








Paper link:
CVPR 2018 Open Access Repositoryopenaccess.thecvf.com
Code link:

Abstract
多任务学习中的多元回归和分类让很多深度学习程序受益,但是多任务网络结构的性能受每一个任务损失函数的权重影响很大,常规的做法是手动调节这些权重参数,毫无疑问,这是一个低效和困难的工作,不同任务损失的尺度差异非常大,导致整体损失被某一个任务所主导,最终导致其他任务的损失无法影响网络共享层的学习过程。这也阻碍了MTL的进一步提升。本文针对多任务学习提出了一种新的策略,即通过考虑每个任务之间的同方差不确定性(homoscedastic uncertainty)来设置不同任务损失函数的权值(关于同方差不确定性的具体含义,我会展开进一步解释)。通过这样的设置,我们就可以同时学习不同单位或者尺度的回归和分类问题。本文将该方法应用于深度回归,语义和实例分割,实验结果表明,这种多任务统一的loss训练优于每一个模型任务单独训练的效果。
Introduction
多任务学习的目的是通过学习多个目标之间的共享表示来提升效率,预测精度和泛化能力。场景理解算法必须同时理解某一个场景中物体的几何形状和语义信息。不同物体之间的尺度是不同的,这就涉及到多任务学习中不同单位尺度物体的分类和回归问题的联合学习,将所有的任务融合到一个统一的模型中去有利于减少算力损耗和达到实时的要求。
同时训练多任务的常规方法是将各任务的loss简单相加或者设置统一的loss权重,更进一步,可能会手动的进行权重调整,上述的所有办法都是笨拙和低效的,因为整体的性能表现是高度依赖每一个loss的权重的,而这个权重的设置却是没有依据可循的,这就造成了矛盾和问题。作者认为,每个任务的最优权重依赖于衡量尺度并且最终依赖于任务噪声的大小。
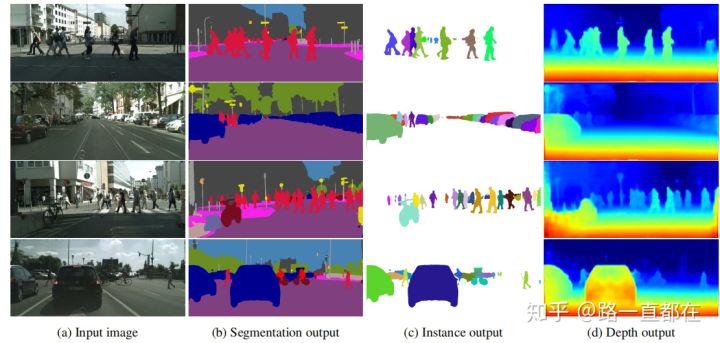
因此在这篇文章中,作者提出了新的权重设计原则,利用同方差的不确定性来结合多个任务的loss,同时学习多目标。作者将同方差不确定性解释为任务相关的权重,并且展示了如何推导一个多任务的损失函数,以及在这个过程中如何平衡不同的回归和分类损失。本文探索了有三个子任务的多任务学习网络,如下图所示,分别是语义分割,实例分割和深度估计,这三个网络具体的作用都很简单,在这里就不详细的解释了,这三个网络的训练设计到回归问题和分类问题。
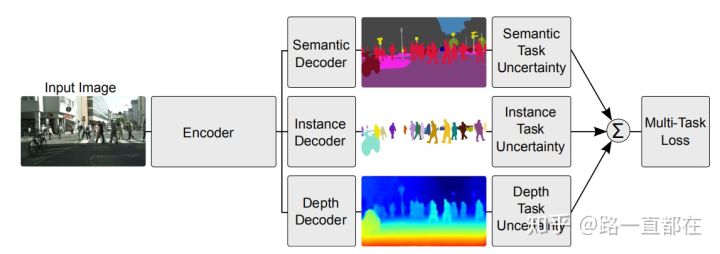
综上,本文的创新点主要有三:
- 提出一种新的多任务学习损失函数权重设置方法即利用同方差不确定性同时学习不同尺度和数量的回归和分类问题。
- 提出一个用于语义分割,实例分割和深度回归的统一框架。
- 说明了不同loss权值设置对最终多任务网络性能的影响,以及与单独训练的模型相比,如何获得更好的性能提升。
Multi Task Learning with Homoscedastic Uncertainty
多任务学习涉及根据多个目标优化模型的问题,本质上是loss的统一化,最原始的做法如下式所示,将不同任务的loss简单线性加权求和:
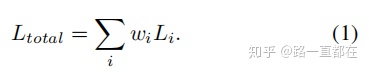
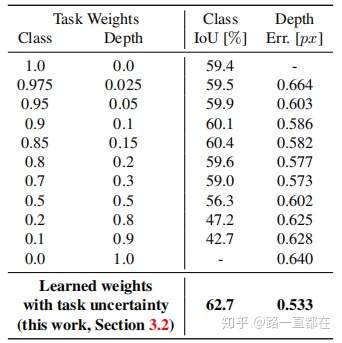
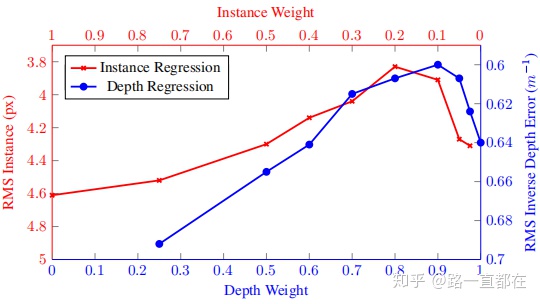
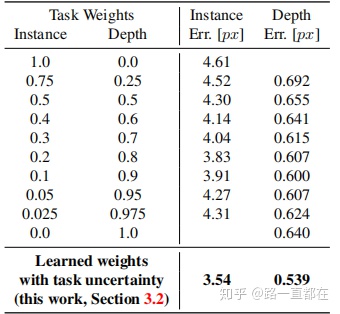
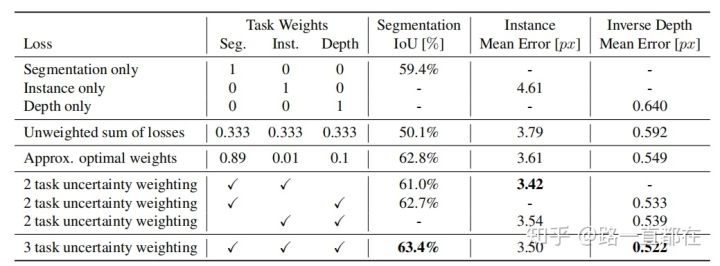
但是这种loss的计算方法有很多的弊端,如下图所示,不同任务对wi的设置非常敏感,不同wi的设置对性能表现差别很大,而且最后一行的结果也表明,本文的方法设计的权重对于多任务的训练能够比单个任务更胜一筹。
组一:语义分类和深度回归权重-性能对比
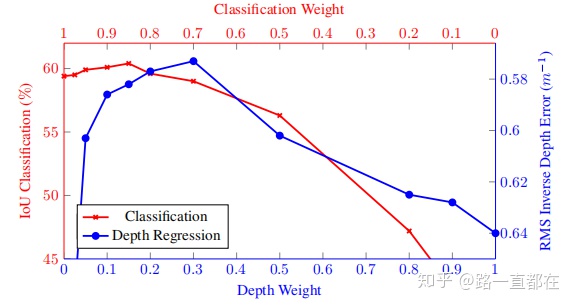
组二:实例回归和深度回归权重-性能比较
下面就详细介绍怎样用同方差不确定性来确定多任务的权重
(1). Homoscedastic uncertainty as task-dependent uncertainty
在介绍相关知识前,我想先简单说一下"不确定性”应该如何理解,在很多情况下,深度学习领域都有极佳的表现,这种表现依赖于强大的算力和深厚的网络结构,会对问题给出一个特定的结果,比如无人驾驶中的语义分割,商用的语义分割网络是十分成熟的,但是还是出现过无人驾驶发生交通事故致人殒命,究其原因是分割中将车辆判别为背景。这说明,大多数情况下,深度学习会对问题给出一个答案,注意,是一个,不管这个答案在内部有多大的把握,也就是说模型不会给出对自己最终输出的结果有多大的置信度。也许你会想,这个答案是模型在众多候选中找到概率最大的(比如分类问题最后用softmax),但是在极端情况下,如分类A和B但是在测试阶段输入C类的图片,那么分类器大概率会带来无法预知的结果,而这种错误,在容错率极低的行业,如航天,军事等领域,是绝不能容忍的。试想一下,如果面多这种极端情况,在输出结果的同时给出一个极低的对结果的置信度,这个低置信度会带来预警,让人为进行干预,效果会好很多,这种置信度的输出,就要靠贝叶斯建模了。
在贝叶斯模型中,有两种主要类型的不确定性可以建模:
- 认知不确定性(Epistemic uncertainty):是模型中的固有不确定性,由于训练数据量的不足,导致对于模型没见过的数据会有很低的置信度,认知不确定性测量的,是我们的输入是够存在于已经见过的数据的分布之中。认知不确定性解释了模型参数的不确定性。我们并不确定哪种模型权重能够最好地描述数据,但是拥有更多的数据却能降低这种不确定性。这种不确定性在高风险应用和处理小型稀疏数据时非常重要。认知不确定性可以通过增加训练数据消除。
- 偶然不确定性(Aleatoric uncertainty):举一个例子,在数据标注时如果出现比较大的标注误差,这个误差不是模型带入的,而是数据本身就存在的,数据集里的bias越大,偶然不确定性就越大。
其中,偶然不确定性可以细分为两类:
(1)数据依赖型或异方差不确定性(Data-dependent or Heteroscedastic uncertainty):这种不确定性取决于输入的数据,并且预测结果作为模型的输出
(2)任务依赖型或同方差不确定性(Task-dependent or Homoscedastic uncertainty):不依赖于输入数据,也不会是模型输出结果,而是对所有输入数据相同的常量,对不同任务不同的变量,基于这个特性,叫做任务依赖型不确定性
因为在多任务学习中,任务的不确定性表明了任务键的相对置信度,反映了回归和分类问题中固有的不确定性。因此本文提出把同方差不确定性作为噪声来对多任务学习中的权重进行优化。
(2). Multi-task likelihoods
本小节主要推导一个多任务损失函数,这个损失函数利用同方差不确定性来最大化高斯似然估计。首先定义一个概率模型:
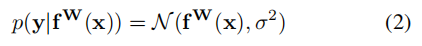
这是对于回归问题的概率模型定义,fw(x)是神经网络的输出,x是输入数据,W是权重
对于分类问题,通常会将输出压入sigmoid中,如下式所示:
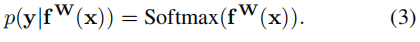
接下来,定义多任务的似然函数:
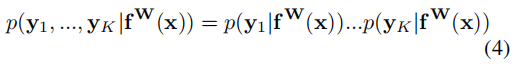
其中,yi是多任务中每个子任务的输出
那么,极大似然估计就可以表示下式,(5)式也表明,该极大似然估计与右边成正比,其中,σ是高斯分布的标准差,也是作为模型的噪声,接下来的任务就是根据W和σ最大化似然分布
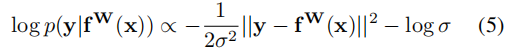
以两个输出y1和y2为例:得到如(6)式高斯分布:
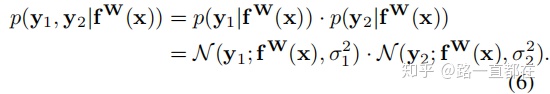
则此时的极大似然估计为(7)式:
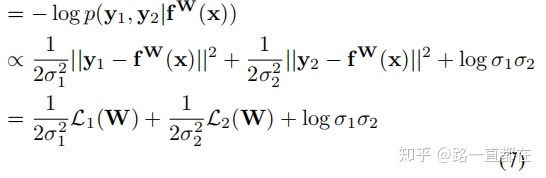
可以看到,最后一步中用损失函数替换了y和f的距离计算,即:
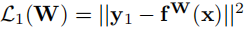
同理可知L2
继续分析(7)式子可得,我们的任务是最小化这个极大似然估计,所以,当σ(噪声)增大时,相对应的权重就会降低;另一方面,随着噪声σ减小,相对应的权重就要增加
接下来,将分类问题也考虑上,分类问题一般加一层softmax,如(8)式所示:
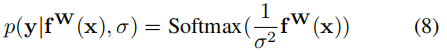
那么softmax似然估计为:
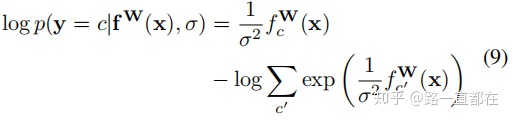
接下来考虑这种情况:模型的两个输出,一个是连续型y1,另一个是独立型y2,分别用高斯分布和softmax分布建模,可得(10)式:
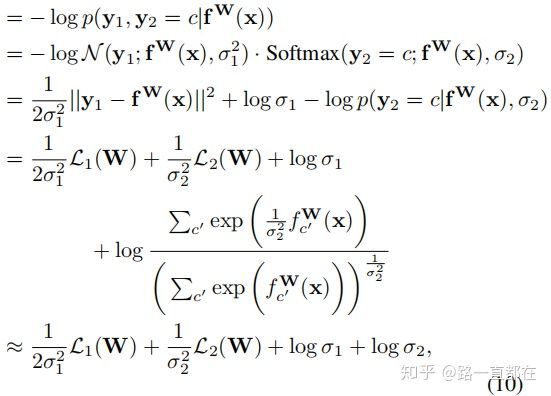
同理,
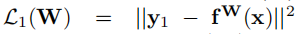
L2(W)替换为:

Experiments
本文实验的数据集是CitySpaces,一个丰富的道路场景数据集,链接如下
Semantic Understanding of Urban Street Sceneswww.cityscapes-dataset.com
下表清晰的对比了三个任务单独学习的性能和通过多任务训练loss的性能提升
So
文章首先提出了神经网络中需要对不确定性加以重视,本文着重探讨的是偶然不确定性中的任务依赖型又称同方差不确定性,在输出结果的同时需要计算结果置信度,优化极大似然分布,实现动态规划不同任务之间的权值。
参考文章
What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision?papers.nips.cc
https://blog.csdn.net/zengxiantao1994/article/details/72787849blog.csdn.net
模型可解释性差?你考虑了各种不确定性了吗? | 雷锋网www.leiphone.com
https://blog.csdn.net/weixin_43864473/article/details/86545019blog.csdn.net














 2653
2653











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









