







本文在参考http://blog.csdn.net/ch_liu23/article/details/53558549的博客下,对其博客根据自己的要求做了一定的修改。
注意filename中文件的文件名名没有后缀,因此需要统一加上后缀。只需一段命令即可
在对应目录下执行即可,这样就可以把后缀添上。这样就做按照VOC做好了我们的数据集。
另外也可根据需要修改learning_rate、max_batches等参数。修改好了cfg文件之后,就需要修改两个文件,首先是data文件下的voc.names。打开voc.names文件可以看到有20类的名称,本例中只有一类,检测人,因此将原来所有内容清空,仅写上person并保存。名字仍然用这个名字,如果喜欢用其他名字则请按一开始制作自己数据集的时候的名字来修改。
修改后保存,接下来就可以训练了。
如果一次训练时间太长,可以用中间自动保存的模型继续训练,中间自动保存模型,默认文件夹不改变的情况下在backup里面,训练命令为
不过我没试成功,加上这个模型直接就除了final,不知道啥情况。当然也可以用自己训练的模型做参数初始化,万一训练的时候被人终端了,可以再用训练好的模型接上去接着训练。
YOLO相关可看主页Darknet,有相关代码和使用方法。由于之前做自己的数据训练过程中出现各种问题,参照了各种博客才跑通,现在记录下以防后面忘记,也方便自己总结一下。
YOLO本身使用的是VOC的数据集,所以可以按照VOC数据集的架构来构建自己的数据集。
1.构建VOC数据集
1.准备数据
首先准备好自己的数据集,最好固定格式,此处以VOC为例,采用jpg格式的图像,在名字上最好使用像VOC一样类似I000001.jpg、I000002.jpg这样。可参照下面示例代码
读取某文件夹下的所有图像然后统一命名,用了opencv所以顺便还可以改格式。
- // Getfile.cpp : 重命名文件夹内的所有图像并写入txt,同时也可通过重写图像修改格式
- //配用Opencv2.4.10
- #include "stdafx.h"
- #include <stdio.h>
- #include <string.h>
- #include<io.h>
- #include <opencv2\opencv.hpp>
- #define IMGNUM 20000 //图片所在文件夹中图片的最大数量
- char img_files[IMGNUM][1000];
- using namespace cv;
- int getFiles(char *path)
- {
- int num_of_img = 0;
- long hFile = 0;
- struct _finddata_t fileinfo;
- char p[700] = { 0 };
- strcpy(p, path);
- strcat(p, "\\*");
- if ((hFile = _findfirst(p, &fileinfo)) != -1)
- {
- do
- {
- if ((fileinfo.attrib & _A_SUBDIR))
- {
- if (strcmp(fileinfo.name, ".") != 0 && strcmp(fileinfo.name, "..") != 0)
- continue;
- }
- else
- {
- strcpy(img_files[num_of_img], path);
- strcat(img_files[num_of_img], "\\");
- strcat(img_files[num_of_img++], fileinfo.name);
- }
- } while (_findnext(hFile, &fileinfo) == 0);
- _findclose(hFile);
- }
- return num_of_img;
- }
- int main()
- {
- char path[] = "SrcImage"; //source image
- char dstpath[] = "DstImage"; //destination image
- int num = getFiles(path);
- int i;
- char order[1000];
- FILE *fp = fopen("train.txt", "w");
- for (i = 0; i<num; ++i)
- {
- printf("%s\n", img_files[i]);
- IplImage *pSrc = cvLoadImage(img_files[i]);
- sprintf(order, "DstImage\\I%05d.png", i);
- fprintf(fp, "I%05d\n", i);
- cvSaveImage(order, pSrc);
- printf("Saving %s!\n", order);
- cvReleaseImage(&pSrc);
- }
- fclose(fp);
- return 0;
- }
准备好了自己的图像后,需要按VOC数据集的结构放置图像文件。VOC的结构如下
- --VOCdevkit
- --Annotations
- --ImageSets
- --Main
- --JPEGImages
这里面用到的文件夹是
Annotation、ImageSets和JPEGImages。其中文件夹
Annotation中主要存放xml文件,每一个xml对应一张图像,并且每个xml中存放的是标记的各个目标的位置和类别信息,命名通常与对应的原始图像一样;在ImageSets文件夹下的Main文件夹,这里面存放文本文件,通常为train.txt、test.txt等,该文本文件里面的内容是需要用来训练或测试的图像的名字(无后缀无路径);JPEGImages文件夹中放我们已按统一规则命名好的原始图像。
因此,首先
1.新建文件夹VOCdevkit(可以用其他命名)
2.在VOCdevkit文件夹下新建三个文件夹
Annotation、ImageSets和JPEGImages,并把准备好的自己的原始图像放在JPEGImages文件夹下
3.在ImageSets文件夹中,新建空文件夹Main,然后把写了训练或测试的图像的名字的文本拷到Main文件夹下,这里只做demo之用,为了方便,把所
有图像用来训练,在Main文件夹下只有train.txt文件。上面的代码运行后会生成该文件,copy进去即可。
2.标记图像目标区域
因为做的是目标检测,所以接下来需要标记原始图像中的目标区域。标记工具网上有很多,这里用
labelImg,建议安装py2-qt4版本, 相关用法也有说明,基本就是框住目标区域然后双击类别,标记完整张图像后点击保存即可。操作界面如下:
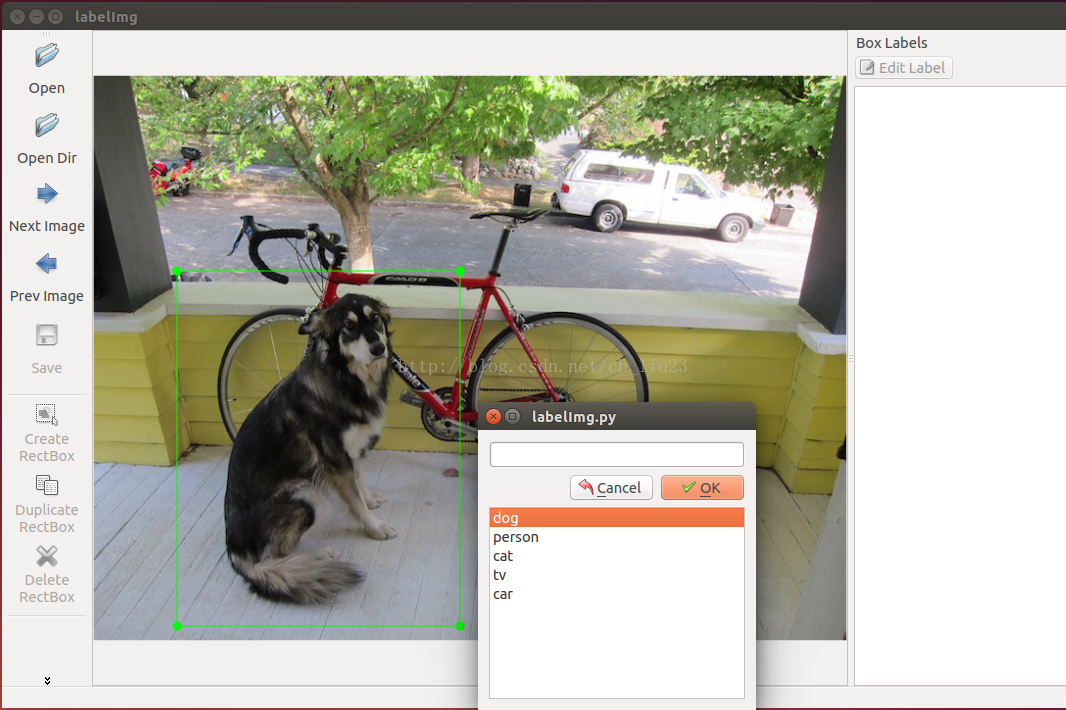
通常save之后会将标记的信息保存在xml文件,其名字通常与对应的原始图像一样(每个xml里面的内容为下图,xml生成过程中,master版本的好像要出错,生成的xml文件,第10行和第11行会为0,安装py2-qt4版本后,在标记过程中,还是查看下xml文件看下第10和11行是否非0)。
通常save之后会将标记的信息保存在xml文件,其名字通常与对应的原始图像一样(每个xml里面的内容为下图,xml生成过程中,master版本的好像要出错,生成的xml文件,第10行和第11行会为0,安装py2-qt4版本后,在标记过程中,还是查看下xml文件看下第10和11行是否非0)。
- <annotation>
<folder>Inria</folder>
<filename>I00000.png</filename>
<path>
/home/syoung/darknet/scripts/VOCdevkit/Inria/I00000.png
</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>818</width>
<height>976</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>person</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>41</xmin>
<ymin>325</ymin>
<xmax>212</xmax>
<ymax>718</ymax>
</bndbox>
</object>
- find -name '*.xml' |xargs perl -pi -e 's|</filename>|.png</filename>|g'
2.用YOLOv2训练
1.生成相关文件
首先需要修改voc_label.py中的代码,这里主要修改数据集名,以及类别信息,我所有样本用来训练,没有val或test,只检测人,只有一类
目标,因此按如下设置
- import xml.etree.ElementTree as ET
- import pickle
- import os
- from os import listdir, getcwd
- from os.path import join
- #sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
- #classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
- sets=[ 'train' ]
- classes = [ "person"]
- def convert(size, box):
- dw = 1./size[0]
- dh = 1./size[1]
- x = (box[0] + box[1])/2.0
- y = (box[2] + box[3])/2.0
- w = box[1] - box[0]
- h = box[3] - box[2]
- x = x*dw
- w = w*dw
- y = y*dh
- h = h*dh
- return (x,y,w,h)
- def convert_annotation(year, image_id):
- in_file = open('VOCdevkit/Annotations/%s.xml'%( image_id)) #(如果使用的不是VOC而是自设置数据集名字,则这里需要修改)
- out_file = open('VOCdevkit/labels/%s.txt'%( image_id), 'w') #(同上)
- tree=ET.parse(in_file)
- root = tree.getroot()
- size = root.find('size')
- w = int(size.find('width').text)
- h = int(size.find('height').text)
- for obj in root.iter('object'):
- difficult = obj.find('difficult').text
- cls = obj.find('name').text
- if cls not in classes or int(difficult) == 1:
- continue
- cls_id = classes.index(cls)
- xmlbox = obj.find('bndbox')
- b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
- bb = convert((w,h), b)
- out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
- wd = getcwd()
- for year, image_set in sets:
- if not os.path.exists('VOCdevkit/labels/'):
- os.makedirs('VOCdevkit/labels/')
- image_ids = open('VOCdevkit/ImageSets/Main/%s.txt'%(image_set)).read().strip().split()
- list_file = open('%s.txt'%(image_set), 'w')
- for image_id in image_ids:
- list_file.write('%s/VOCdevkit/PNGImages/%s.png\n'%(wd, image_id))
- convert_annotation(year, image_id)
- list_file.close()
修改好后在该目录下运行命令:python voc_label.py,之后则在文件夹scripts\VOCdevkit下生成了文件夹lables,将该文件夹下txt文档全部复制到PNGImages下,
同时在/scripts文件夹下生成了train.txt文件,里面包含了所有训练样本的绝对路径。
2.配置文件修改
做好了上述准备,就可以根据不同的网络设置(cfg文件)来训练了。在文件夹cfg中有很多cfg文件,根据自己的需要选择修改cfg。这里以yolo-voc.cfg为例。主要修改参数如下
- .
- .
- .
- [convolutional]
- size=1
- stride=1
- pad=1
- filters=30 //修改最后一层卷积层核参数个数,计算公式是依旧自己数据的类别数filter=num×(classes + coords + 1)=5×(1+4+1)=30
- activation=linear
- [region]
- anchors = 1.08,1.19, 3.42,4.41, 6.63,11.38, 9.42,5.11, 16.62,10.52
- bias_match=1
- classes=1 //类别数,本例为1类
- coords=4
- num=5
- softmax=1
- jitter=.2
- rescore=1
- object_scale=5
- noobject_scale=1
- class_scale=1
- coord_scale=1
- absolute=1
- thresh = .6
- random=1
接着需要修改cfg文件夹中的voc.data文件。也是按自己需求修改:
- classes= 1 //类别数
- train = /home/syoung/darknet/scripts/train.txt //训练样本的绝对路径文件,也就是上文2.1中最后生成的
- names = data/voc.names //上一步修改的voc.names文件
- backup = /home/syoung/darknet/backup/ //指示训练后生成的权重放在哪
3.运行训练
上面完成了就可以命令训练了,可以在官网上找到一些预训练的模型作为参数初始值,也可以直接训练,训练命令为
- $./darknet detector train cfg/voc.data cfg/yolo-voc.cfg
- $./darknet detector train cfg/voc.data cfg/yolo-voc.cfg yolo-voc_3000.weights
训练过程中会根据迭代次数保存训练的权重模型,然后就可以拿来测试图像或者视频了,图像测试命令:(将图像放于data文件夹下)
./darknet detect cfg/yolo-voc.cfg cfg/yolo-voc_3000.weights data/images.jpg
视频测试命令:(将视频放于data文件夹下)
./darknet detector demo cfg/yolo-voc.cfg yolo-voc_3000.weights data/video.avi
训练时间较长,测试了训练模型3000的检测效果,效果还很渣,可能也与数据集制作的时候有一定关系。














 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









