








论文地址: Understanding and Visualizing Data Iteration in Machine Learning
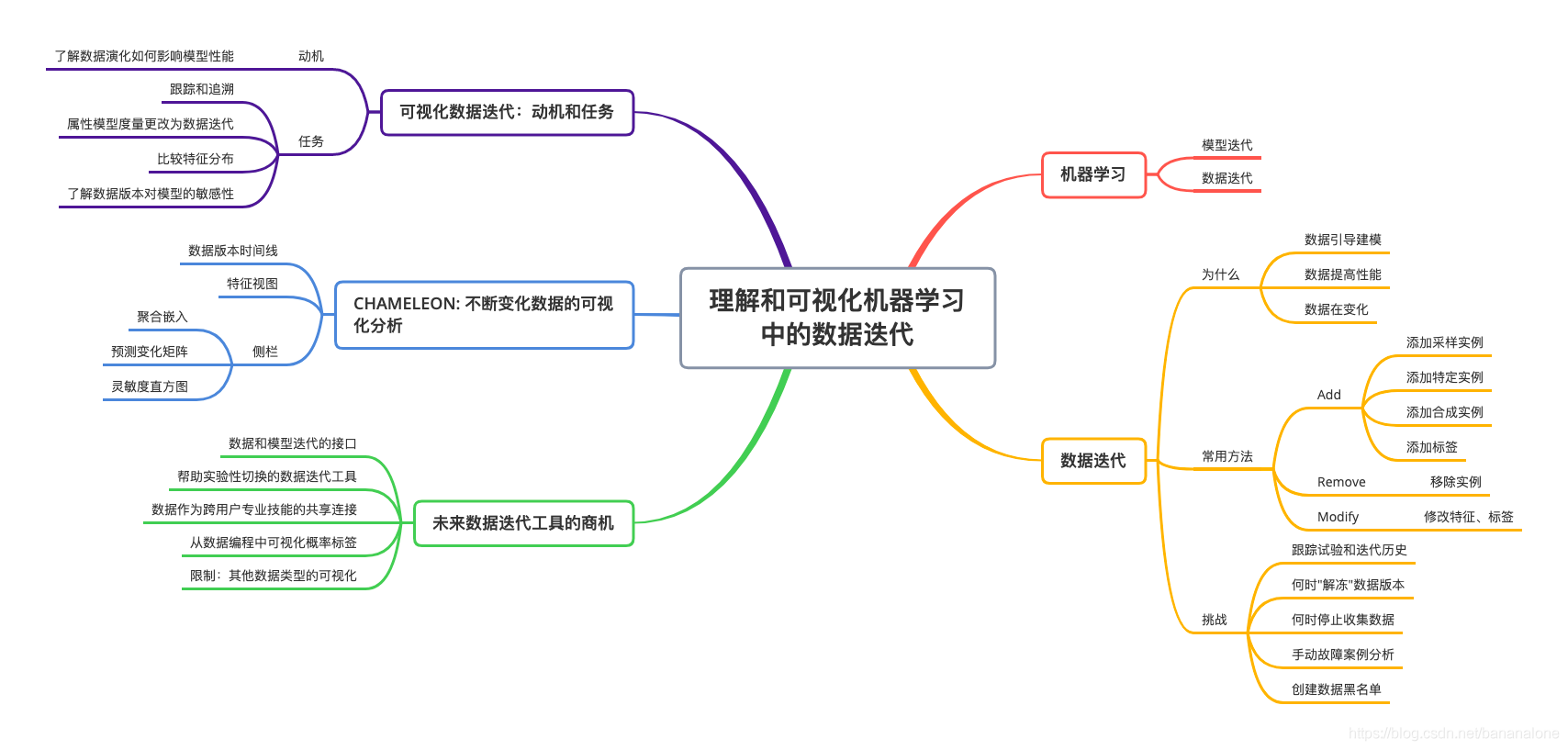
理解和可视化机器学习中的数据迭代
概览
绪论

一个传统的机器学习过程包括模型迭代和数据迭代,ML中有句俗语:垃圾输入,垃圾输出,说明了数据对于模型的重要性,机器学习研究人员经常通过迭代数据来提高模型性能,本文的研究主要集中在数据迭代上。
背景及相关工作
在本文中,我们将数据探索可视化技术扩展到随着模型开发时间的变化而变化的机器学习数据集,包括一种新的可视化方法,用于显示包含模型性能和支持数据版本比较的特征分布。
理解数据迭代
为什么要迭代数据
- 数据引导建模
- 数据提高性能
- 世界在变,数据也在变
数据迭代常用方法
- Add
- 添加采样实例
- 添加特定实例
- 添加合成实例
- 添加标签
- Remove
- 移除实例
- Modify
- 修改特征、标签
数据迭代的挑战
- 跟踪试验和迭代历史
- 何时"解冻"数据版本
- 何时停止收集数据
- 手动故障案例分析
- 创建数据黑名单
可视化数据迭代:动机和任务
动机:用交互式可视化来了解数据演化如何影响模型性能
任务:
- 跟踪和追溯数据版本上的数据迭代和模型度量
- 属性模型度量更改为数据迭代
- 通过训练、测试分割,性能(例如,正确的v.错误的预测)和数据版本(C2、C3、C5)来比较特征分布
- 了解数据版本对模型的敏感性
CHAMELEON: 不断变化数据的可视化分析
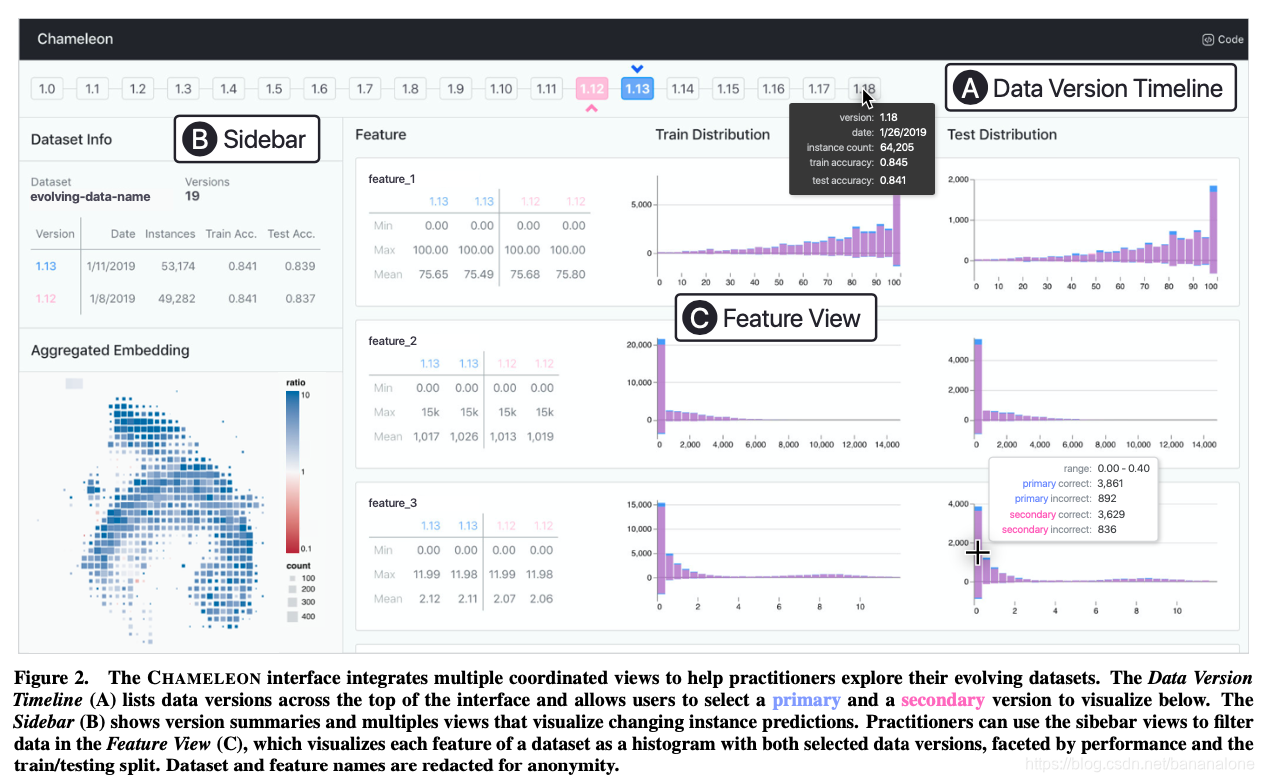
- 数据版本时间线:随时间变化的数据迭代
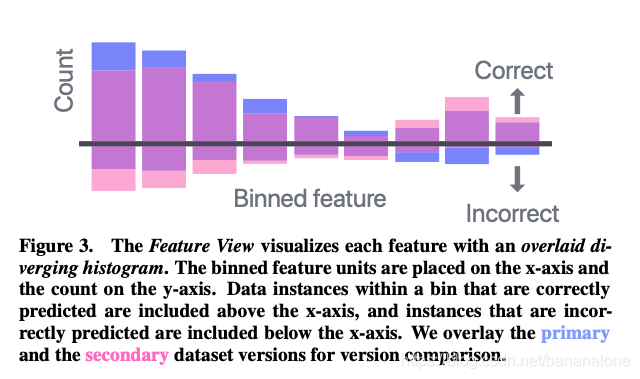
- 特征视图:可视化演化分布
- 侧栏:可视化演化实例预测

A. 聚合嵌入:通过数据降维输出的离散化摘要图显示主数据版本,此图为用户提供了数据集的概述,对于发现类似实例的潜在集群非常有用
B. 预测变化矩阵:显示了两个版本中存在的实例子集,并通过它们的预测正确性和版本对它们进行了划分
C. 灵敏度直方图:显示了数据实例对所选版本范围内版本的预测敏感度

未来数据迭代工具的商机
- 数据和模型迭代的接口
- 帮助实验性切换的数据迭代工具
- 数据作为跨用户专业技能的共享连接
- 从数据编程中可视化概率标签
- 限制:其他数据类型的可视化














 1006
1006











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









