






数组,链表,树,栈,队列,堆,图,散列表
数组:
内存连续,数组中的元素通过数组下标进行访问,数组下标从0开始。
优点:
索引查询元素速度快。
缺点:
无法扩容 。
只能存储一种类型的数据
插入,删除,要移动其他元素。
链表
链表的存储单元不是连续的,每个节点包括自身的数据还有指向下一个节点的引用,通过引用找到下一个节点。
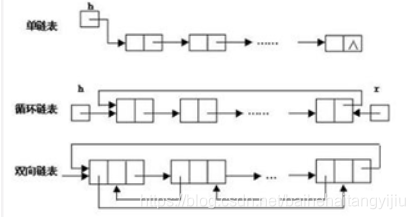
优点:
不需要初始化容量,可以任意加减元素。
插入或者删除元素只需要节点的指针指向,不用像连续存储空间的数组那样移动后面所有元素。
单链表查找都要从头开始遍历,耗时。
树
每个节点有零个或多个子节点
没有父节点的节点称为根节点
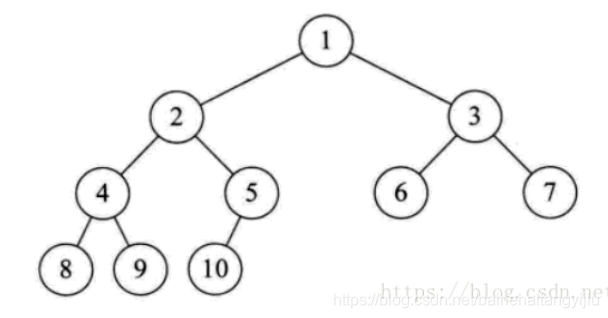
二叉树,
每个结点最多有两颗子树,每个结点最多有两颗子树。
添加,删除元素都很快,在处理大批量的动态数据方面非常有用。
扩展的数据结构,包括平衡二叉树、红黑树、B+树,mysql的数据库索引结构用的就是B+树。HashMap的底层源码中用到了红黑树。
栈
先进后出。
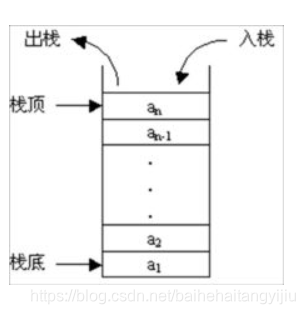
栈常应用于实现递归功能方面的场景,例如斐波那契数列。
队列
先进先出。从一端放入元素,从一端取出元素。
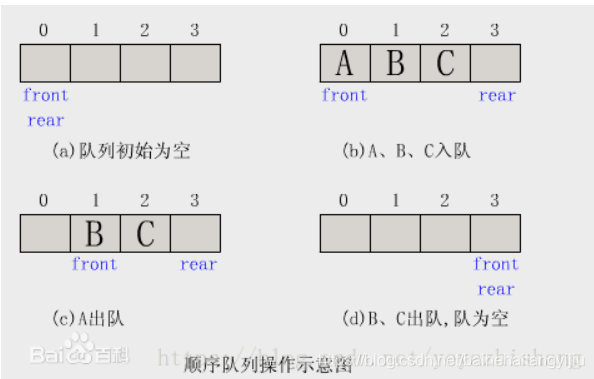
使用场景:因为队列先进先出的特点,在多线程阻塞队列管理中非常适用。
堆
堆总是一棵完全二叉树
堆中某个节点的值总是不大于或不小于其父节点的值,堆顶元素最大或最小。
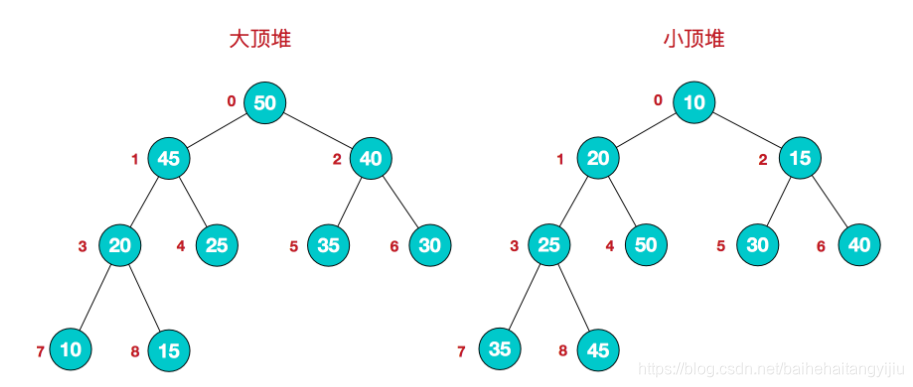
应用场景:大量的数据需要取出前k个最大,而内存又不够,可以用堆来实现。比如要在庞大的数据中找到前k个最小的元素,先用k个元素建一个大顶堆,然后依次遍历大量数据,和大顶堆的堆顶比较,如果小于堆顶元素,则添加到堆,堆顶元素弹出。遍历完大量数据后,堆就是前k个最小的元素。
散列表(哈希表)
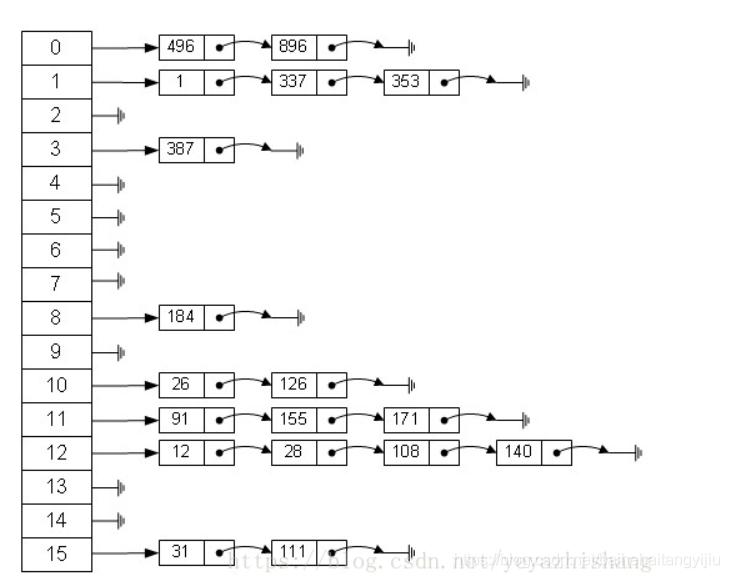
key和value, 通过key的hash值找到value。常见的解决冲突采用数组+链表的形式。
数组中存储key值,链表存储产生冲突的key的value。
先计算key的hash值,hash值对数组长度取余,得到数组下标,若数组下标对应元素不为空,则直接存到数组中,若已经存在元素,则判断是由于hash冲突导致的,还是本身key就是相等的,如果是hash冲突导致的,则添加到链表中,若本身相等,则替换。
图
图是由结点的有穷集合V和边的集合E组成。其中,为了与树形结构加以区别,在图结构中常常将结点称为顶点,边是顶点的有序偶对,若两个顶点之间存在一条边,就表示这两个顶点具有相邻关系。
按照顶点指向的方向可分为无向图和有向图:
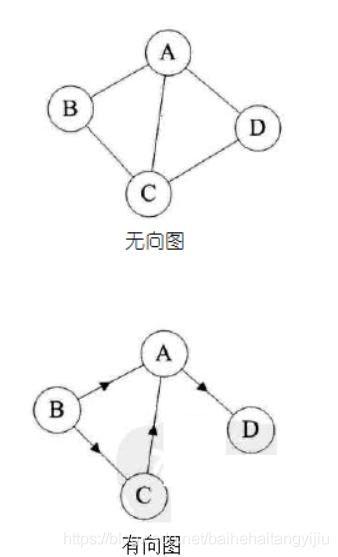
图是一种比较复杂的数据结构,在存储数据上有着比较复杂和高效的算法,分别有邻接矩阵 、邻接表、十字链表、邻接多重表、边集数组等存储结构














 68万+
68万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









