







目录
HDFS写数据流程
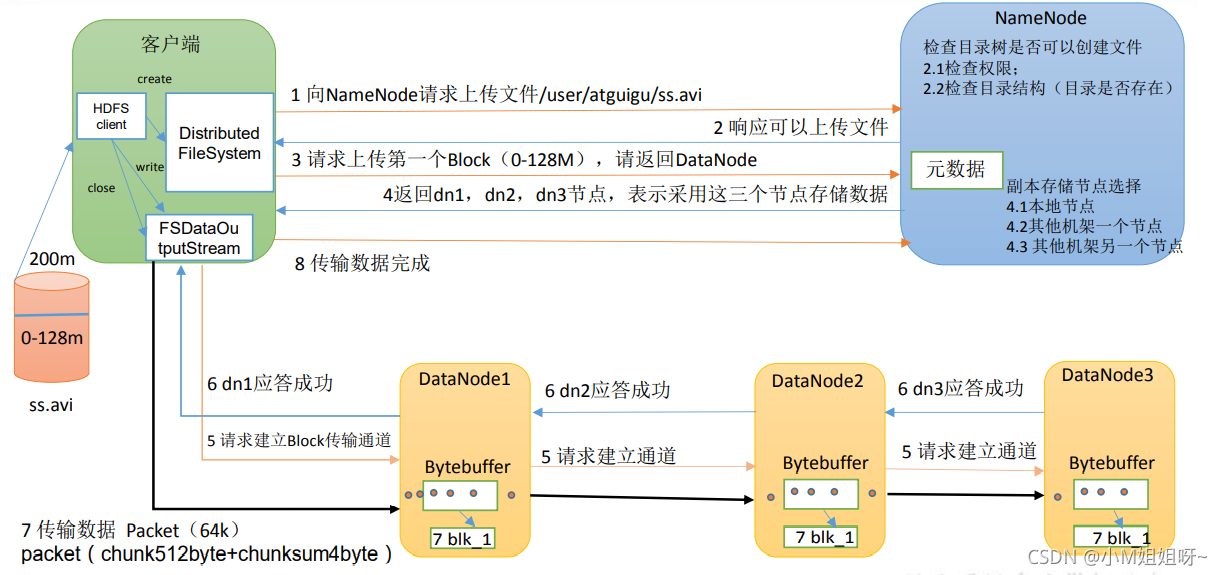
1)客户端通过分布式文件系统模块向namenode请求上传某个数据
(2)namenode根据客户端请求,先查看该用户是否有权限上传数据,再查看客户端所请求的目录是否存在。在namenode检查完全部后,给客户端一个可以上传的响应。
(3)客户端听到可以上传的响应后,便开始上传第一个block,询问namenode数据存放在哪些datanode里面?
(4)namenode告诉客户端可以存放在dn1,dn2,dn3这三个节点。而namenode是如何在众多节点中选择存放节点的呢?namenode会考虑稳定性、效率性。
(5)客户端通过数据输出流模块请求 dn1 上传数据,dn1 收到请求会继续调用 dn2,然后 dn2 调用 dn3,将这个通信管道建立完成。
(6)dn1、dn2、dn3 逐级应答客户端
(7)客户端以packet为单位,开始传输数据。dn1收到数据放入到本地磁盘,并从磁盘中读取数据放入内存,之后再通过内存中的数据传输给dn2 ,dn3
(8) 第一个blocks上传完成后,重复(3)-(7)
HDFS读数据流程
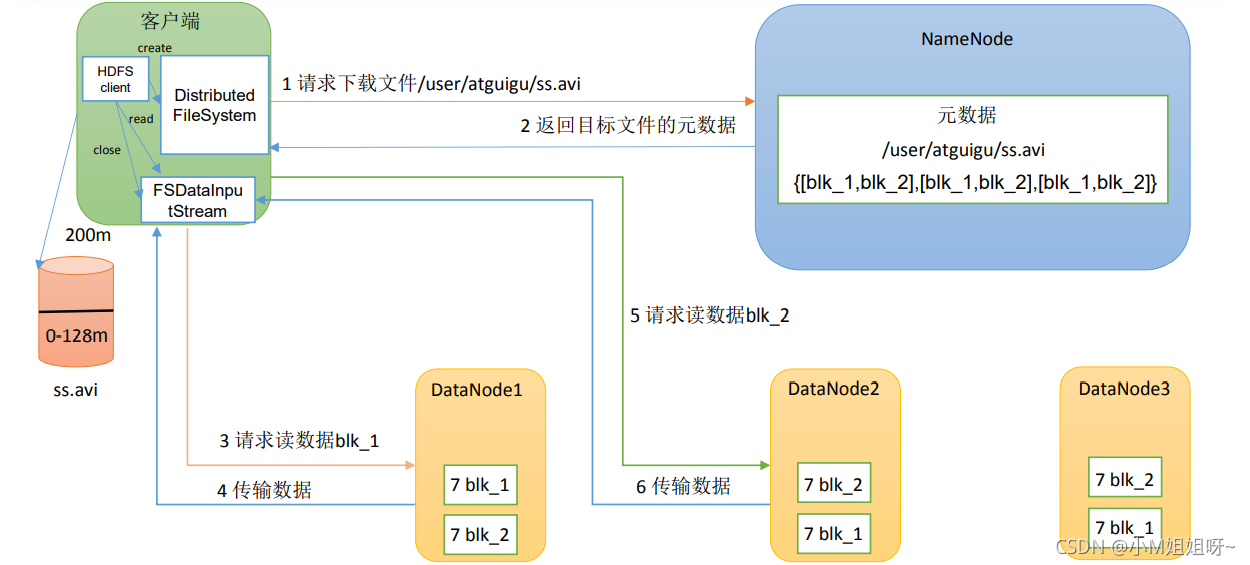
(1)客户端通过分布式文件系统向Namenode请求下载文件
(2)namenode返回文件所在的元数据(即所在位置)
(3)挑选一台 DataNode(就近原则,然后随机)服务器,请求读取数据。
(4)DataNode 开始传输数据给客户端(从磁盘里面读取数据输入流,以 Packet 为单位)。(如果检测到datanote1的数据访问量很多,则客户端则会选择在其他datanode中下载第二个block)
(5)客户端以 Packet 为单位接收,先在本地缓存,然后写入目标文件。















 478
478











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











