







1、向hadoop集群提交一些比较大的任务,集群负载很快就飚起来了,有的达到120多。
分析一下,应该是任务起的线程太多了。用jstack看一下,发现每个child的gc线程太多了:

达到了18个,一个child的gc线程就要开这么多,难怪负载会飙升。
修改提交作业的客户端配置 mapred-site.xml :

将child的gc方式设置成串行gc或者将并行gc的线程数设置的少一些。
ParallelGCThreads的默认算法:
ParallelGCThreads= cupNum < 8 ? cupNum : 3+(cupNum * 5) / 8
2、使用fairshare调度器,当在hadoop的监控页面中查看某个队列的作业时,不小心 将web地址的队列名去掉,如:
http://jobtracker:50030/jobqueue_details.jsp?queueName=a 将queueName=a改成
queueName=空 或者没有 的队列,jobtracker 会报下面的错误:
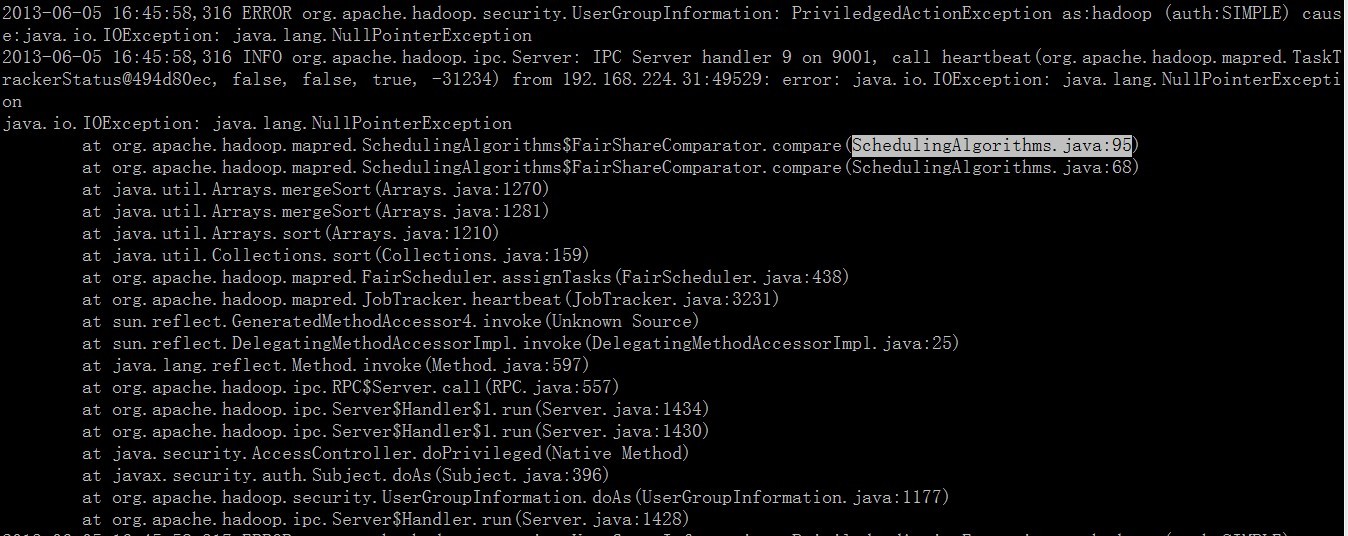
这是官方的一个bug
https://issues.apache.org/jira/browse/MAPREDUCE-3674















 444
444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









