







转自:http://cleexiang.github.io/blog/2013/09/11/concurrent-programming-1-yi/
并发的概念定义为同一时间运行多个任务。一般表现为在单核CPU中共享时间片的方式,或者真正的并行在多核CPU中。
OSX和iOS提供了多个能够并发编程的API。每个API都有不同的功能和局限性,使其适用于不同的任务。他们居于不同的抽象级别。
并发编程是一个带着许多复杂问题和陷阱的非常困难的主题,而且在使用像GCD或者NSOperationQueue这样的API的时候很容易忽略。这篇文章首先概述了在OSX和iOS中不同的并发API,然后根据独立于特定的API,深入到并发编程的挑战中去。
基于OSX和iOS的并发编程
苹果的移动和桌面操作系统为并发编程提供了相同的API,在这边文章里我们将要看看pthread,NSThread,GCD,NSOperationQueue和NSRunLoop。技术上,因为run loops不能真正的并行,所以他们是其中比较奇怪的一个。但是因为他们跟主题联系紧密以至于值得走近一看。
我们将以低级APIs开始,将我们的方法向高级的APIs靠近。我们选择这个路线是因为高级APIs是建立在低级APIs的基础之上的。然后,当为使用案例选择API时,应该以相反的顺序考虑他们:为了让你的并发模型非常简单,选择高级抽象的API来完成工作。如果你想知道为什么我坚持推荐高级抽象的API和非常简单的并发代码,你应该读一下文章的第二部分,challenges of concurrent programming,,还有Peter Steinberger’s thread safety article。
Threads
线程是能被操作系统调度程序独立调度的进程的子单元,几乎所有的并发APIs都构建于线程之上,高级选项-对于GCD和操作队列来说都是事实。
多个线程可以同时执行与单核CPU中(或者至少被视为同一时间)。操作系统为每个线程分配计算时间的小片段,以至于对于用户来说好像多个任务在同时执行。如果多核CPU是可用的,那时多线程真正的可以并行的运行,因此为确定的工作量减轻了总的时间。
你能在Instruments中使用CPU strategy view获悉正执行与多核CPU上的你的代码或者框架代码情况怎么样。
需要记住的是你无法控制你代码被调度的时间和地点,还有为了轮到其他任务执行,需要什么时间,多长时间暂停其执行。这种类型的线程调度是非常强大的技术。然而,它同时也带来了巨大的复杂性,我们稍后将进行研究。
将复杂性放一边,你也可以使用POSIX线程API,或者用NSThread创建你自己的线程,用Objective-c包装的。这里有一个用pthread在一百万个数的集合里面找出最小数和最大数的例子。它生成了并行运行的4个线程。这个例子里明显的看出你为什么不想直接用pthread线程。
struct threadInfo {
uint32_t * inputValues;
size_t count;
};
struct threadResult {
uint32_t min;
uint32_t max;
};
void * findMinAndMax(void *arg)
{
struct threadInfo const * const info = (struct threadInfo *)arg;
uint32_t min = UINT32_MAX;
unit32_t max = 0;
for
}
int main(int argc, char *argv[])
{
size_t const count = 100000;
uint32_t inputValues[count];
for (size_t i = 0 ; i < count ; ++i) {
inputValues[i] = arc4random();
}
size_t const threadCount = 4;
pthread_t tid[threadCount];
for (size_t i = 0; i < threadCount; ++i) {
struct threadInfo *const info = (struct threadInfo *)malloc(sizeof(*info));
size_t offset = (count / threadCount) * i;
info->inputValues = inputValues + offset;
info->count = MIN(count-offset, count / threadCount);
int err = pthread_create(tid + i, NULL, &findMinAndMax, info);
NSCAssert(err == 0, @"pthread_create() failed: %d", err);
}
struct threadResult *results[threadCount];
for (size_t i = 0; i < threadCount; ++i) {
int err = pthread_join(tid[i], (void **)&(results[i]));
NSCAssert(err == 0, @"pthread_join() failed: %d", err);
}
uint32_t min = UINT32_MAX;
uint32_t max = 0;
for (size_t i = 0; i < threadCount; ++i) {
min = MIN(min, results[i]->min);
max = MAX(max, results[i]->max);
free(results[i]);
results[i] = NULL;
}
NSLog(@"min = %u", min);
NSLog(@"max = %u", max);
return 0;
}
NSThread是一个基于pthreads的Objective-c封装。这使得代码看起来与 Cocoa环境更相似。例如,你能够定义一个线程作为NSThread的子类,它封装了你想要运行于后台的代码。对于之前的例子,我们像这样可以定义一个NSthread子类:
@interface FindMinMaxThread : NSThread
@property (nonatomic) NSUInteger min;
@property (nonatomic) NSUInteger max;
- (instancetype)initWithNumbers:(NSArray *)numbers;
@end
@implementation FindMinMaxThread {
NSArray *_numbers;
}
- (instancetype)initWithNumbers:(NSArray *)numbers
{
self = [super init];
if (self) {
_numbers = numbers;
}
return self;
}
- (void)main
{
NSUInteger min;
NSUInteger max;
// process the data
self.min = min;
self.max = max;
}
@end
为了启动新线程,我们需要创建新的线程对象并且调用它们的开始方法:
NSSet *threads = [NSMutableSet set];
NSUInteger numberCount = self.numbers.count;
NSUInteger threadCount = 4;
for (NSUInteger i = 0; i < threadCount; i++) {
NSUInteger offset = (count / threadCount) * i;
NSUInteger count = MIN(numberCount - offset, numberCount / threadCount);
NSRange range = NSMakeRange(offset, count);
NSArray *subset = [self.numbers subarrayWithRange:range];
FindMinMaxThread *thread = [[FindMinMaxThread alloc] initWithNumbers:subset];
[threads addObject:thread];
[thread start];
}
为了检测我们新产生的线程在计算出结果之前什么时候完成,现在我们可以观察线程的isFinished属性。不过我们将这个练习留给那些感兴趣的读者。主要的一点是,不管直接用pthread还是NSThread APIs,都是相对笨拙的并且也不符合我们心智模型的编码。
那样的问题是直接使用线程是活动线程的数量成指数级增长如果你的代码和底层框架代码派生它们自己的线程。在大型项目里这实际上是一个很普遍的问题。例如,如果你利用8个CPU内核创建8个线程,并且你在这些线程调用的框架代码中做了同样的事情(因为它不知道你已经创建的线程),你可以很快结束几十个甚至几百个线程。每个部分的代码涉及对本身负责;然而最终的结果是有问题的。线程不是自由而来的,每个线程跟内存和内核资源关联。
接下来,我们将讨论两个基于队列的并发APIs:GCD和Operation Queues。他们通过集中管理一个大家共同使用的线程池来缓解这个问题。
Grand Central Dispatch
为了让开发者更简单的利用在设备中愈来愈多的CPU多核,Grand Central Dispatch (GCD)在OS X 10.6和iOS4中被引入。我们将在文章article about low-level concurrency APIs.中细说GCD。
使用GCD你再也不用直接和线程打交道。取而代之的是你往队列里面添加块代码,并且GCD在后台管理一个线程池。GCD决定你的代码块执行于哪个特殊的线程上,并且按照可用的系统资源来管理这些线程。这样缓解了太多线程被创建的问题,因为线程被集中管理并且脱离了应用程序开发人员。
另外GCD重要的改变是开发者考虑在队列中的工作项而不是线程。这种新的并发模型更易于被使用。
GCD暴露了5个不同的队列:运行在主线程上的main queue,三个拥有不同优先级的后台队列,和一个甚至更低级别的被I/O限制的后台队列。此外,你可以创建自定义的可以串行或者并行的队列。自定义队列非常强大,你在他们中调度的所有block都将被放入系统的全局队列和线程池中。 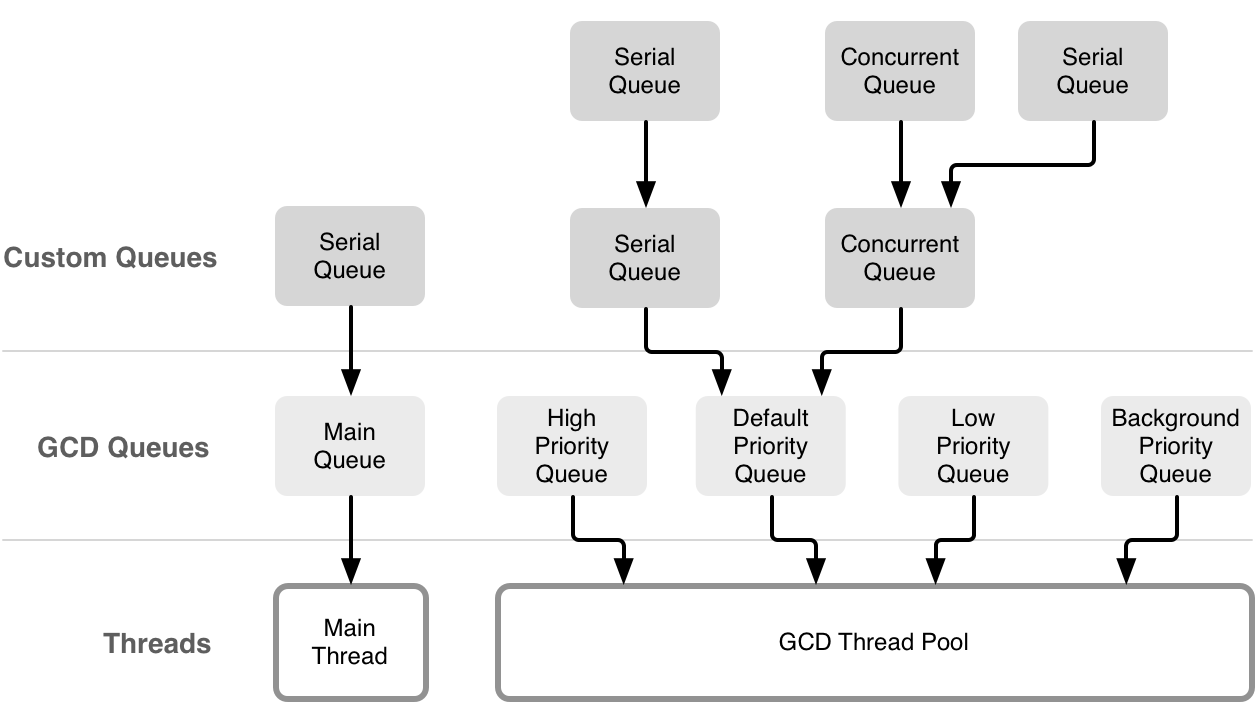
首先利用几个不同优先级的队列听起来很简单。然后,我们强烈推荐你在几乎所有的情况下使用默认优先级的队列。如果在不同优先级队列中的调度任务访问了共享的资源,将很快的造成意外情况。这可能会导致你的整个程序停滞不前,因为一些低优先级的任务正阻塞高优先级任务的执行。你可以了解到关于这种现象更多的信息,称为优先级反转。
虽然GCD是底层C API,但是它很易于使用。这使得当分配block到GCD队列的时候很容易忘记仍然存在于并发编程的所有警告和陷阱。为了能意识到潜在的问题,请一定要阅读下面的challenges of concurrent programming。此外,在这个问题上有很好的包括很多深入解释和有价值的提示的文章walkthrough of the GCD API。
Operation Queues
Operation queues是Cocoa框架中被GCD暴露出来的抽象队列模型。虽然GCD提供了更多的底层控制,但是Operation Queues在它的基础上实现了几个简单的特性,这使得它对于开发者来说成为了更好,更安全的选择。
NSOperationQueue类有两种不同类型的队列:main queue和custom queues。main queue运行在主线程上,custom queues运行于后台线程。这些任务作为NSOperation的子类被这些队列处理。
你可以通过两种方法定义自己的操作:复写main方法或者start方法。前者做起来很简单,但是缺少灵活性。作为回报,像isExecuting和isFinished这样的属性已经为你管理好了,简单的认为当main方法返回后operation完成。
@implementation YourOperation
- (void)main
{
// do your work here ...
}
@end
如果你想要控制更多并且在operation里面执行一个异步的任务,你可以复写start方法:
@implementation YourOperation
- (void)start
{
self.isExecuting = YES;
self.isFinished = NO;
// start your work, which calls finished once it's done ...
}
- (void)finished
{
self.isExecuting = NO;
self.isFinished = YES;
}
@end
注意在这种情况下,你必须手动管理operation的状态,为了operation queue能够识别这样一个状态,状态属性值必须实现KVO-compliant方法。所以确保发送适当的KVO方法以防你不通过默认的访问器方法设置他们。
为了利用被operation queues暴露出来的取消属性,对于长时间运行的operations,你应该定期的检查isCancelled属性:
- (void)main
{
while (notDone && !self.isCancelled) {
// do your processing
}
}
一旦你定义好了你的operation类,就可以很简单的往queue里面添加operation:
NSOperationQueue *queue = [[NSOperationQueue alloc] init];
YourOperation *operation = [[YourOperation alloc] init];
[queue addOperation:operation];
另外,你可以添加blocks到operation queues,如果你想在main queue中调度一次性任务,便很简单:
[[NSOperationQueue mainQueue] addOperationWithBlock:^{
// do something...
}];
这是往队列里面调度任务的一种非常方便的方法,自定义NSOperation的子类在调试的时候非常有用。如果你复写operation的description的方法,你可以很简单的标识当前在一个确定的队列里被调度的所有操作。
除开对operations或者blocks基本的调度功能,operation queues还提供通过GCD取得一些不一般的权利。例如,你可以使用maxConcurrentOperationCount属性简单的控制一个队列里可以并发执行的操作的数目。设置为1将给你一个串行的队列,非常有利于分离。
另外比较方便的功能是在一个队列里按照操作的优先级对他们进行排序。这和GCD对立的优先级不一样。它只单独的影响在一个队列里所有操作被调度执行的顺序。如果你需要控制除这5个标准优先级之外的执行顺序,你可以像这样指定操作之间的依赖关系
[intermediateOperation addDependency:operation1];
[intermediateOperation addDependency:operation2];
[finishedOperation addDependency:intermediateOperation];
这段代码保证operation1和operation2将在intermediateOperation之前执行,并且它将在finishedOperation之前执行。操作依赖对于指定良好的执行顺序来说是非常强大的机制。这允许您创建诸如操作组,它在依赖的操作或者另外的并发队列里的串行操作之前能够保证执行。
通过抽象的本质,相对于GCD API来说operation queues会有一些性能的影响。然而,在几乎所有情况下,这个影响可以忽略不计,operation queues是可以被选择的工具。
Run Loops
Run Loops不是一个像GCD或者operation queues那样有并发机制的技术,因为他们不支持并行执行任务。然而,run loops使主要调度/操作队列上执行的任务配合的很适当并且提供了异步执行代码的机制。
比起operation queues或者GCD,Run Loops可以更易于使用,因为你不需要并发的复杂性而仍然可以异步的执行任务。
一个Run Loop常常限制为一个特定的线程。在每个Cocoa和CocoaTouch应用中,主要的Run Loop作为中心角色联系着主线程,因为它掌握着UI事件,定时器和其他内核事件。无论什么时候你调度定时器,用NSURLConnection,或者调用performSelector:withObject:afterDelay:方法,为了执行这些异步任务,run loop在幕后被使用。
无论何时使用依赖于run loop的方法,重要的是要记住,run loops可以以不同的模式运行。每种模式定义了一组相互作用的事件。这是一种非常聪明的方法,可以暂时在main run loop中将某一特定任务暂时优先于其他执行。
一个典型的例子就是iOS里面的滚动。当你滚动的时候,run loop不以默认模式运行,因此它不会做出反应,例如,你之前设定好的定时器。一旦滚动停止,run loop返回到默认模式事件已经被排队执行。如果你想要定时器在滚动的时候被激活,你需要以NSRunLoopCommonModes的模式将它添加到run loop中去。
主线程通常包括设置和运行main run loop。其他线程虽然没有默认配置run loop。你也可以为其他线程设置一个run loop,但是你很少需要去做这种事。多数时候更易于使用main run loop。如果你需要做繁重的任务而不想执行在主线程中,你仍可以在main run loop调用完你的代码之后,分配它到其他队列里。Chris在他的文章中有一些这种模式很好的例子common background practices。
如果你真的需要在其他的线程上配置一个run loop,别忘了给它添加最少一个输入源。如果一个run loop没有配置输入源,每次试图运行它都将立即退出。
并发编程的挑战
写并发的程序会遇到很多陷阱。随着你做越来越多基础的事情,监督多个相互影响的并行任务的所有不同的状态变成一件很困难的事情。问题以不确定的方式出现,这使得调试并发代码更困难。
这里有一个说明并发程序不可预料的行为的例子:1995年,美国宇航局发送火星探路器。在着陆到我们邻近的红色行星不久之后,任务几乎戛然而止。“勇气者”火星探测器不断重启原因不明—遭遇这种现象被称为优先级反转,当一个低优先级的线程一直阻塞一个高优先级的线程。我们将在下面详细的研究这个特殊的问题。但是这个例子可以说明及时有大量的资源和工程人才可用,并发仍可以以很多方式咬伤你。
共享资源
许多并发相关弊害的根源就是多个线程对共享资源的访问。一个资源可以是一个属性或者一个对象,一般是内存,网络设备,一个文件等等。任何在多个线程之间共享的东西都是潜在的冲突点,你必须采取安全措施来阻止这种冲突。
为了说明这个问题,让我们看一个以整形形式作为资源的简单例子,用它作为计数器。我们有两个并行运行的现成,A和B,都试图在同一时间增加计数器。问题是,无论你用C或者Objective-C表述出来几乎都不是一个机器指令。为了增加我们的计数器,当前值必须从内存中读取。那时的值已经加1并且最后写回内存中。
试想如果多个线程都同步试图去做这样的事危险可能会发生。例如,线程A和B都从内存中读取计数器的值;假设它是17.线程A让计数器加1并且将结果18写回内存中。在同时,线程B也将计数器加1并在线程A之后把结果18写回内存中,在这个点上数据发生了错误,因为计数器从17增加了两次时候保持在了18。 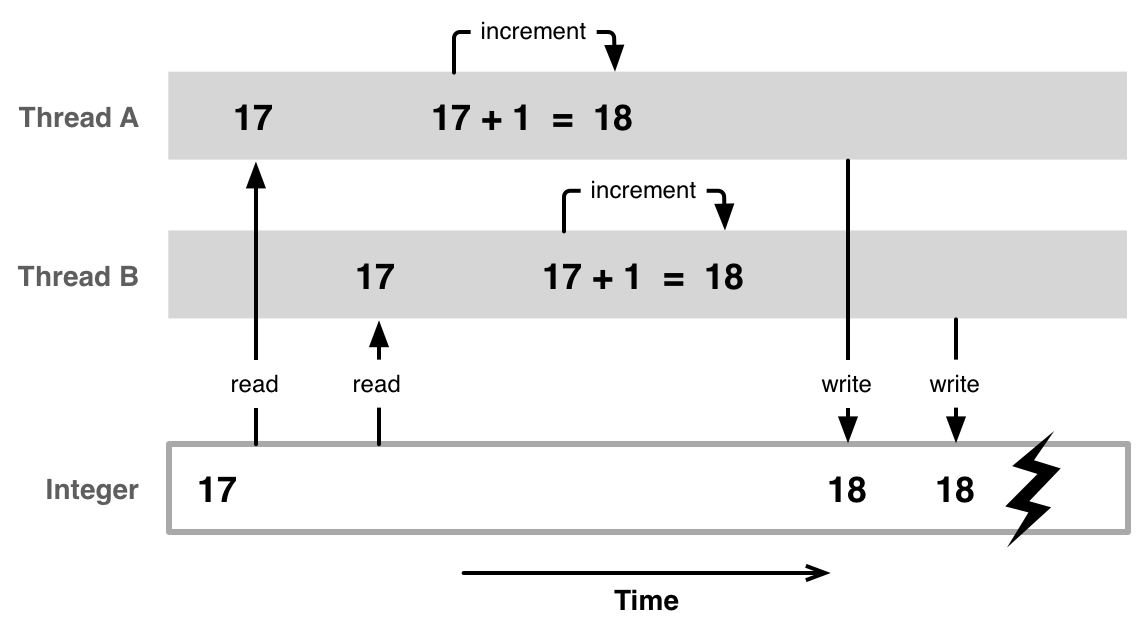
如果在没有确认一个线程开始访问一个资源之前另一个线程已经完成对它的操作,多个线程访问一个共享资源可能会发生的问题叫做race condition。如果你不是简单的改变一个整数而是一个复杂的数据结构,甚至会发生第二个线程尝试从内存中读取它当你写到一半的时候,因此看到一半是新的,一半是旧的或者未初始化的数据。为了阻止这种情况发生,多个线程之间需要以互斥的方式访问共享资源。
事实上,情况比这更复杂,因为现代CPU为了优化的目的改变读和写的顺序(乱序执行)。
互斥
互斥访问意味着同一时间只有一个线程访问某个资源。为了保证这样,每个线程想要访问一个资源之前首先需要获得它的互斥锁。一旦它完成了操作,就释放这个锁,那样其他线程有机会访问它。 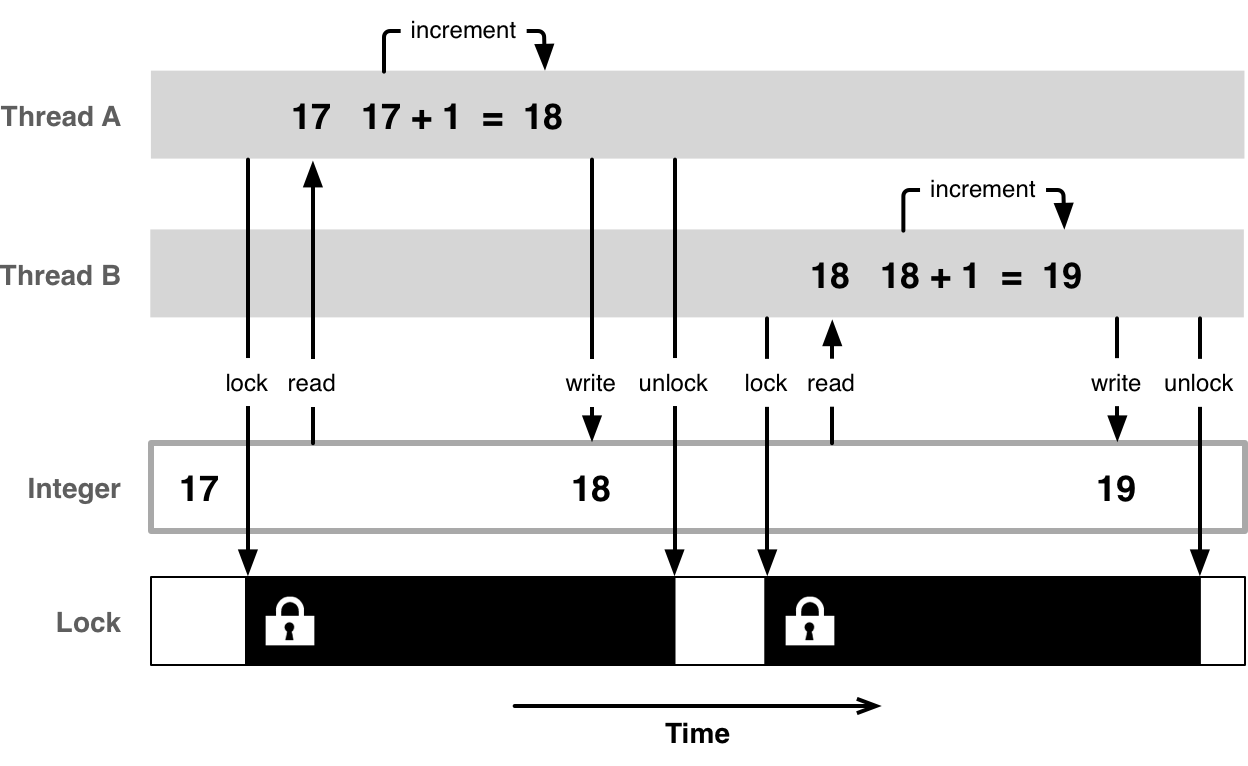
除了确保互斥访问,锁必须处理无序执行造成的问题。如果你不能依赖CPU访问内存的序列定义为你的程序指令,保证互斥访问本身是不够的,为了解决这种CPU优化策略,需要设置内存屏障memory barriers。确保无序执行时正确跨越设置的屏障。
当然互斥锁的实现需要自由的竞争条件。这是一个重要的任务并且需要在现代CPU上使用特定的指令。你可以了解更多关于原子操作的信息在Daniel的文章里low-level concurrency techniques
Objective-C以描述属性为atomic的形式在语言层上对加锁进行了支持。事实上,属性默认就是atomic。声明属性为atomic的结果是每次访问这个属性的时候隐式的加锁/解锁。为了以防万一,它可能诱使你把所有的属性声明为atomic。然后,锁是有代价的。
在一个资源上获取锁通常是有性能的代价的。获得或者释放锁需要自由的竞争条件,这在多核系统中是很重要的。且当获得一个锁的时候,因为一些其他的线程已经持有锁,当前线程可能不得不等待。在这种情况下,这个线程将休眠并且当其他线程放开所之后被通知。所有这些操作是昂贵的和复杂的。
锁有几种不同的类型。在没有竞争时一些锁是恨廉价的,但是在右竞争的时候,性能很差。在同等条件下,其他锁更昂贵,暂时在锁竞争的条件下表现的更好(Lock contention锁竞争的情况是:当一个或者多个线程尝试加锁当它已经被别的线程加锁后)。
这里需要平衡一下:获取或者释放锁需要有开销。因此你要确定你不断的进入和退出临界段critical sections(即获取或者释放锁)。与此同时,如果你为了一大段代码加锁,将遭遇锁竞争造成的风险,其他线程因为他们等待加锁通常不能工作。这不是一个容易解决的问题。
我们经常能看到并发执行的代码,但事实上结果是只有一个线程在某个时间点是活动的,因为为共享的资源设置了锁。预测你的代码将怎样在多核系统上被调度通常是很重要的。你可以使用Instrument工具的CPU strategy view判断是否你有效的使用了可用的CPU内核,从而得到更好的想法。
死锁
互斥锁解决了资源竞争的问题,但是不幸的是他们同时也带来了新的问题:死锁。多个线程等待彼此完成而被卡住无法运行造成了死锁的发生。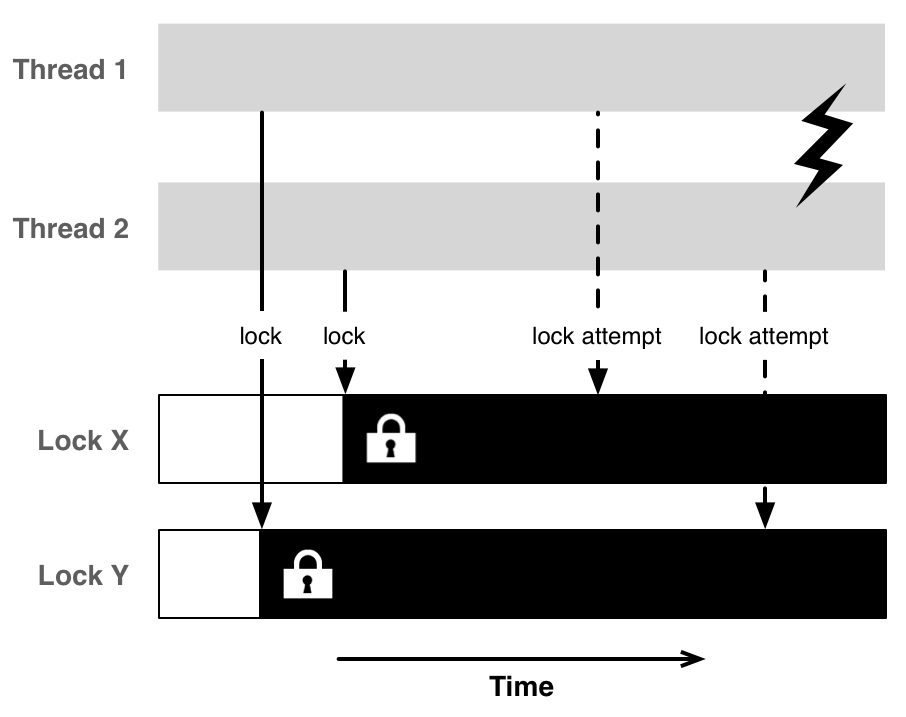
想想下面的示例代码,交换两个变量的值:
void swap(A, B)
{
lock(lockA);
lock(lockB);
int a = A;
int b = B;
A = b;
B = a;
unlock(lockB);
unlock(lockA);
}
大部分时候它能运行良好,但是当两个线程同时调用它呢,用两个相反的值。
swap(X, Y); //thread 1
swap(Y, X); //thread 2
死锁可能造成程序终止。线程1获取了X的锁,线程2获取了Y的锁。现在他们都等候其他的锁,但是他们将永远无法获取。再说,在线程之间共享更多的资源,你将花费更多的锁,造成死锁的风险就越大。这就是为什么我们减少线程间共享的资源,让共享的资源越简单的原因。确认你也读了以下的文章low-level concurrency APIs 关于异步调用
饥饿
当你认为你了解足够多的问题时,拐角处新的问题又出现了。锁定的资源造成了读写问题,限制一个资源只有一个线程访问是非常浪费的。因此只要没有在资源上加写锁,加读锁是可以被允许的。在这种情况下,一个线程正在等待加写锁当此时有更多写锁存在的同时。
为了解决这个问题,比起简单的读写锁,更多聪明的方法显得有必要。例如,给定writers preference或者使用read-copy-update算法。Daniel在low-level concurrency techniques一文中介绍了怎样用GCD实现多读/单写的模式而不会再遭遇饥饿。
优先级反转
我们开始提到了这个部分,以美国宇航局的火星探测器遭遇并发问题的为例。现在我们仔细看看探测器为什么失败,并且为什么我们的应用程序会遇到同样的问题,叫做优先级反转。
优先级反转描述为:一个低优先级的任务阻塞了一个高优先级任务的执行,有效地反转了任务的优先级。由于GCD提供了不同优先级的后台线程,包括I/O队列,所以通过它可以很好的了解到优先级反转的可能性。
当一个高优先级和低优先级的任务分享一个共同的资源时会发生这种问题。当低优先级的任务获得了公共资源的锁时,假定它很快的完成来释放锁,让高优先级的任务在没有明显的延时下继续执行。当高优先级的任务被低优先级的任务阻塞期间,中优先级的任务有机会抢占低优先级的任务的执行,因为中优先级的任务在当前可运行的任务中拥有最高的优先级。在这个时候,中优先级的任务阻碍了低优先级任务释放锁,因此高优先级的任务一直在等待。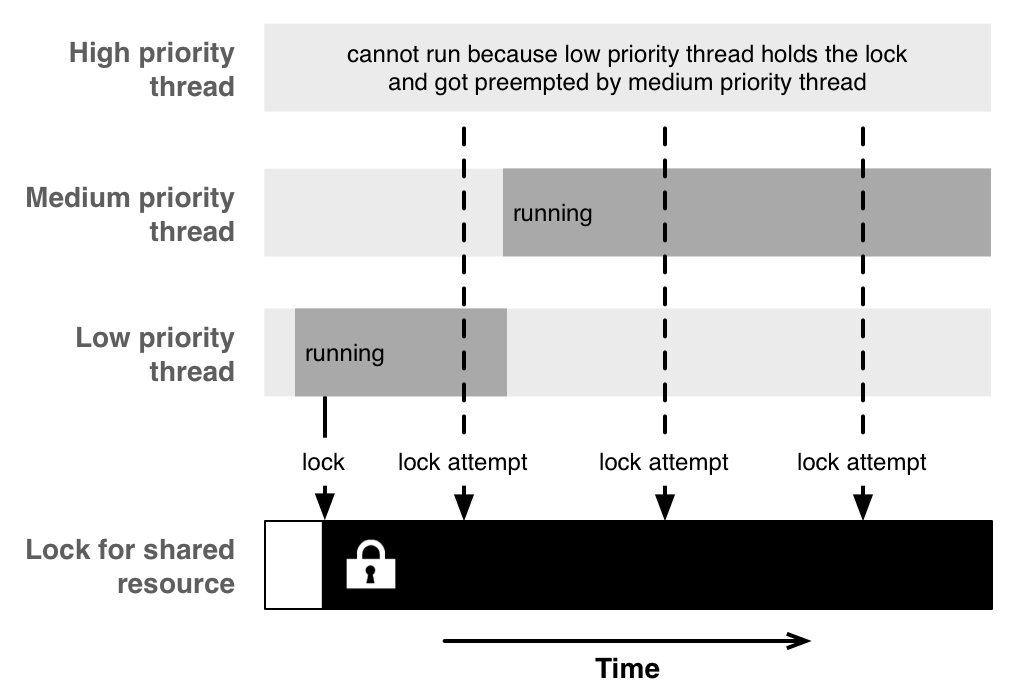
在我们的代码中,事情可能不会想火星探测器那样严重的重启,作为优先级反转经常以一个不那么严重的方式发生。
一般情况下,别使用不同的优先级。通过你将因为高优先级代码等待低优先级代码执行而终止运行。当你用GCD时,通常使用默认的优先级队列(直接的或者作为目标队列)。如果你使用不同的优先级,更有可能的是,它将使事情变得更糟。
从中获得的教训是,书上看来使用不同优先级的队列不错,但是给并发编程带来了更多的复杂性和不可预见性。如果你曾经碰到一个奇怪的问题,你的高优先级的任务好无理由的卡住,你也许将记得这篇文章被叫做优先级反转的问题,这个NASA的工程师也遇到过的。
总结
我们希望说明了并发编程的复杂性及其问题,无论多么API看起来多么简单。产生的行为很快就很难被监督,斌企鹅调试这类问题通常很困难。
另一方面,并发是一个利用现在多核CPU的计算能力的很强大的工具。关键是尽可能保持并发模型的简单性,这样你可以限制必要锁的数量。
我们推荐的安全模式是这样的:在主线程提取想要使用的数据,使用operation queue在后台做实际的工作,最后将你后台计算的结果返回到主线程中。用这个方法,你不需要自己进行任何锁操作,这样大大的减少了出错的机会。















 154
154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









