







利用 WordCloud 制作词云
1.jieba分词
链接:https://github.com/fxsjy/jieba
“结巴”中文分词是一个使用起来非常方便的 Python 中文分词组件。
jieba.cut方法接受四个输入参数:需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型;use_paddle 参数用来控制是否使用paddle模式下的分词模式,paddle模式采用延迟加载方式,通过enable_paddle接口安装paddlepaddle-tiny,并且import相关代码。jieba.cut_for_search方法接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细。- 待分词的字符串可以是 unicode 或 UTF-8 字符串、GBK 字符串。注意:不建议直接输入 GBK 字符串,可能无法预料地错误解码成 UTF-8。
jieba.cut以及jieba.cut_for_search返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode),或者用jieba.lcut以及jieba.lcut_for_search直接返回 list。jieba.Tokenizer(dictionary=DEFAULT_DICT)新建自定义分词器,可用于同时使用不同词典。jieba.dt 为默认分词器,所有全局分词相关函数都是该分词器的映射。
import jieba
seg_list = jieba.cut_for_search('今天的天气非常好')
print(list(seg_list))

载入词典
- 开发者可以指定自己自定义的词典,以便包含 jieba 词库里没有的词。虽然 jieba 有新词识别能力,但是自行添加新词可以保证更高的正确率。
- 用法:
jieba.load_userdict(file_name)# file_name 为文件类对象或自定义词典的路径。 - 词典格式和 dict.txt 一样,一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。file_name 若为路径或二进制方式打开的文件,则文件必须为 UTF-8 编码。词频省略时使用自动计算能保证分出该词的词频。
调整词典
- 使用
add_word(word, freq=None, tag=None)和del_word(word)可在程序中动态修改词典。 - 使用
suggest_freq(segment, tune=True)可调节单个词语的词频,使其能(或不能)被分出来。
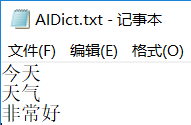
jieba.load_userdict('AIDict.txt')
words=jieba.cut('今天的天气非常好')
print(list(words))

可以看到在自建词典里我把“非常好”作为一个词语,载入后,它就没有被分成“非常”和“好”。
再看一个例子。
import jieba.posseg as pseg
words = pseg.cut('中华人民共和国国民经济和社会发展第十四个五年规划和2035年远景目标纲要')
for key in words:
print(key.word, key.flag)

145.txt中保存的是《中华人民共和国国民经济和社会发展第十四个五年规划和2035年远景目标纲要》的文本信息。
with open('145.txt','r',encoding='utf-8') as f:
gov = f.read()
jieba.load_userdict("AIDict.txt")
seg_list = jieba.cut(gov,cut_all=False)
经过简单分词后的结果。
print(list(seg_list))

tf = {}
for seg in seg_list:
if seg in tf:
tf[seg]+=1
else:
tf[seg]=1
print(len(tf))

一共分成了4888个词。
ci = list(tf.keys())
print(ci)

分词的结果肯定会出现一些如“啊”、“等”、“的”、“和”之类的无意义的词,所以我们预先将这类词建成词表,最后在实际读取的时候略过这个词表中的词。

with open('NewsAnalysis\stopword.txt','r',encoding='utf-8') as ft:
stopword = ft.read()
for seg in ci:
if tf[seg]<10 or len(seg)<2 or seg in stopword or '一' in seg:
tf.pop(seg)
print(len(tf))

经过筛选后,得到满足条件的398个词。
ci = list(tf.keys())
num = list(tf.values())
data = []
for i in range(len(tf)):
data.append((num[i],ci[i]))
data.sort()
data.reverse()
print(data)

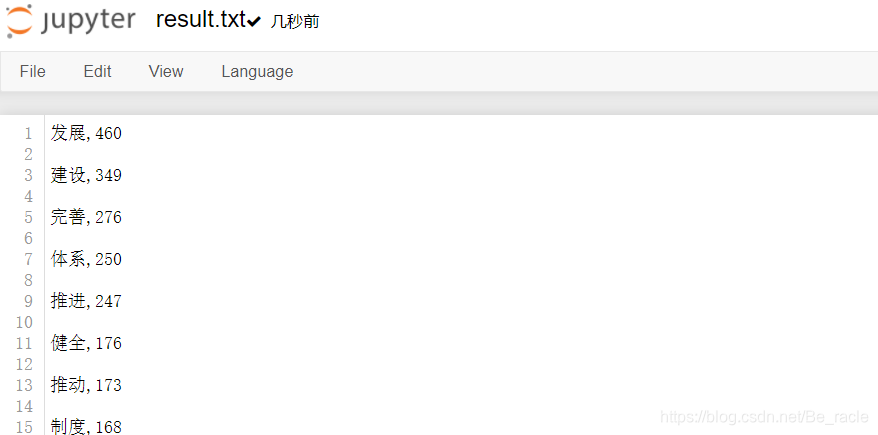
将结果写入文件result.txt。
f=open(r'NewsAnalysis\result.txt','w',encoding='utf-8')
for i in range(len(data)):
f.write(data[i][1]+","+str(data[i][0])+"\r\n")
f.close()
2.词云制作
wordcloud:https://amueller.github.io/word_cloud/
from wordcloud import WordCloud
import matplotlib.pyplot as plt
直接使用未经分词的文本绘制词云。
text = open('145.txt','r',encoding='utf-8').read()
font = r'c:\Windows\Fonts\simfang.ttf'
wc = WordCloud(font_path=font).generate(text)
plt.imshow(wc)
plt.axis('off')
plt.show()

按照分好词的词典中的词语制作词云。
wcdata = {}
for d in data: #data文件在上文中已经进行分词并统计了词频。
wcdata[d[1]] = d[0]
text = open('145.txt','r',encoding='utf-8').read()
font = r'c:\Windows\Fonts\simfang.ttf'
wc = WordCloud(font_path=font,background_color='white').generate_from_frequencies(wcdata)
plt.imshow(wc)
plt.axis('off')
plt.show()

绘制其他形状的词云。

from PIL import Image
import numpy as np
from wordcloud import WordCloud,ImageColorGenerator
mask = np.array(Image.open('NewsAnalysis\heart.png'))
image_colors = ImageColorGenerator(mask)
wcdata={}
for d in data:
wcdata[d[1]]=d[0]
text = open('145.txt','r',encoding='utf-8').read()
font = r'c:\Windows\Fonts\simfang.ttf'
wc = WordCloud(font_path=font,background_color='white',mask=mask).generate_from_frequencies(wcdata)
plt.imshow(wc.recolor(color_func=image_colors))
plt.axis('off')
plt.show()

3.读取数据库内容并制作词云
代码和前面基本相同,只是把原来存在txt中的文件换成了从数据库中读取的文本信息。
import pandas as pd
import pymysql
连接数据库。
db = pymysql.connect("localhost","root","密码","数据库名",charset="utf8")
cursor = db.cursor()
try:
#content = cursor.execute('select * from cucnews limit 10')
content = pd.read_sql('select content from cucnews',db)
db.commit()
except:
print('数据库连接错误!')
db.rollback()
db.close()
content.head()

将content列的内容合并成一个文本数据。
text = str()
for i in range(len(content)):
text = text + content['content'][i]
text

分词并统计词频。
seg_list = jieba.cut(text,cut_all=False)
tf = {}
for seg in seg_list:
if seg in tf:
tf[seg]+=1
else:
tf[seg]=1
ci = list(tf.keys())
引入停顿词词典,并设置筛选条件。
with open('NewsAnalysis\cucnews_stopword.txt','r',encoding='utf-8') as ft:
stopword = ft.read()
for seg in ci:
if tf[seg]<10 or len(seg)<2 or seg in stopword or '一' in seg:
tf.pop(seg)
ci = list(tf.keys())
num = list(tf.values())
data = []
for i in range(len(tf)):
data.append((num[i],ci[i]))
data.sort()
data.reverse()
data

按照data中的词语进行分词。
wcdata = {}
for d in data:
wcdata[d[1]] = d[0]
font = r'c:\Windows\Fonts\simfang.ttf'
wc = WordCloud(font_path=font,background_color='white').generate_from_frequencies(wcdata)
plt.imshow(wc)
plt.axis('off')
plt.show()

本文代码已上传至 我的GitHub,需要的朋友可以自行下载。
https://github.com/Beracle/07-public-opinion-analysis/tree/main/wordcloud
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











