







Paperreading之一 目标检测专用backbone—DetNet
1.前言:一个专门用于目标检测的backbone—DetNet,目前大多数用于目标检测的backbone都是使用在ImageNet上预训练的网络,比如常用的vgg,resnet系列等等,但是这些网络都是为图像分类而设计的,把这些网络用于目标检测领域,通常不能完美贴合,会或多或少的增加一些层。这样会有两个问题:
- 不能很好的利用ImageNet上预训练的模型,我们知道,目前来说预训练对于大部分算法的精度有很大影响
- 图像分类问题只关注分类,不用关注物体定位,对空间信息不关注,只关注足够大的感受野,但是目标检测领域同时很关注空间信息。如果下采样过多,会导致最后的featuremap很小,小目标很容易漏掉。
2.构建DetNet
针对以上两个问题,face++的研究员提出了专门针对目标检测领域的backbone。设计出一个网络尽量能完整作为目标检测网络的backbone,并且保证足够的感受野和一定的feature map。作者是在FPN基础上进行一些设计和改进的。
对于第一个问题,先看下FPN结构。
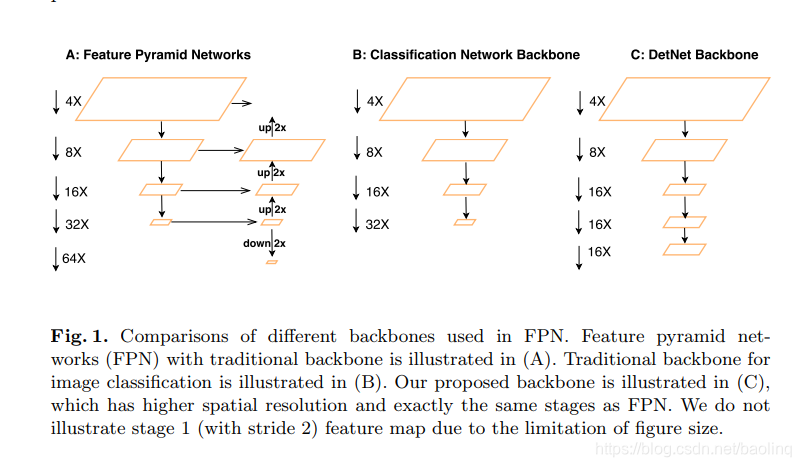
上图A就是FPN结构图,少画了一个stage,上面全部都是从4x开始,表示步长为4,也就是该层的feature map是原图的1/4。假设原始fpn的backbone是resnet50,原生resnet(上图B)最后一个stage输出是32x(也就是经过5次下采样),在fpn中增加了一层P6,做了一个下采样。这样就会有前言中的两个问题,增加层不能使用ImageNet预训练模型初始化,过多的下采样导致feature map太小,容易miss掉小物体。
作者把resnet改成图C,这样就没有额外增加层P6,使得在ImageNet上预训练的模型能完美用来初始化。
对于第二个问题,细心的朋友可能已经发现上图C最后三层的大小是相同的,作者为了不减小feature map,保证对小目标更好的检测。使用了带孔卷积(dilated convolution),dilated conv可以在增大感受野的同时而不减小feature map的大小。另一个就是后面三层不改变channel数,不然feature map不减半,channel数翻倍,会导致参数量暴涨,另外可能channel数没有那么重要,影响不大。
Dilated conv示意图

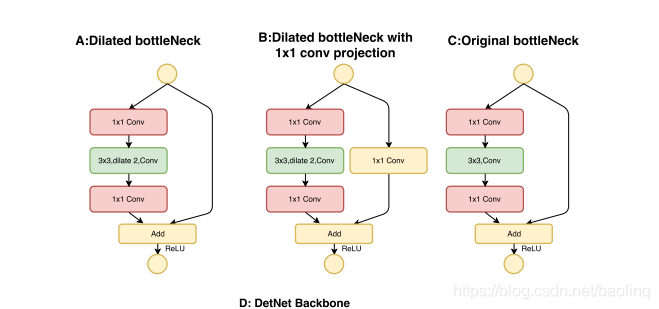
与原生的resnet相比,改动也很小,见上图,把中间的conv换为dilated conv即可。
完整结构图:
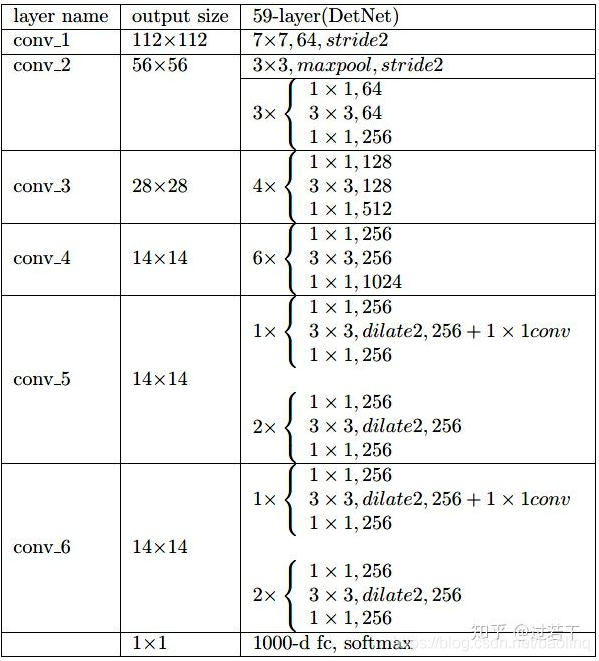
图来自https://zhuanlan.zhihu.com/p/38099969。
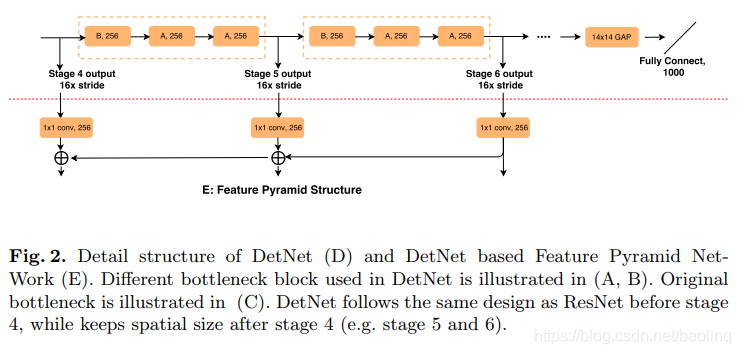
DetNet的细节归纳为三点:
- 本文在 backbone 中引入额外的 stage,比如 P6,它稍后用于物体检测,正如在 FPN 中一样。同时,在 stage 4 之后把空间分辨率固定为 16x 下采样。
- 由于空间尺寸在 stage 4 之后是固定的,为引入一个新 stage,本文在每个 stage 开始使用一个带有 1x1 卷积投影(的 dilated bottleneck。
- 借助 dilated bottleneck 作为基础模块以加大感受野。由于 dilated conv 依然耗时,DetNet stage 5,6 与 stage 4 通道数量相同(bottleneck 有 256 个输入通道),这不同于传统的 backbone 设计,其在新的 stage 需要双倍的通道
3.开始训练(分类和检测)
解决了上面的两个问题,就可以构建完整DetNet了,先在ImageNet上训练一波。效果一般,毕竟不是针对分类问题设计的。
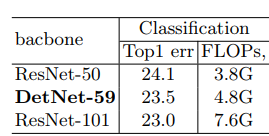
那么怎么把DetNet用于目标检测里面呢?把它作为fpn的backbone为例。和之前的resnet几乎没差,只是不用增加额外层,还是做上采样与上层融合
4.结果对比
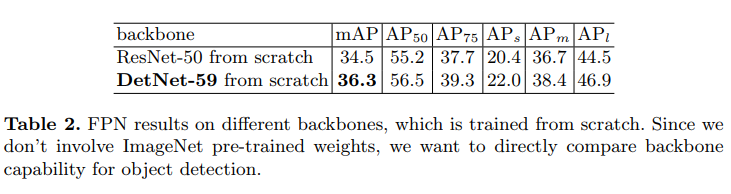
最后看下以DetNet59作为backbone的FPN在COCO上的结果吧,文章的实验做的还是比较不错的,多方面对比。
(1)都不使用ImageNet预训练模型初始化,从头开始训练。
(2)使用ImageNet预训练模型初始化,可以对比上图预训练的威力很大。但同时DetNet的提升更多,说明DetNet作为backbone,因为没有增加额外层,预训练带来的收益更大。
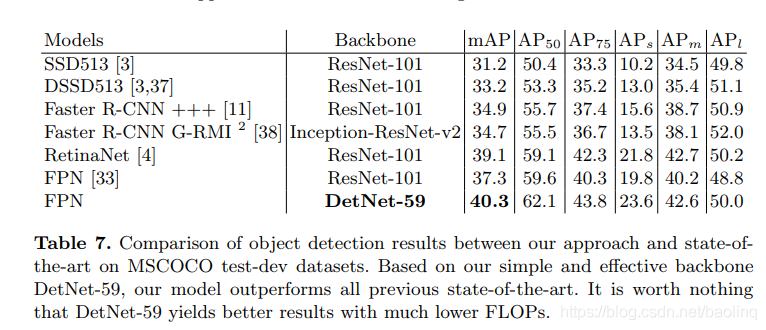
(3)与当前sota结果对比
(4)详细对比不同scales物体在不同精度下差异
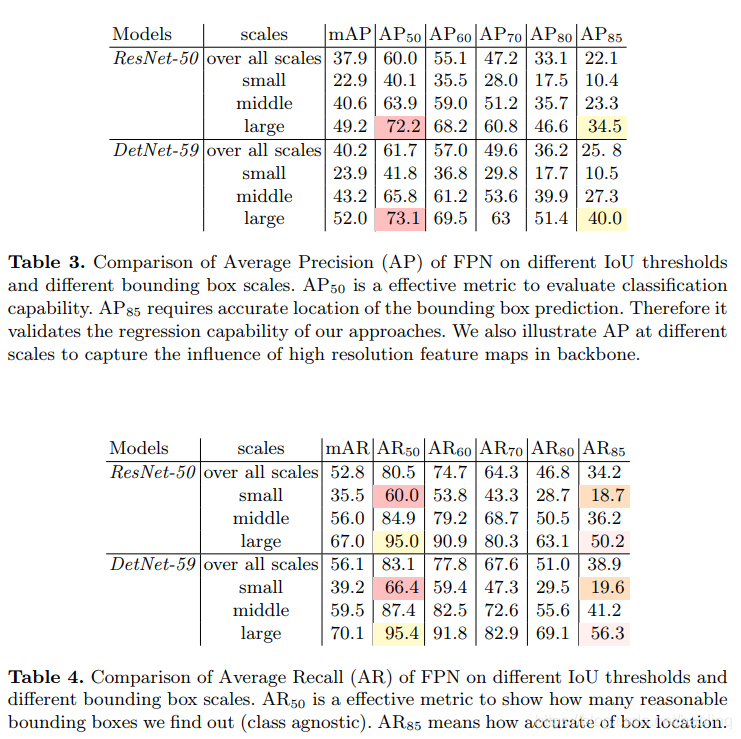
在large物体方面,AP85提升明显,在精度要求很高时,由于DetNet有较大的feature map,保留更多的空间信息,定位更好。在Ap50时,定位精度不高,优势不明显。
在small物体方面,AR50提升明显,DetNet更不容易漏掉小物体。但是在AR85时,提升不明显,说明小目标的精确定位还是更多浅层信息,但是DetNet浅层没有改变相比resnet。
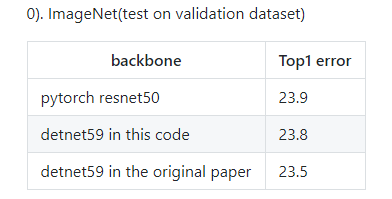
5.关于代码实现
可以参考浙大大佬的github。复现的是pytorch版本,代码很好读,效果还不错。
(https://github.com/guoruoqian/DetNet_pytorch)
最后总结:
- 论文贡献:提出了一种专门用于目标检测的backbone。发现目前的backbone的一些问题。效果做到sota水平。
- 该论文的想法与Dilated Residual Networks(2017年CVPR)很相似,都是在resnet上加入dilated conv
- 论文更多的对比都是与resnet50对比,但是DetNet59的参数量和计算量都是更多的,虽然在coco上结果也是超过了resnet101。
- 论文比较偏工程,效果确实有提升,face++里面的人工程能力确实很强,复现出来的论文经常比原始论文的结果高出好几个点,创新性没有惊艳。
参考:
[1] https://arxiv.org/pdf/1804.06215.pdf
[2] https://zhuanlan.zhihu.com/p/38099969
[3] https://github.com/guoruoqian/DetNet_pytorch














 5234
5234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









