










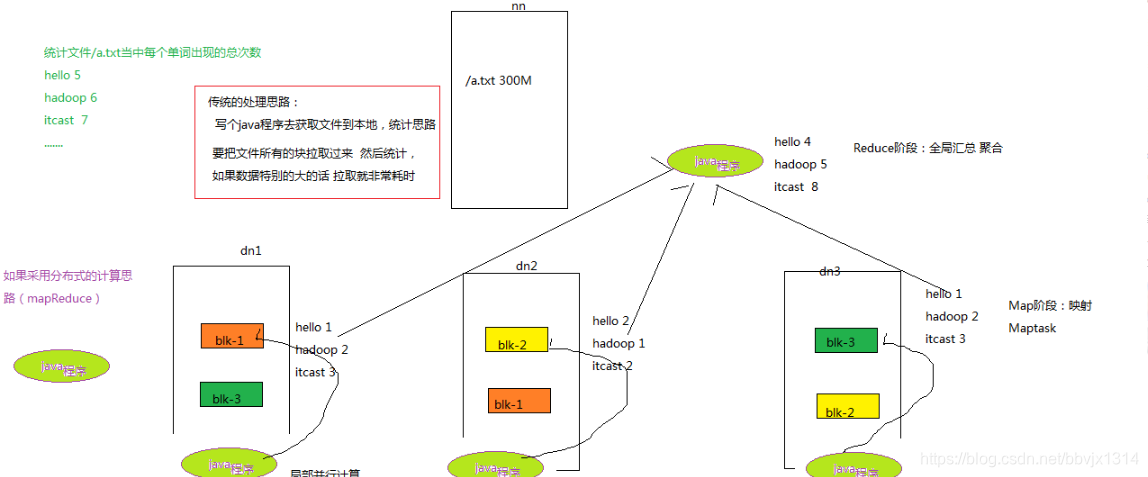
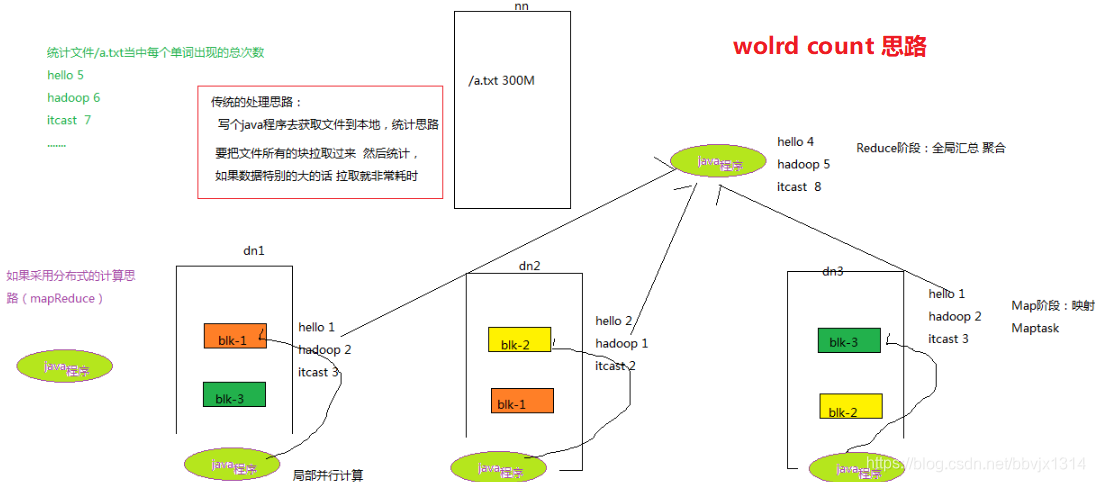
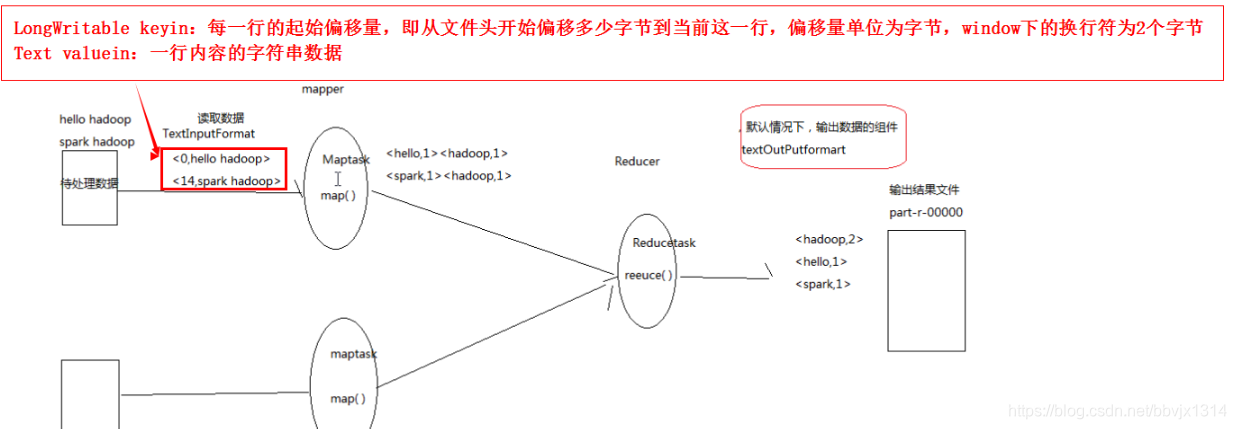
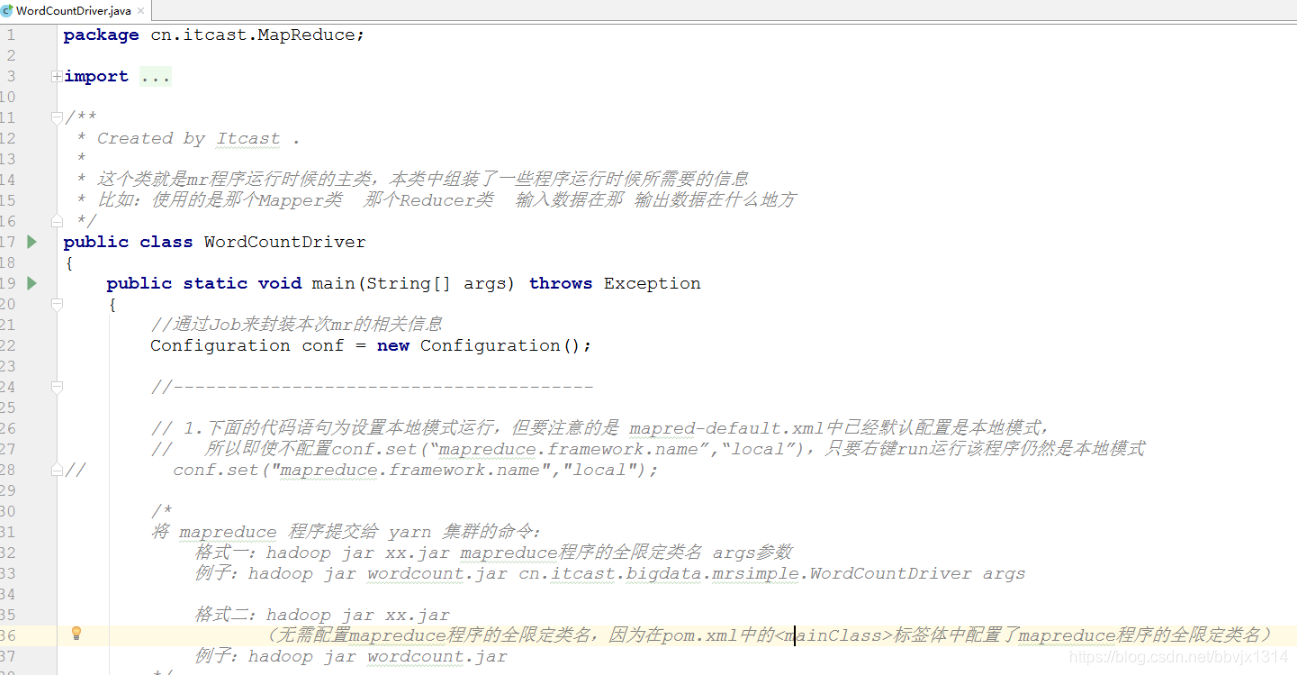
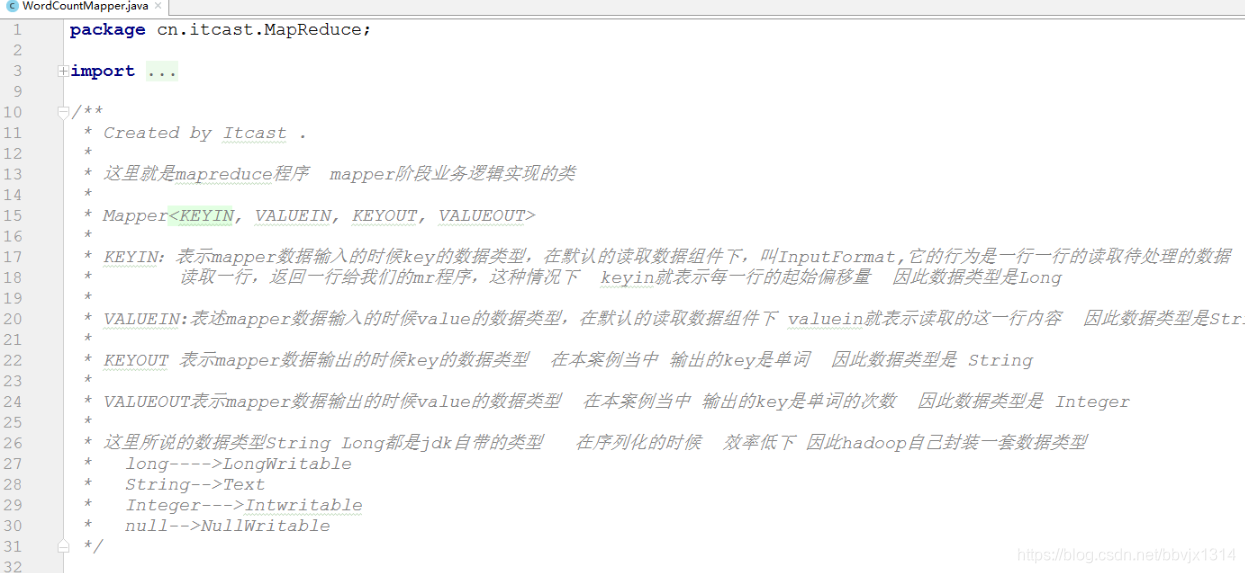
案例 : world count

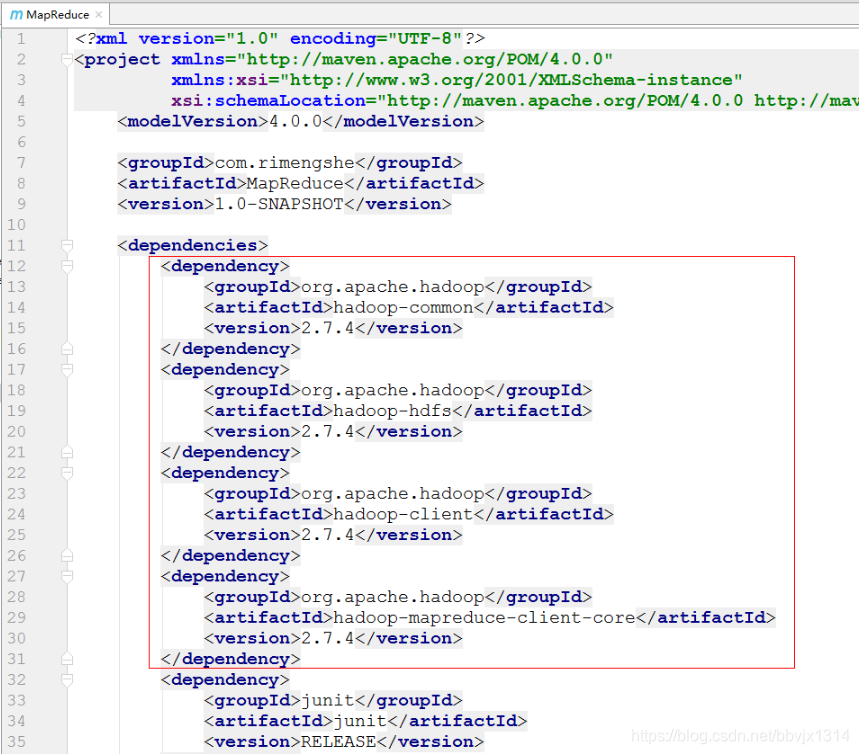
IDEA pom文件 :


![]()
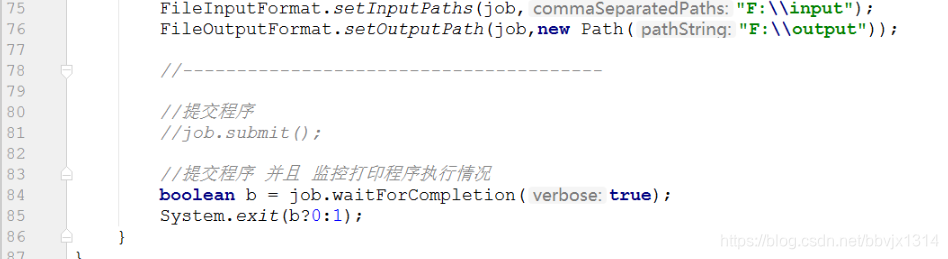


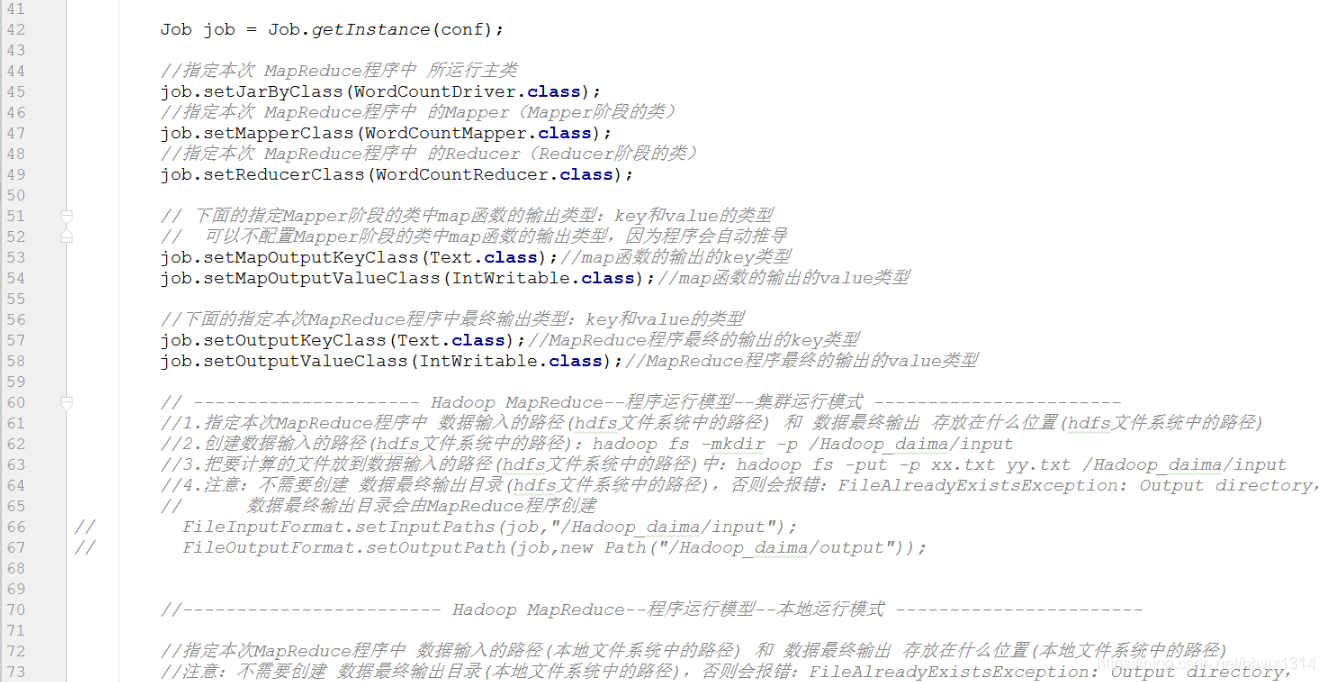
指定本次MapReduce程序中 数据输入的路径(hdfs文件系统中的路径) 和 数据最终输出 存放在什么位置(hdfs文件系统中的路径)
1.创建数据输入的路径(hdfs文件系统中的路径):hadoop fs -mkdir -p /Hadoop_daima/input
2.把要计算的文件放到数据输入的路径(hdfs文件系统中的路径)中:hadoop fs -put xx.txt yy.txt /Hadoop_daima/input
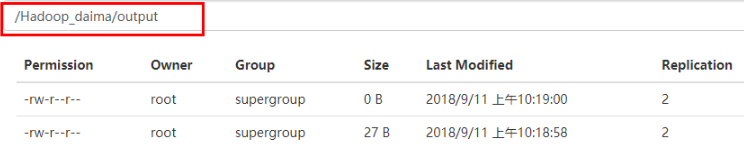
3.注意:不需要创建 数据最终输出目录(hdfs文件系统中的路径),否则会报错:FileAlreadyExistsException: Output directory,
数据最终输出目录会由MapReduce程序创建



Hadoop MapReduce--程序运行模型--集群运行模式
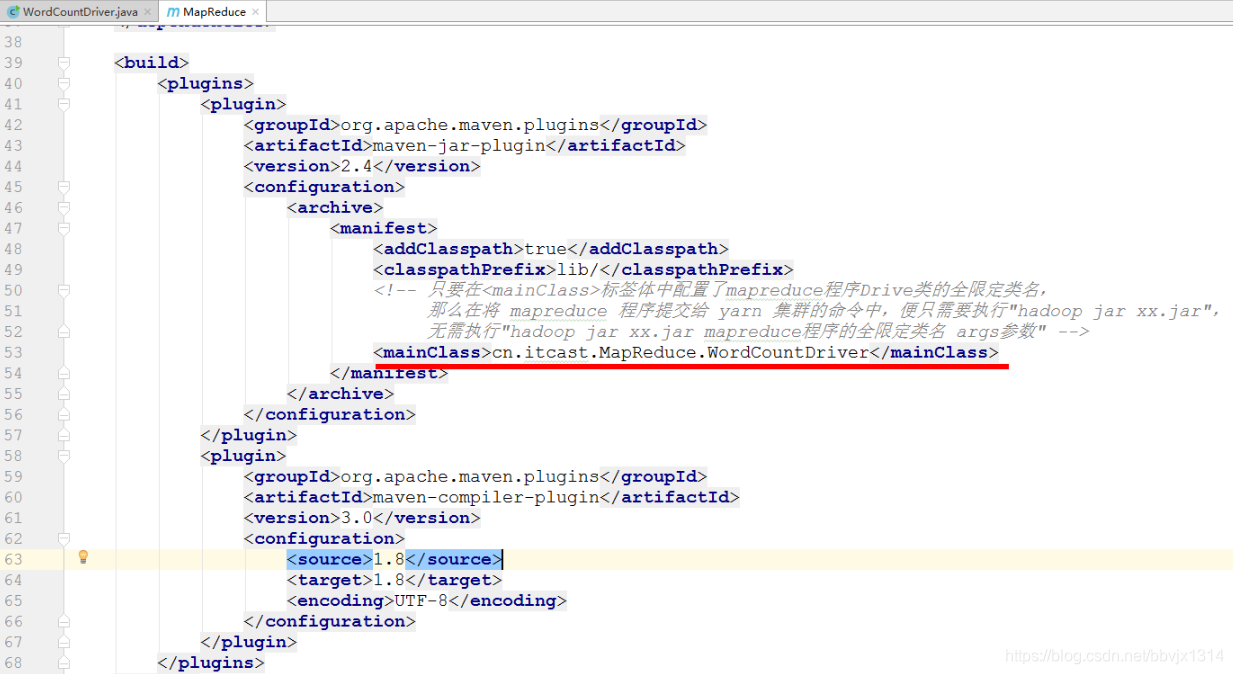
将 mapreduce 程序提交给 yarn 集群的命令:
格式一:hadoop jar xx.jar mapreduce程序的全限定类名 args参数
例子:hadoop jar wordcount.jar cn.itcast.bigdata.mrsimple.WordCountDriver args
格式二:hadoop jar xx.jar
(无需配置mapreduce程序的全限定类名,因为在pom.xml中的<mainClass>标签体中配置了mapreduce程序的全限定类名)
例子:hadoop jar wordcount.jar


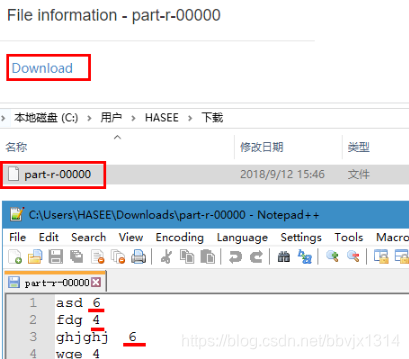

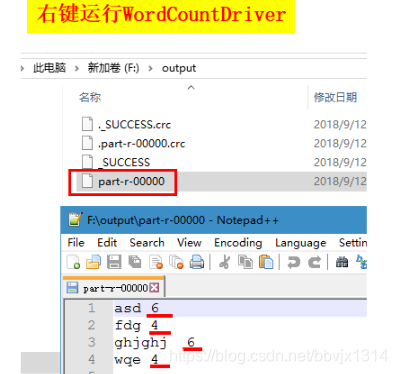
Hadoop MapReduce--程序运行模型--本地运行模式
conf.set("mapreduce.framework.name","local")代码语句 为设置本地模式运行,但要注意的是 mapred-default.xml中已经默认配置是本地模式,
所以即使不配置conf.set(“mapreduce.framework.name”,“local”),只要右键run运行该程序仍然是本地模式
















 1153
1153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











