








CMDB是什么?
CMDB 就像一个人的大脑核心,是一个信息协调库,其存储的资料是协调身体完成各种复杂运动的信息来源。
我心中的 CMDB
碎片整合
面向运维工具的碎片化场景,是盘活整个运维管理的数据核心
. 元数据库
提供运维活动的基础元数据,是唯一可信的运维配置数据服务
. 场景驱动
为运维联动提供数据驱动,可协调工具来完成各类自动化场景
自动扩容+自动监控
CMDB 如何建设?
痛点现象与对策 I 模型建不好
存在的问题:
. 建模维度(粒度)失去控制
粒度若建得太细,连网线、内存条都变成配置项,最后 CMDB 中存储的 70% 数据没有作用,只是做了大量无用功。
缺少行业实践参考
国内很多时候都是根据 BMC、HP 等模型来建立一个模型库,但实际上老外的思路与国人迥异,往往会做出过于复杂的模型体系。
模型调整太笨重
使用关系型数据库,模型中每一个类型的属性都是一个列,最后调整总是要动用研发,完成一次调整需要 2 天的时间,而这种调整在数据补充阶段,往往要经常进行,耗时耗力。
我们怎么干的–管理
. 目标驱动
持续迭代的方式推进,只实现当前目标需要的最小模型集合。建议不要使用传统软件研发大瀑布模式来建设模型,而是使用持续迭代的方式,每次都设定一下较小的目标,按这个目标去建立刚好满足要求的模型库。
行业参考
寻找和借鉴行业最佳实践。寻找行业内的最佳实践,去学习他们的模型,尤其也是学习其演进路线,切不可一口吃成一个胖子。
我们怎么干的
– 技术
第一步,数据类型标签化, 支持多重身份
传统的 CMDB 系统,往往使用科学分类法的思路,按界、门、纲、目等树型结构去严格划分,但这样给建模带来了非常巨大的挑战,因为一定有一些数据四不像。比如虚拟机,到底是划到传统的计算设备资源下,还是划到虚拟资源下?所以我们提议使用数据类型标签化的方式来进行分类。比如虚拟机,我可以同时打上计算设备与虚拟资源这样两个标签。
第二步,使用关系建立联系, 分清关系与属性
使用弱类型约束的关系,而不是属性。因为属性往往要提前建模,但实际上很多配置项在建立时,是想不清楚它可能与哪些配置项产生联系的,所以使用关系可以更轻量化。
第三步,易于调整模型, 支持动态属性
在 CMDB 系统的技术设计过种中,要注重使用能快速调整的存储模型,比如使用支持 scheme 调整友好的数据库,或 postgresql 这样支持 json 扩展字段的数据库,可以实现动态属性。
痛点现象与对策 II 数据不准确
存在的问题:
. 人工录入数据、准确率低
. 没有及时维护、数据过期
. 数据来源多、存在冲突
我们怎么干的–管理
. 确定地位
确定 CMDB 作为唯一数据源,若上下数据流不准确,应从 CMDB 开始修正
. 职权划定
自定原则,例如谁提供,谁维护
. 定期审查
从制度上需要确定团队能定期对 CMDB 中的数据进行审计,寻找错误数据并改进问题。如同一些仓储管理,需要定期核查帐面与实际库存,CMDB 也需要定期审查数据与生产环境的实际符合度。
我们怎么干的
– 技术
. 支持协同
配置变更热点, 订阅我关注的配置项变更。每个人都可以查看他人的数据足迹,配置项也允许按变更次数或者被使用次数,作成热点图,最后也应允许订阅我关心的配置项,这样可以在配置项变更时,相关负责人可以及时收到通知。
. 记录历史
允许随时查询数据的变迁历史,并可回溯基线。在每一次数据入库后,都能记录数据的变更历史,以便可以随时对比版本变更的内容,以及在纠错时回溯基线。
. 支持调和
利用策略、规则实现多数据源的调和。数据来源过多,也会导致出现数据冲突。在数据出现冲突时,能显示不同数据来源的冲突,并支持人为调和,同时 CMDB 系统也应学习这些人为的调和依据,可以形成自动化调和。
. 依赖工具
在数据的采集和补充上,以使用监控与自动化工具为主,它们可以减少大量的录入工作,并且避免人为的错误。
痛点现象与对策III数据不好用
存在的问题:
.不清楚有哪些使用场景
经常有这样的情形:为了CMDB而CMDB,导致最后CMDB只是当资源台帐使用,最常使用的功能也仅仅变成了EXCEL导入与导出。而实际上,我们需要建设的是一个服务型的CMDB。
.系统开放性差
CMDB开放性差,往往只是提供了读写API,把CMDB当成一个普通的数据库来使用。
我们怎么干的–管理
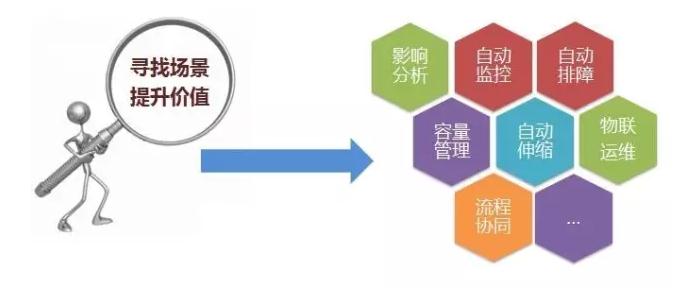
1.积极寻找场景,消费数据,让数据产生价值。
2.影响分析:使用消息盘,做配置变更演练,做故障演练。
3.自动监控:当新增一些配置项时,可以通知到监控系统,自动产生监测策略。
4.自动排障:在监测到故障时,可以自动排障。
5.容量管理:在配置库中为应用记录扩容收容阈值,以便自动伸缩扩容。
6.物联运维:CMDB中的数据,在现在的移动终端场景下,有特别好的消费场景,就是做二维码、RFID,并与手机结合,能在机房巡检与排障中产生很大的便利。
我们怎么干的–技术
1.关系推导:提供从一个配置项按关系提炼其它配置项的能力。
2.全文检索:能便捷的使用关键字,搜索符合的配置项。
3.变更通知:配置项变更不但提供对人的通知,更要利用MQ,提供对运维工具的通知,以触发一些自动化场景。
4.事务控制:允许通过API建立沙箱,整个沙箱中的配置项是一起提交与一起回滚,这特别适用于应用的上线。
5.版本对比:允许查询一个配置项的历史数据与变更情况。
6.WEB集成:除了API,还应该提供应用间的界面集成还应该提供应用间的界面集成还应该提供应用间的界面集成。
CMDB
成功要素
能消费起来的 CMDB 才是好 CMDB!
模型:定义了最小可用的 CMDB 模型结构与规则
数据:正确地维护了 CMDB 各类数据及其关系
API:提供了开放友好的 API 服务
场景:利用 CMDB 的数据玩转各种运维场景
CMDB = 模型 + 数据 + API + 场景














 8122
8122











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









