







Saurabh是一名数据科学家和软件工程师,熟练分析各种数据集和开发智能应用程序。他目前正在加州大学伯克利分校攻读信息和数据科学硕士学位,热衷于开发基于数据科学的智能资源管理系统。
Linkedin:https://in.linkedin.com/in/saurabh-jaju
Github: https://github.com/saurabhjaju2
介绍
许多数据科学家经常面对的问题之一:假设有一个包含数百个特征(变量)的数据集,且对数据所属的域没有任何了解,需要对该数据集识别其隐藏状态、探索并分析。本文将介绍一种非常强大的方法来解决该问题。
关于PCA
现实中大多数人会使用PCA进行降维和可视化,但为什么不选择比PCA更先进的东西呢?关于PCA的介绍可以阅读该文献。本文讲解比PCA(1933)更有效的算法t-SNE(2008)。
本文内容
1 什么是t-SNE?
2 什么是降维?
3 t-SNE如何在维数降低算法空间中拟合
4 t-SNE算法的细节
5 t-SNE实际上是做什么?
6 用例
7 t-SNE与其他降维算法相比
8 示例实现
R语言
Python语言
9 应用方面
数据科学家
机器学习骇客
数据科学爱好者
10 常见错误
1 什么是t-SNE
(t-SNE)t分布随机邻域嵌入 是一种用于探索高维数据的非线性降维算法。它将多维数据映射到适合于人类观察的两个或多个维度。

2 什么是降维?
简而言之,降维就是用2维或3维表示多维数据(彼此具有相关性的多个特征数据)的技术,利用降维算法,可以显式地表现数据。
3 t-SNE如何在降维算法空间中拟合
常用的降维算法有:
1 PCA(线性)
2 t-SNE(非参数/非线性)
3 Sammon映射(非线性)
4 Isomap(非线性)
5 LLE(非线性)
6 CCA(非线性)
7 SNE(非线性)
8 MVU(非线性)
9 拉普拉斯特征图(非线性)
只需要研究上述算法中的两种——PCA和t-SNE。
PCA的局限性
PCA是一种线性算法,它不能解释特征之间的复杂多项式关系。而t-SNE是基于在邻域图上随机游走的概率分布来找到数据内的结构。
线性降维算法的一个主要问题是不相似的数据点放置在较低维度表示为相距甚远。但为了在低维度用非线性流形表示高维数据,相似数据点必须表示为非常靠近,这不是线性降维算法所能做的。
4 t-SNE算法的细节
4.1 算法
步骤1:
随机邻接嵌入(SNE)通过将数据点之间的高维欧几里得距离转换为表示相似性的条件概率而开始,数据点xi、xj之间的条件概率pj|i由下式给出:
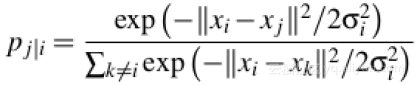
其中σi是以数据点xi为中心的高斯方差。
步骤2:
对于高维数据点xi和xj的低维对应点yi和yj而言,可以计算类似的条件概率qj|i
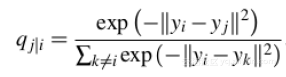
SNE试图最小化条件概率的差异。
步骤3:
为了测量条件概率差的和最小值,SNE使用梯度下降法最小化KL距离。而SNE的代价函数关注于映射中数据的局部结构,优化该函数是非常困难的,而t-SNE采用重尾分布,以减轻拥挤问题和SNE的优化问题。
步骤4:
定义困惑度:
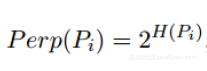
其中H(Pi)是香农熵
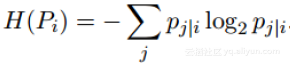
4.2 时间和空间复杂性
算法计算对应的是条件概率,并试图最小化较高和较低维度的概率差之和,这涉及大量的计算,对系统资源要求高。t-SNE的复杂度随着数据点数量有着时间和空间二次方。
5 t-SNE实际上是做什么?
t-SNE非线性降维算法通过基于具有多个特征的数据点的相似性识别观察到的簇来在数据中找到模式。本质上是一种降维和可视化技术。另外t-SNE的输出可以作为其他分类算法的输入特征。
6用例
t-SNE几乎可用于所有高维数据集,广泛应用于图像处理,自然语言处理,基因组数据和语音处理。实例有:面部表情识别[2]、识别肿瘤亚群[3]、使用wordvec进行文本比较[4]等。
7 t-SNE与其他降维算法相比
基于所实现的精度,将t-SNE与PCA和其他线性降维模型相比,结果表明t-SNE能够提供更好的结果。这是因为算法定义了数据的局部和全局结构之间的软边界。
8示例实现
在MNIST手写数字数据库上实现t-SNE算法。
“Rtsne”包在R中具有t-SNE的实现。“Rtsne”包可以使用在R控制台中键入的以下命令安装在R中:
超参数调整

代码
MNIST数据可从MNIST网站下载,并可转换为具有少量代码的csv文件。
## calling the installed package
train<‐ read.csv(file.choose()) ## Choose the train.csv file downloaded from the link above
library(Rtsne)
## Curating the database for analysis with both t‐SNE and PCA
Labels<‐train$label
train$label<‐as.factor(train$label)
## for plotting
colors = rainbow(length(unique(train$label)))
names(colors) = unique(train$label)
## Executing the algorithm on curated data
tsne <‐ Rtsne(train[,‐1], dims = 2, perplexity=30, verbose=TRUE, max_iter = 500)
exeTimeTsne<‐ system.time(Rtsne(train[,‐1], dims = 2, perplexity=30, verbose=TRUE, max_iter = 50
0))
## Plotting
plot(tsne$Y, t='n', main="tsne")
text(tsne$Y, labels=train$label, col=colors[train$label])
实现时间
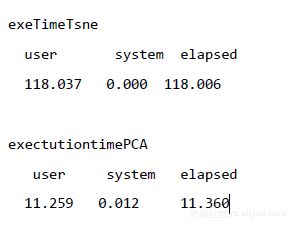
可以看出,与PCA相比,t-SNE在相同样本大小的数据上执行需要相当长的时间。
解释结果
以下图用于探索性分析。输出x和y坐标以及成本可以用作分类算法中的特征。
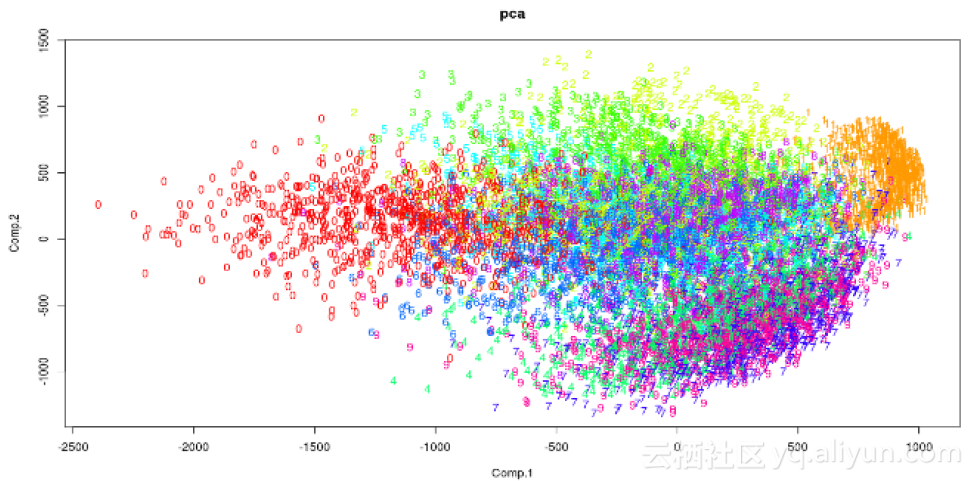
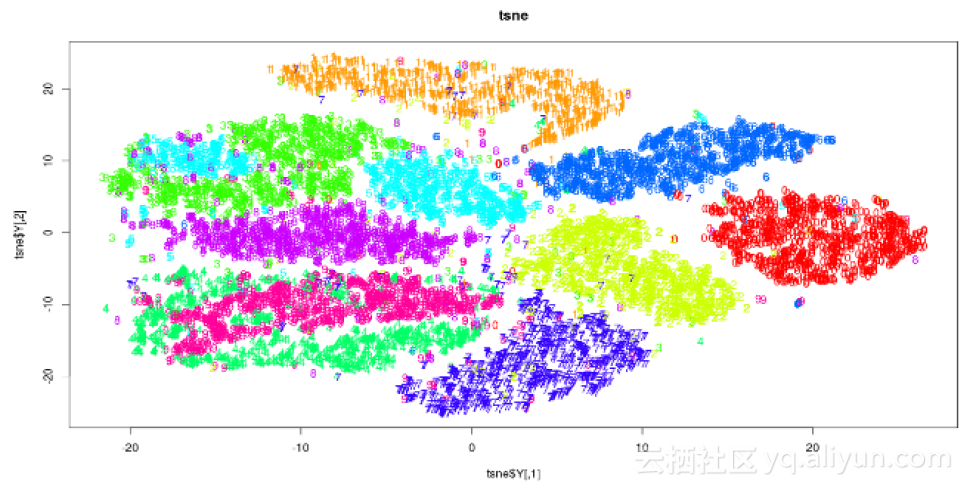
2 Python语言
t-SNE算法可以从sklearn包中访问。
超参数调整
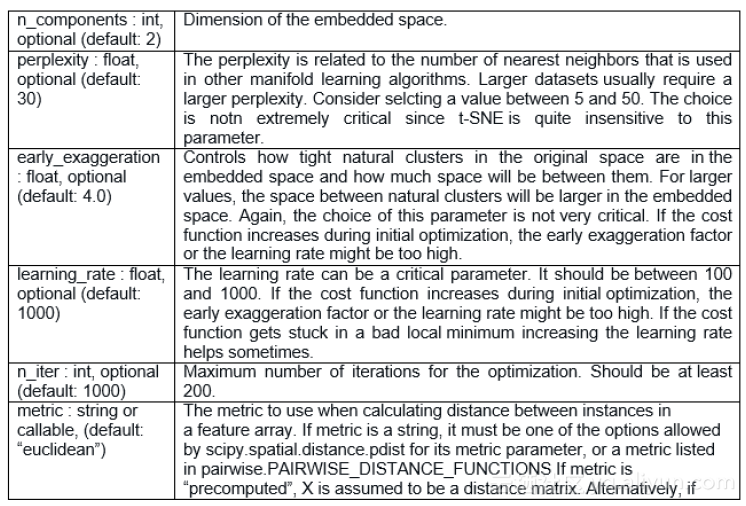
代码
以下代码来自sklearn网站上的sklearn示例。
代码1
实现时间
## importing the required packages
from time import time
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import offsetbox
from sklearn import (manifold, datasets, decomposition, ensemble,
discriminant_analysis, random_projection)
## Loading and curating the data
digits = datasets.load_digits(n_class=10)
X = digits.data
y = digits.target
n_samples, n_features = X.shape
n_neighbors = 30
## Function to Scale and visualize the embedding vectors
def plot_embedding(X, title=None):
x_min, x_max = np.min(X, 0), np.max(X, 0)
X = (X ‐ x_min) / (x_max ‐ x_min)
plt.figure()
ax = plt.subplot(111)
for i in range(X.shape[0]):
plt.text(X[i, 0], X[i, 1], str(digits.target[i]),
color=plt.cm.Set1(y[i] / 10.),
fontdict={'weight': 'bold', 'size': 9})
if hasattr(offsetbox, 'AnnotationBbox'):
## only print thumbnails with matplotlib > 1.0
shown_images = np.array([[1., 1.]]) # just something big
for i in range(digits.data.shape[0]):
dist = np.sum((X[i] ‐ shown_images) ** 2, 1)
if np.min(dist) < 4e‐3:
## don't show points that are too close
continue
shown_images = np.r_[shown_images, [X[i]]]
imagebox = offsetbox.AnnotationBbox(
offsetbox.OffsetImage(digits.images[i], cmap=plt.cm.gray_r),
X[i])
ax.add_artist(imagebox)
plt.xticks([]), plt.yticks([])
if title is not None:
plt.title(title)
#‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐
## Plot images of the digits
n_img_per_row = 20
img = np.zeros((10 * n_img_per_row, 10 * n_img_per_row))
for i in range(n_img_per_row):
ix = 10 * i + 1
for j in range(n_img_per_row):
iy = 10 * j + 1
img[ix:ix + 8, iy:iy + 8] = X[i * n_img_per_row + j].reshape((8, 8))
plt.imshow(img, cmap=plt.cm.binary)
plt.xticks([])
plt.yticks([])
plt.title('A selection from the 64‐dimensional digits dataset')
## Computing PCA
print("Computing PCA projection")
t0 = time()
X_pca = decomposition.TruncatedSVD(n_components=2).fit_transform(X)
plot_embedding(X_pca,
"Principal Components projection of the digits (time %.2fs)" %
(time() ‐ t0))
## Computing t‐SNE
print("Computing t‐SNE embedding")
tsne = manifold.TSNE(n_components=2, init='pca', random_state=0)
t0 = time()
X_tsne = tsne.fit_transform(X)
plot_embedding(X_tsne,
"t‐SNE embedding of the digits (time %.2fs)" %
(time() ‐ t0))
plt.show()
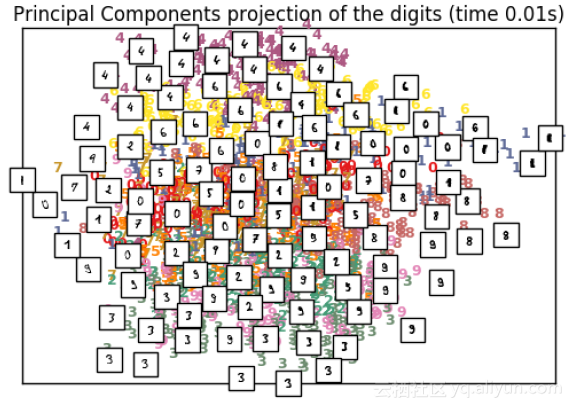
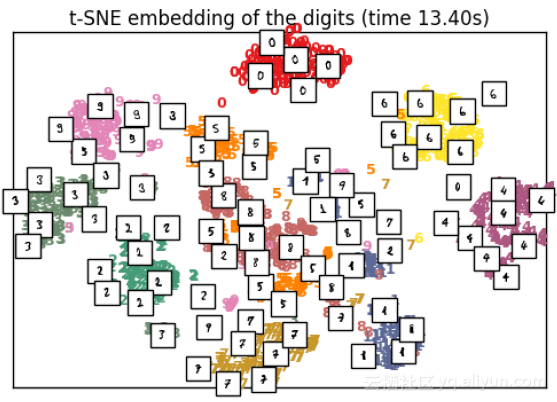
9 应用方面
9.1数据科学家
对于数据科学家来说,使用t-SNE的主要问题是算法的黑盒类型性质。使用该算法的最佳方法是将其用于探索数据分析。
9.2机器学习骇客
将数据集缩减为2或3维,并使用非线性堆栈器将其堆叠。可以使用XGboost提高t-SNE向量以获得更好的结果。
9.3数据科学爱好者
对于开始使用数据科学的数据科学爱好者来说,这种算法在研究和性能增强方面提供了最好的机会。针对各种NLP问题和图像处理应用方面实施t-SNE的研究是一个尚未开发的领域。
10常见错误
以下是在解释 t-SNE 的结果时要避免的几个常见错误:1 为了使算法正确执行,困惑度应小于点的数量。一般设置为5-50。
2 具有相同超参数的不同运行可能产生不同的结果。
3 任何t-SNE图中的簇大小不得用于标准偏差,色散或任何其他类似的评估。
4 簇之间的距离可以改变。一个茫然性不能优化所有簇的距离。
5 可以在随机噪声中找到模式。
6 不同的困惑水平可以观察到不同的簇形状。
7 不能基于单个t-SNE图进行分析拓扑,在进行任何评估之前必须观察多个图。
本文由北邮@爱可可-爱生活老师推荐,阿里云云栖社区组织翻译。














 5512
5512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









