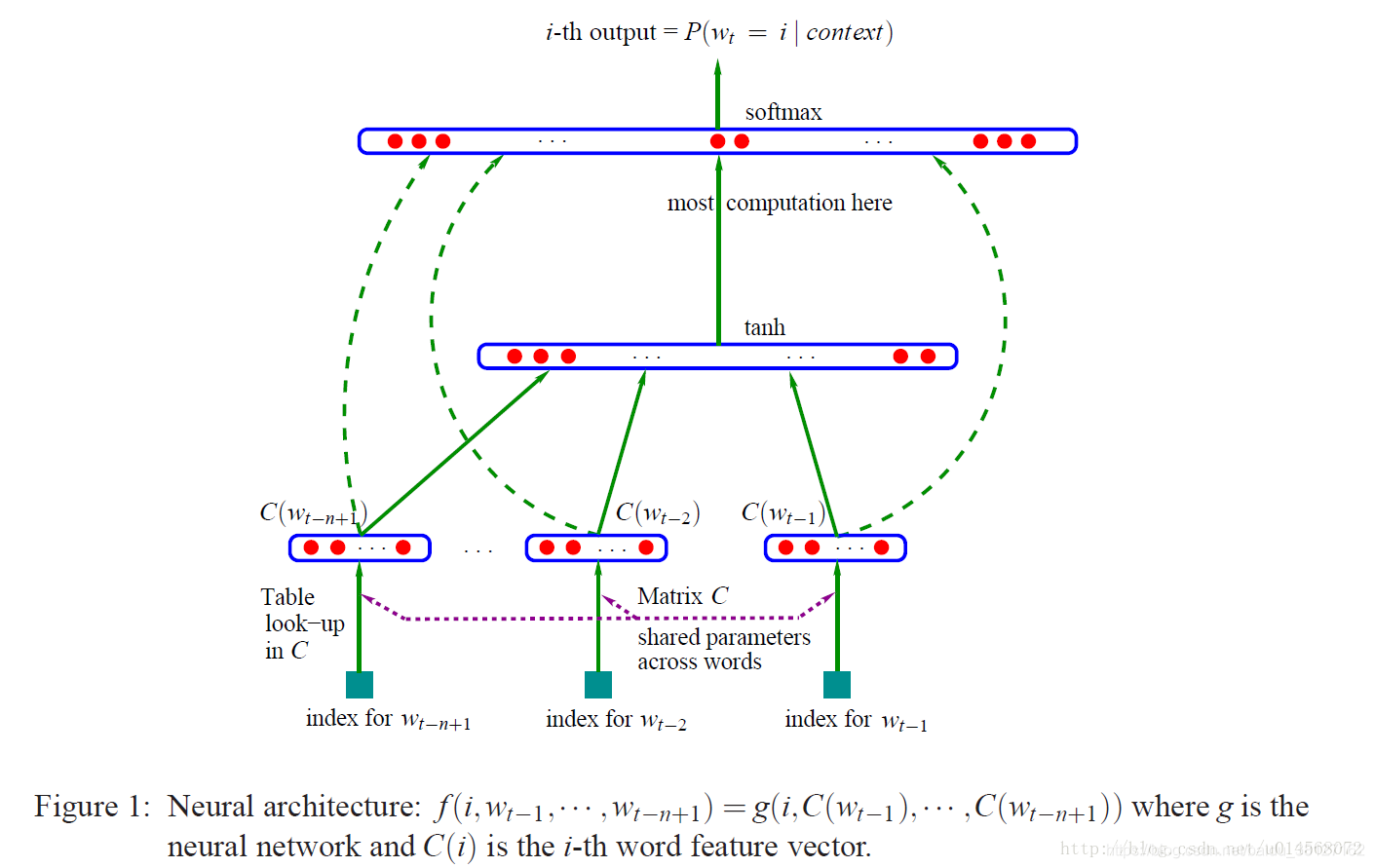
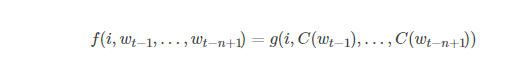
函数f是映射C和g的组合,C在上下文所有单词间共享。矩阵C的第i行对应第i个单词的特征向量C(i)。函数g通过带有参数w的前馈或递归神经网络或其他参数化函数来实现。整体参数集θ=(C,w)。
训练通过最大化训练语料库的惩罚似然估计θθ来实现:
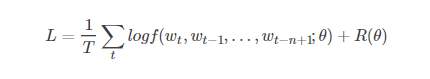
其中R(θ)是正则项。在模型中自由参数的数量至于单词数量V线性相关
在本文的大部分实验中,神经网络具有一个隐藏层,单词特征到输出的直接连接是可选的。因此实际存在两层隐藏层:共享的单词特征层C,和普通的双曲正切隐藏层。神经网络使用softmax输出层计算以下函数以保证正概率总和为1:
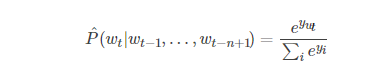
yi是对于每个输出单词i计算的未归一化对数概率:
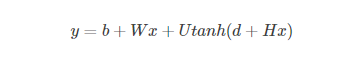
W=0 时C与输出层不直接连接,x是单词特征层激活向量(word features layer activation vector)
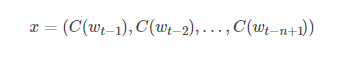
另h为隐藏单元的数量,m是每个单词特征的数量。当单词特征向量与输出之间不直接连接时,W被设置为0。模型的自由参数有:输出偏差b|V|×1,隐藏层偏差dh×1,隐藏层到输出层的权重U|V|×h,单词特征到输出层的权重W|V|×(n−1),隐藏层权重Hh×(n−1),和单词特征C|V|×m:
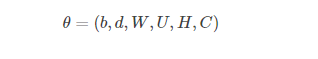
自由参数的个数是|V|(1+nm+h)+h(1+(n−1)m)|。注意理论上来说,如果W和H存在权重衰减而C没有,那么W和H可以向零收敛,而C将会爆炸(blow up)。在实践中,当使用随机梯度上升来训练时,我们没有观察到这种现象。神经网络中的随机梯度上升执行以下迭代更新:
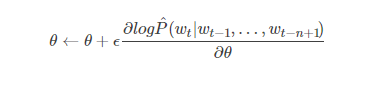
其中ϵ是学习效率。
混合模型:我们通过实验发现将神经网络中的概率预测与插值三元模型相结合可以获得提高的效果。
为了直观理解这个模型,举个例子:假如现在我们要根据文档中出现的前3个词,来预测下一个词,则初始化部分:
对所有的文档提取单词制作一个词汇表,每个单词有一个唯一的索引,即词汇表每行代表一个单词的embedding
模型参数的初始化,除了神经网络的连接权重初始化之外,还需要初始化一张词汇表
前向传播部分:
从文档中提取模型的输入,输入为3个单词的索引。
模型根据输入的3个单词的索引从词汇表中拿出对应的embedding表示得到每个单词的词向量。假如我们打算将每个单词转换为1个50维的向量,此时3个单词就转换为3个向量,每个都是50维。
将3个50维向量串在一起,变为一个150维的向量作为网络的输入层,传送给隐层
对于隐层的每个神经元,150维输入乘以与每个神经元链接的权重,求和后输入给tanh激活函数
激活函数的输出作为输出层(softmax)的输入,假设隐层的神经元数量为300个,则输出层的输入就是一个300维向量
softmax层的单元数量为词汇表的单词数量|V|,对每个单元,输入的300维乘以与输出层连接的权重后求和,并计算各个单元输出的概率作为下一个单词是第i个单词的概率。在这里例子中为300维向量,则对第i个softmax单元,权重为1个300维向量,转置后与输入相乘。
每一个softmax‘单元的输出为一个概率值,指示在词汇表中第i个单词为第四个单词的概率整个softmax的输出为一个长度为词汇表长度的概率分布,其和为1
反向部分:
计算softmax的代价函数,用softmax的输出向量与真实的第四个单词的1-hot向量做点乘再取-log
使用BP,一层一层求出网络连接权重的偏导数,并使用梯度下降更新
对词向量层也需要求偏导数使用梯度下降来更新词向量表,整个过程反复迭代,词汇表就得到了不断的更新
原文:https://blog.csdn.net/hx14301009/article/details/80345449
3 Parallel Implementation
4 Experimental Results
语料1: Brown corpus 布朗语料库
内容: 1,181,041 words(80w用于训练集,20w用于验证集,181,041用于测试集)
单词数量(无重复): 47,578(包括标点符号,区分大小写,包括用于分割文本和段落的语法标记)
将出现次数<3的单词合并成为一个单一的符号,将词汇量减少到16,383。
语料2: the Associated Press (AP) News from 1995 and 1996。
内容: 训练集(13,994,528),验证集(963,138),测试集(963,071)
4.1 N-Gram Model
用于与神经网络比较的第一个基准是基于插值法或者平滑法的trigram模型。令qt=l(freq(wt−1,wt−2))qt=l(freq(wt−1,wt−2))代表作为输入的上下文(wt−1,wt−2)(wt−1,wt−2)出现的离散频率。条件概率估计:
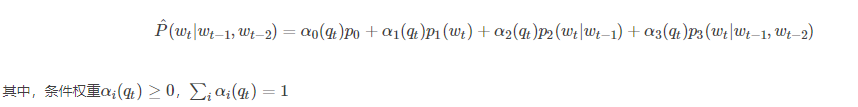 其中,条件权重αi(qt)≥0,∑iαi(qt)=1
其中,条件权重αi(qt)≥0,∑iαi(qt)=1
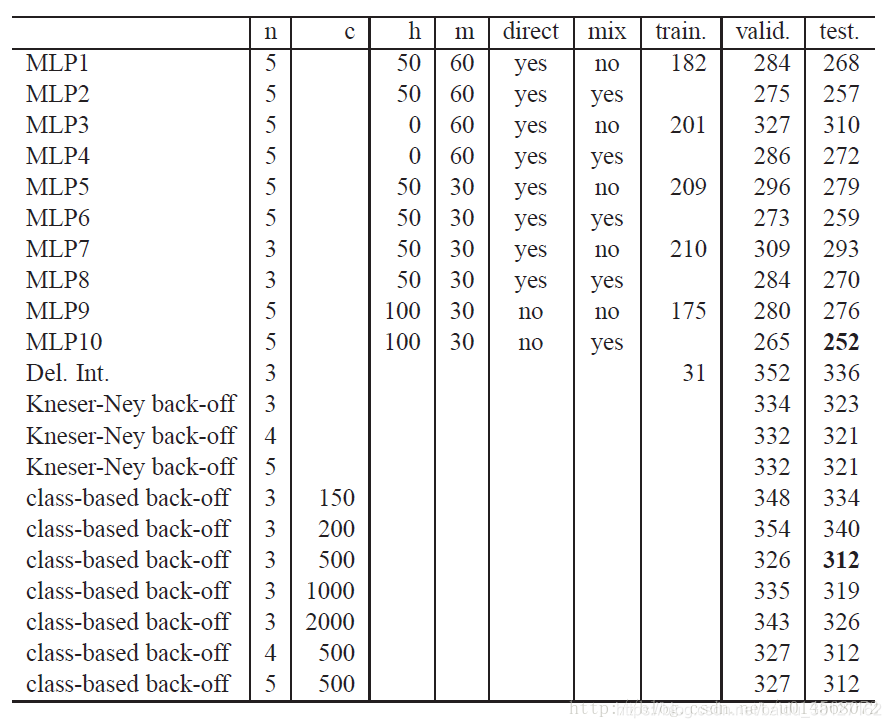
4.2 Result
所有的back-off model 都是改进的Kneser-Ney n-grams,这比标准的back-off model做的更好。词特征由随机初始化完成(类似神经网络权重的初始化),但是利用基于知识的初始化可能会获得更好的结果。














 225
225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









