






1.python 中分组统计
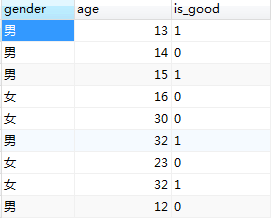
1.1按性别统计出年龄最大,最小,平均值
import pandas as pd
df = pd.read_excel(r'./data.xlsx')
print(df)
ages = df.groupby(['gender'])['age']
ages_min = ages.min()
ages_max = ages.max()
ages_mean = ages.mean()
print(ages_min)
print(ages_max)
print(ages_mean)
'''
输出结果
gender
女 16
男 12
Name: age, dtype: int64
gender
女 32
男 32
Name: age, dtype: int64
gender
女 25.25
男 17.20
Name: age, dtype: float64
'''1.2生成一列sum_age 对age 进行累加
df['sum_age'] = df['age'].cumsum()
print(df)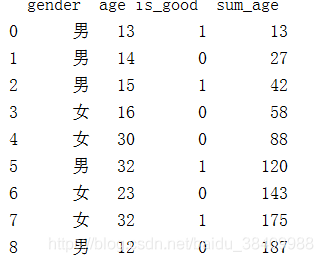
1.3新生成一列sum_age_new 按照gender和is_good对age进行累加
df['sum_age_new'] = df.groupby(['gender','is_good'])['age'].cumsum()
print(df)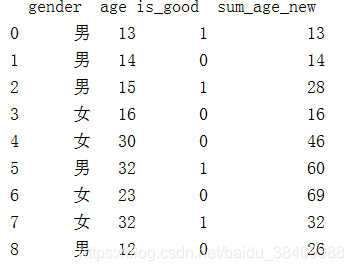
2.python中排序问题
2.1 按照年龄进行排序
df['rank'] = df['age'].rank()
df['rank_mean'] = df['age'].rank(method='average')
df['rank_min'] = df['age'].rank(method='min')
df['rank_max'] = df['age'].rank(method='max')
df['rank_first'] = df['age'].rank(method='first')
print(df)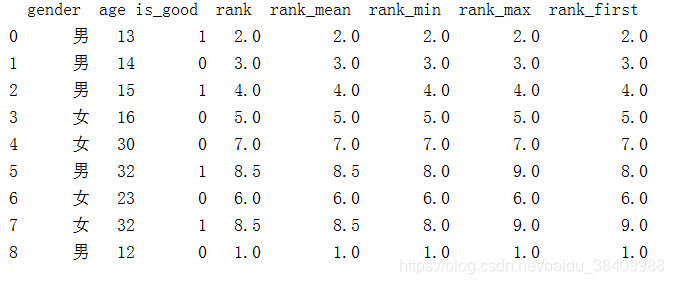
根据不同的性别对年龄进行排序
df['rank_g'] = df.groupby(['gender'])['age'].rank()
print(df)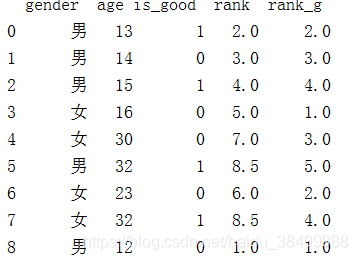
2.2在排序的过程中遇到两个数值相同,空置的排序情况,在这种条件下rank如何进行参数设置
首先排序过程中存在相同的数值时?
rank()函数参数设置
1.method : {‘average’, ‘min’, ‘max’, ‘first’, ‘dense’}, default ‘average’ 主要用来当排序时存在相同值参数设置;
默认为average平均值:年龄为32的数值,排序应该为8,9取平均值则为8.5
min:排序中最小值,年龄排序中取值为8
max:排序中最大值,年龄排序中取值9
first:同样数值按照值出现的前后进行排序 5号性别为男的年龄排序为8,7号性别为女的排序为9
dense: like ‘min’, but rank always increases by 1 between groups 排序时当值相同时,相同的值为同一排名类似min值排序,后续值排名在此排名基础上加一
2.na_option : {‘keep’, ‘top’, ‘bottom’}, default ‘keep’ 当排序数据中存在空值时,默认值设置为keep
How to rank NaN values:
- keep: assign NaN rank to NaN values 默认空值不参与排序
- top: assign smallest rank to NaN values if ascending 默认为升序时从空值为最小值排序
- bottom: assign highest rank to NaN values if ascending 默认升序时 空置为
df['rank'] = df['age'].rank(method='first') df['rank_k'] = df['age'].rank(method='first',na_option='keep') df['rank_t'] = df['age'].rank(method='first',na_option='top') df['rank_b'] = df['age'].rank(method='first',na_option='bottom') print(df)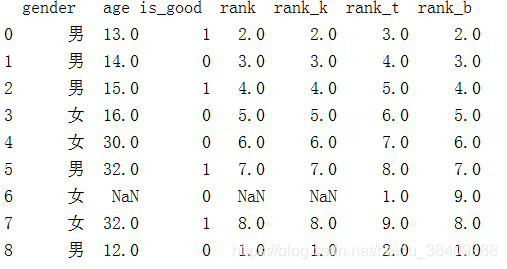
data['rank'] = data.groupby(['Name_y'])['Salary'].rank(ascending=False,method='dense')
print(data)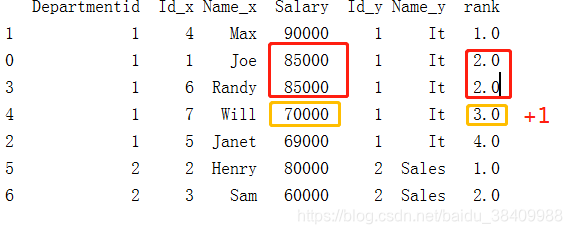
3.对salary进行降序排序,对于排序中相同salary值按照emp_no的大小进行排序
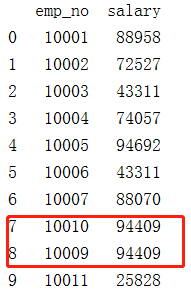
在使用pandas时先按照emp_no和salary进行值的排序,然后再进行rank(method=‘dense’)排序
df = pd.DataFrame({'emp_no':[10001,10002,10003,10004,10005,10006,10007,10010,10009,10011],'salary':[88958,72527,43311,74057,94692,43311,88070,94409,94409,25828]})
print(df)
df['排序-1'] = df.sort_values(by=['emp_no','salary'])['salary'].rank(method='first',ascending=False)
dt = df.sort_values(by=['排序-1'])
print(dt)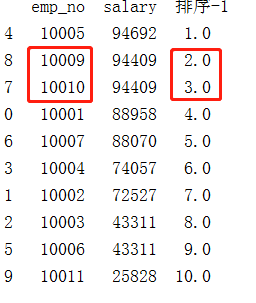
df['排序-1'] = df['salary'].rank(method='dense',ascending=False)
dt = df.sort_values(by=['排序-1','emp_no'])
print(dt)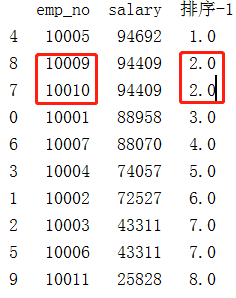














 609
609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









