







教学视频1(第22~27章):https://edu.51cto.com/course/5667.html?source=so
教学视频2(第三、四章):https://edu.csdn.net/course/play/24612/274990
集合:它就是一个容器
集合的由来:
当需要在程序中记录单个数据内容时,则声明一个变量即可;
当需要在程序中记录多个数据相同的数据内容时,则声明一个一维数组即可;
当需要在程序中记录多个类型不同的数据内容时,则构造一个对象即可;
当需要在程序中记录多个类型相同的对象时,则声明一个对象数组即可;
当需要在程序中记录多个类型不同的对象时,则声明一个集合即可;
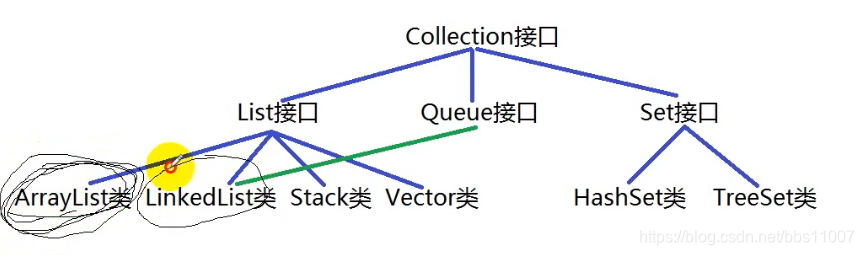
Collection集合框架(单列):
特点是以一个元素进行存放;
操作的是单个元素
Collection
List Queue set
ArrayList LinkedList Vector HashSet TreeSet
LinkeHashSet
在以后的开发很少直接用Collection集合,一般都是用它的子集合:List、set、Queue;
List的集合
有ArrayList、LinkedList、Vector,Stack类,它们的区别
ArrayList类的底层是采用动态数据进行数据管理的,查询快,增删慢
动态:就是快填满会自动释放,数据少的时候会添加,就是会自动调整
原理:
你若删除或增加元素,其他元素都要移动,例如下图删除10,后面的元素都要往前移动;

(它查询快是因为根据下标(索引)查找,但是要增删每次都需要移动数据,索引比较麻烦)
LinkedList类的底层是采用链表进行数据管理的,增删快,查询慢
原理:
什么叫链表:链就是把一块块的连接起来,--数据结构的知识!
可以从前往后找,从后往前就叫双向链表;
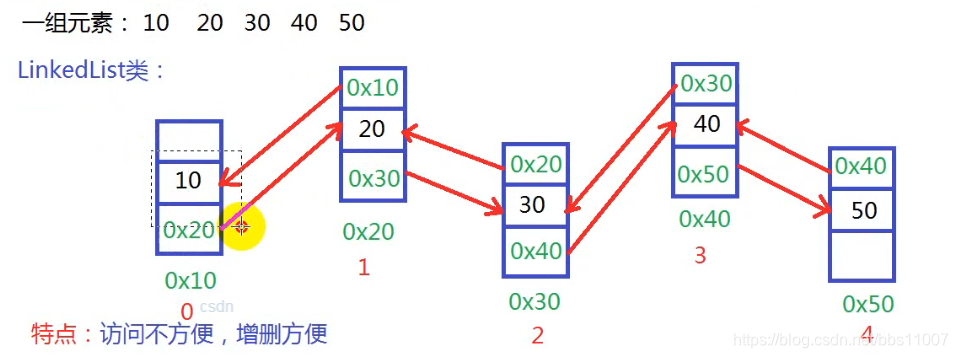
(它是没有下标,查找比较难,但是增删时不需要移动数据,只要用线连接起来即可)
ArrayList 和 LinkedList方法都一样,只是在性能上有差别, 更多的是访问的用ArrayList ,需要大量增删的LinkedList,用,如果要求不是特别苛刻,用哪个都行;
Vector类的底层是采用数组进行数据管理的,与ArrayList相比是线程安全,效率比较低,开发被ArrayList取代之;
Stack就是栈,就是后进先出;吃了吐
Queue就是队列,就是先进先出;吃了拉
Set集合
Set集合与List集合的区别:元素没有先后顺序,并且不允许有重复的元素。
set接口不能new对象:主要实现类:HashSet 、TreeSet
HashSet类的底层是采用哈希表进行数据管理的
简单的哈希表结构:链表数组,如下图:由数组+链表构成;(还要更复杂的)
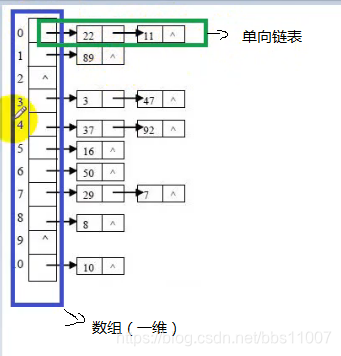
原理:
深层底层大概原理,根据哈希值的算法,找出索引位置,索引该集合不是随机的。


TreeSet类的底层是采用二叉数进行数据管理的
原理:
指最多只有二个分叉的树就是二叉树,二叉树顶端就是树叶,下图就很形象
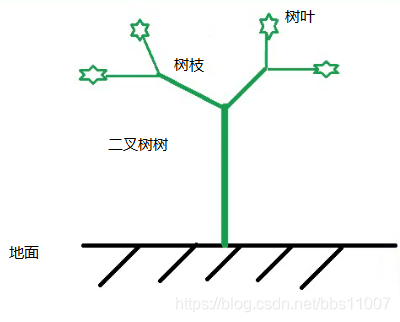
但计算机识别的是喜欢旋转180度,也就是倒挂的二叉树,如下图类似的:
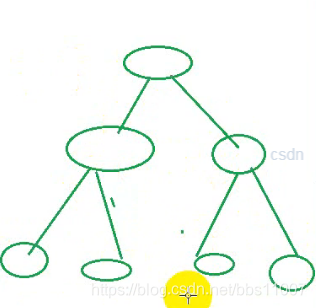
toString():
略!一般自动调用,隐藏的。
迭代器Iterator
什么叫迭代?就是今天学的东西要用到明天的东西。学习就是迭代的过程
略
增强for循环(for each结构):
jdk1.5开始,就是经典的迭代,如果把集合的内容一个个遍历那就用增强型for循环,就不要迭代了。

例如遍历集合:
s1是集合的名称,ts是一个new对象

例如遍历数组:
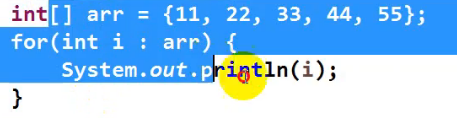
或者
遍历数组:
int[] arr = {11,22,33,44,55};//数组
for(int i : arr ){
System.out.printfln(i);
}比迭代器简单很多;
小结:
遍历Set集合的方式有三种:toString()、for each结构、迭代器,这三者的区别
toString():它只能取出一个整体,只能是String类型;
for each结构:能取出每个元素,代码最简洁,缺点是不能remove删除元素
迭代器:即可用一个个取出,还可以remove删除元素;
遍历List集合的方式有四种:除以上三种,还要get方法(里面也有迭代方法);

List和Set的区别:如上图所示!
Map集合框架(双列):
特点是以一对元素进行存放;
操作的是单对元素
Map
Hashtable HashMap TreeMap
Properties LinkedHashMap
Map接口来自java.util包,该集合不允许出现重复的键,只能映射到一个值;
为什么要Map集合:
答:以前讲的集合都直接把值丢进去没有目录,Map提供key,目录有就查找,没有就不查找,也就是提高效率;
Map<K,V>:支持两种类似的泛型
K-此映射所维护的键(Key)的类型;(类似目录)
V-映射值(value)的类型;(类似对应的页码)
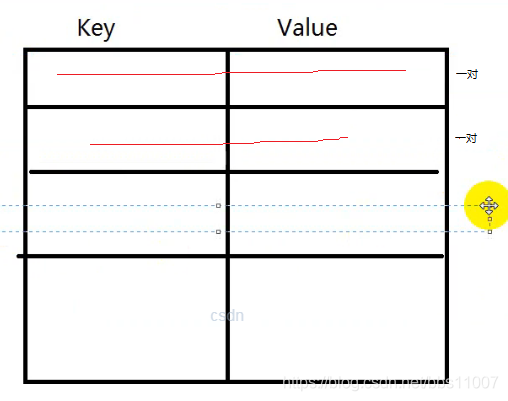
Map的子集合的区别(面试):
Hashtable :属于早期提供的类,属于线程安全的类,效率比较低;跟Vector类似开发少用
HashMap:类的底层是采用哈希表进行数据管理,新增加的类,非线程安全的,效率高;
TreeMap:类的底层是采用二叉树进行数据管理,
Map的遍历
基本操作方法:增删改查
1.增加和修改方法 put(K,V)

增加功能:

2.修改功能:

3.查找方法:get(Key)

其他查找方法:1.查找Key方法containsKey();2.查找Value方法containsValue

4.删除方法:remove(Key)

第1种遍历方法:调用toString()方法,只能取整体,不能一个个取


第2种遍历方法(常用):我们想一个个取出来,就想到使用迭代器,但是Map集合没有迭代器,但是有个entrySet()方法,就是把Map集合转换为Set集合


相当于把Map集合转换为Set集合基本原理:
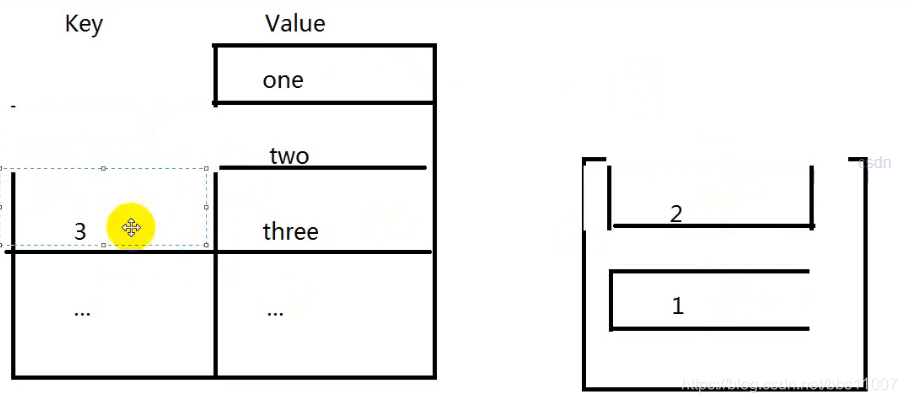
相当于把Map一行一行撕下来放入Set集合中
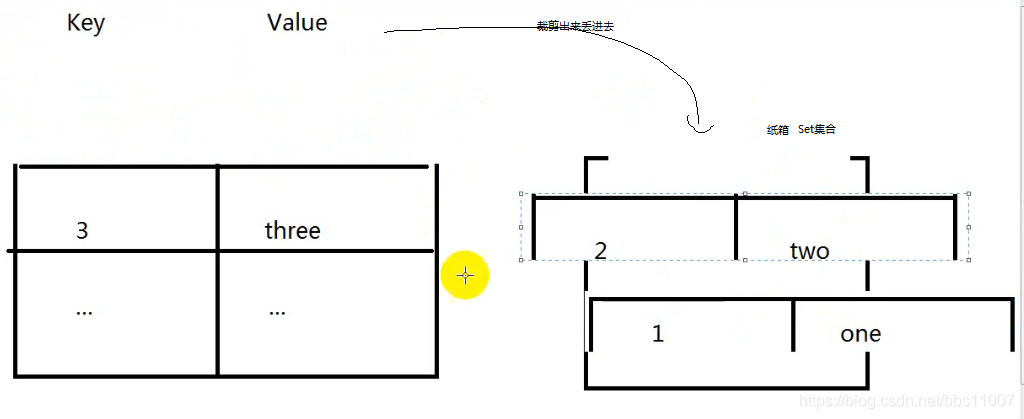
代码例子:
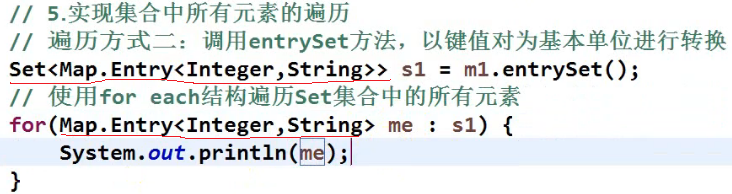
画红线的都是根据方法复制(Ctrl+L)过来的,看起来很复制,不用管它,根据文档直接复制返回值,如下图画红线部分就是,K和V改成实际值<Integer,String>就行;
![]()
扩展知识:Map.Enter<K,V>就是内部接口(内部类),就是Map源码里面里面的一个接口
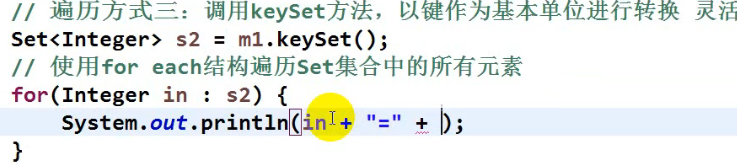
第3种遍历方法:
![]()
这种类似,但是是单独把key一个个放热到Set:
Map的性能调优:
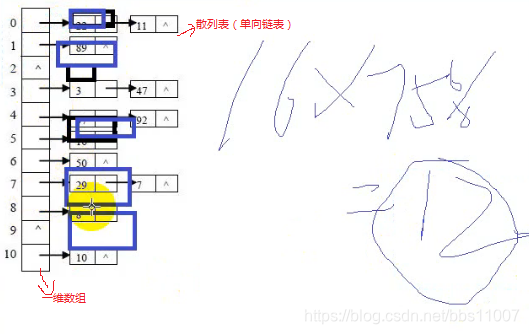
原理简单讲解,结合上图:
Initial capcity里面的容量是16是指一维数组的长度16;
加载因子75%是指,16*75%=12,也就是说当单向链表(散列表)挂的内容达到12的数量,就认为它要满了,就会自动扩容。

Map集合的实际使用:

总结:
什么时候用哪个集合:
ArrayList:当有大量访问的时候用它,因为它访问快
LinkedList:当有大量增删的时候用它,因为它增删快
Stack:当后进先出用它,因为是栈
Queue:当先进先出用它,因为是队列
HashSet:主要为了去重
Vector:线程安全,效率低少用
Map集合:相当于增加了目录
Hashtable :早期的类,效率低,少用
HashMap:用Map集合就用这个较多















 1687
1687











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











