







构造函数和析构函数的特点是当创建对象时,自动执行构造函数;当销毁对象时,析构函数自动被执行。这两个函数分别是一个对象最先和最后被执行的函数,构造函数在创建对象时调用,用来初始化该对象的初始状态和取得该对象被使用前需要的一些资源,比如文件/网络连接等;析构函数执行与构造函数相反的操作,主要是释放对象拥有的资源,而且在此对象的生命周期这两个函数都只被执行一次。
创建一个对象一般有两种方式,一种是从线程运行栈中创建,也称为"局部对象",一般语句为:

 ...
{
...
{ …… Object obj; ① ……
…… Object obj; ① …… }
②
}
②
销毁这种对象并不需要程序显式地调用析构函数,而是当程序运行出该对象所属的作用域时自动调用。比如上述程序中在①处创建的对象obj在②处会自动调用该对象的析构函数。在这种方式中,对象obj的内存在程序进入该作用域时,编译器生成的代码已经为其分配(一般都是通过移动栈指针),①句只需要调用对象的构造函数即可。②处编译器生成的代码会调用该作用域内所有局部的用户自定义类型对象的析构函数,对象obj属于其中之一,然后通过一个退栈语句一次性将空间返回给线程栈。
另一种创建对象的方式为从全局堆中动态创建,一般语句为:
……
Object * obj = new Object; ①
……
delete obj; ②
……
} ③
当执行①句时,指针obj所指向对象的内存从全局堆中取得,并将地址值赋给obj。但指针obj本身却是一个局部对象,需要从线程栈中分配,它所指向的对象从全局堆中分配内存存放。从全局堆中创建的对象需要显式调用delete销毁,delete会调用该指针指向的对象的析构函数,并将该对象所占的全局堆内存空间返回给全局堆,如②句。执行②句后,指针obj所指向的对象确实已被销毁。但是指针obj却还存在于栈中,直到程序退出其所在的作用域。即执行到③处时,指针obj才会消失。需要注意的是,指针obj的值在②处至③处之间,仍然指向刚才被销毁的对象的位置,这时使用这个指针是危险的。在 Win32平台中,访问刚才被销毁对象,可能出现3种情况。第1种情况是该处位置所在的"内存页"没有任何对象,堆管理器已经将其进一步返回给系统,此时通过指针obj访问该处内存会引起"访问违例",即访问了不合法的内存,这种错误会导致进程崩溃;第2种情况是该处位置所在的"内存页"还有其他对象,且该处位置被回收后,尚未被分配出去,这时通过指针obj访问该处内存,取得的值是无意义的,虽然不会立刻引起进程崩溃,但是针对该指针的后续操作的行为是不可预测的;第3种情况是该处位置所在的"内存页"还有其他对象,且该处位置被回收后,已被其他对象申请,这时通过指针obj访问该处内存,取得的值其实是程序其他处生成的对象。虽然对指针obj的操作不会立刻引起进程崩溃,但是极有可能会引起该对象状态的改变。从而使得在创建该对象处看来,该对象的状态会莫名其妙地变化。第2种和第3种情况都是很难发现和排查的bug,需要小心地避免。
创建一个对象分成两个步骤,即首先取得对象所需的内存(无论是从线程栈还是从全局堆中),然后在该块内存上执行构造函数。在构造函数构建该对象时,构造函数也分成两个步骤。即第1步执行初始化(通过初始化列表),第2步执行构造函数的函数体,如下:
{
public :
Derived() : i( 10 ), string ( " unnamed " ) ①
{
... ②
}
...
private :
int i;
string name;
...
};
①步中的 ": i(10), string("unnamed")" 即所谓的"初始化列表",以":"开始,后面为初始化单元。每个单元都是"变量名(初始值)"这样的模式,各单元之间以逗号隔开。构造函数首先根据初始化列表执行初始化,然后执行构造函数的函数体,即②处语句。对初始化操作,有下面几点需要注意。
(1)构造函数其实是一个递归操作,在每层递归内部的操作遵循严格的次序。递归模式为首先执行父类的构造函数(父类的构造函数操作也相应的包括执行初始化和执行构造函数体两个部分),父类构造函数返回后构造该类自己的成员变量。构造该类自己的成员变量时,一是严格按照成员变量在类中的声明顺序进行,而与其在初始化列表中出现的顺序完全无关;二是当有些成员变量或父类对象没有在初始化列表中出现时,它们仍然在初始化操作这一步骤中被初始化。内建类型成员变量被赋给一个初值。父类对象和类成员变量对象被调用其默认构造函数初始化,然后父类的构造函数和子成员变量对象在构造函数执行过程中也遵循上述递归操作。一直到此类的继承体系中所有父类和父类所含的成员变量都被构造完成后,此类的初始化操作才告结束。
(2)父类对象和一些成员变量没有出现在初始化列表中时,这些对象仍然被执行构造函数,这时执行的是"默认构造函数"。因此这些对象所属的类必须提供可以调用的默认构造函数,为此要求这些类要么自己"显式"地提供默认构造函数,要么不能阻止编译器"隐式"地为其生成一个默认构造函数,定义除默认构造函数之外的其他类型的构造函数就会阻止编译器生成默认构造函数。如果编译器在编译时,发现没有可供调用的默认构造函数,并且编译器也无法生成,则编译无法通过。
(3)对两类成员变量,需要强调指出即"常量"(const)型和"引用"(reference)型。因为已经指出,所有成员变量在执行函数体之前已经被构造,即已经拥有初始值。根据这个特点,很容易推断出"常量"型和"引用"型变量必须在初始化列表中正确初始化,而不能将其初始化放在构造函数体内。因为这两类变量一旦被赋值,其整个生命周期都不能修改其初始值。所以必须在第一次即"初始化"操作中被正确赋值。
(4)可以看到,即使初始化列表可能没有完全列出其子成员或父类对象成员,或者顺序与其在类中声明的顺序不符,这些成员仍然保证会被"全部"且"严格地按照顺序"被构建。这意味着在程序进入构造函数体之前,类的父类对象和所有子成员变量对象都已经被生成和构造。如果在构造函数体内为其执行赋初值操作,显然属于浪费。如果在构造函数时已经知道如何为类的子成员变量初始化,那么应该将这些初始化信息通过构造函数的初始化列表赋予子成员变量,而不是在构造函数体中进行这些初始化。因为进入构造函数体时,这些子成员变量已经初始化一次。
下面这个例子演示了构造函数的这些重要特性:
| |
B::B() ④
C1::C1() ⑤
C2::C2() ⑥
C3::C3() ⑦
D::D() ⑧
可以看到,①处调用D::D(double,int)构造函数构造对象d,此构造函数从②处开始引起了一连串的递归构造。从输出可以验证递归操作的如下规律。
(1)递归从父类对象开始,D的构造函数首先通过"初始化"操作构造其直接父类B的构造函数。然后B的构造函数先执行"初始化"部分,该"初始化"操作构造B的直接父类A,类A没有自己的成员需要初始化,所以其"初始化"不执行任何操作。初始化后,开始执行类A的构造函数,即③的输出。
(2)构造类A的对象后,B的"初始化"操作执行初始化类表中的j(0)对j进行初始化。然后进入B的构造函数的函数体,即④处输出的来源。至此类B的对象构造完毕,注意这里看到初始化列表中并没有"显式"地列出其父类的构造函数。但是子类在构造时总是在其构造函数的"初始化"操作的最开始构造其父类对象,而忽略其父类构造函数是否显式地列在初始化列表中。
(3)构造类B的对象后,类D的"初始化"操作接着初始化其成员变量对象,这里是c1,c2和c3。因为它们在类D中的声明顺序就是c1 -> c2 -> c3,所以看到它们也是按照这个顺序构造的,如⑤,⑥,⑦ 3处输出所示。注意这里故意在初始化列表中将c2的顺序放在了c1的前面,c3甚至都没有列在初始化列表中。但是输出显示了成员变量的初始化严格按照它们在类中的声明顺序进行,而忽略其是否显式地列在初始化列表中,或者显示在初始化列表中的顺序如何。应该尽量将成员变量初始化列表中出现的顺序与其在类中声明的顺序保持一致,因为如果使用一个变量的值来初始化另外一个变量时,程序的行为可能不是开发人员预想的那样,比如:
{
public :
Object() : v2( 5 ), v1(v2 * 3 ) { … }
private :
int v1, v2;
}
这段程序的本意应该是首先将v2初始化为5,然后用v2的值来初始化v1,从而v1=15。然而通过验证,初始化后的v2确实为5,但v1则是一个非常奇怪的值(在笔者的电脑上输出是12737697)。这是因为实际初始化时首先初始化v1,这时v2还尚未正确初始化,根据v2计算出来的v1也就不是一个合理的值了。当然除了将成员变量在初始化列表中的顺序与其在类中声明的顺序保持一致之外,最好还是避免在初始化列表中用某个成员变量的值初始化另外一个成员变量的值。
(4)随着c1、c2和c3这3个成员变量对象构造完毕,类D的构造函数的"初始化"操作部分结束,程序开始进入其构造函数的第2部分。即执行构造函数的函数体,这就是⑧处输出的来源。
析构函数的调用与构造函数的调用一样,也是类似的递归操作。但有两点不同,一是析构函数没有与构造函数相对应的初始化操作部分,这样析构函数的主要工作就是执行析构函数的函数体;二是析构函数执行的递归与构造函数刚好相反,而且在每一层的递归中,成员变量对象的析构顺序也与构造时刚好相反。
正是因为在执行析构函数时,没有与构造函数的初始化列表相对应的列表,所以析构函数只能选择成员变量在类中声明的顺序作为析构的顺序参考。因为构造函数选择了自然的正序,而析构函数的工作又刚好与其相反,所以析构函数选择逆序。因为析构函数只能用成员变量在类中的声明顺序作为析构顺序(要么正序,要么逆序),这样使得构造函数也只能选择将这个顺序作为构造的顺序依据,而不能采用初始化列表中的作为顺序依据。
与构造函数类似,如果操作的对象属于一个复杂继承体系中的末端节点,那么其析构函数也是十分耗时的操作。
因为构造函数/析构函数的这些特性,所以在考虑或者调整程序的性能时,也必须考虑构造函数/析构函数的成本,在那些会大量构造拥有复杂继承体系对象的大型程序中尤其如此。下面两点是构造函数/析构函数相关的性能考虑。
(5)在C++程序中,创建/销毁对象是影响性能的一个非常突出的操作。首先,如果是从全局堆中生成对象,则需要首先进行动态内存分配操作。众所周知,动态内存分配/回收在C/C++程序中一直都是非常费时的。因为牵涉到寻找匹配大小的内存块,找到后可能还需要截断处理,然后还需要修改维护全局堆内存使用情况信息的链表等。因为意识到频繁的内存操作会严重影响性能的下降,所以已经发展出很多技术用来缓解和降低这种影响,比如后续章节中将说明的内存池技术。其中一个主要目标就是为了减少从动态堆中申请内存的次数,从而提高程序的总体性能。当取得内存后,如果需要生成的目标对象属于一个复杂继承体系中末端的类,那么该构造函数的调用就会引起一长串的递归构造操作。在大型复杂系统中,大量此类对象的创建很快就会成为消耗CPU操作的主要部分。因为注意和意识到对象的创建/销毁会降低程序的性能,所以开发人员往往对那些会创建对象的代码非常敏感。在尽量减少自己所写代码生成的对象同时,开发人员也开始留意编译器在编译时"悄悄"生成的一些临时对象。开发人员有责任尽量避免编译器为其程序生成临时对象,下面会有一节专门讨论这个问题。语义保持完全一致。
(6)已经看到,如果在实现构造函数时,没有注意到执行构造函数体前的初始化操作已经将所有父类对象和成员变量对象构造完毕。而在构造函数体中进行第2次的赋值操作,那么也会浪费很多的宝贵CPU时间用来重复计算。这虽然是小疏忽,但在大型复杂系统中积少成多,也会造成程序性能的显著下降。
减少对象创建/销毁的一个很简单且常见的方法就是在函数声明中将所有的值传递改为常量引用传递,比如下面的函数声明:
...
int i = foo(a); ②
②处函数foo内部引用的变量a虽然名字与①中创建的a相同,但并不是相同的对象,两个对象"相同"的含义指其生命周期的每个时间点所指的是内存中相同的一块区域。这里①处的a和②处的a并不是相同的对象,当程序执行到②句时,编译器会生成一个局部对象。这个局部对象利用①处的a拷贝构造,然后执行 foo函数。在函数体内部,通过名字a引用的都是通过①处a拷贝构造的复制品。函数体内所有对a的修改,实质上也只是对此复制品的修改,而不会影响到①处的原变量。当foo函数体执行完毕退出函数时,此复制品会被销毁,这也意味着对此复制品的修改在函数结束后都被丢失。
通过下面这段程序来验证值传递的行为特征:
using namespace std;
class Object
{
public :
Object( int i = 1 ) { n = i; cout << " Object::Object() " << endl; }
Object( const Object & a)
{
n = a.n;
cout << " Object::Object(const Object&) " << endl;
}
~ Object() { cout << " Object::~Object() " << endl; }
void inc() { ++ n; }
int val() const { return n; }
private :
int n;
};
void foo(Object a)
{
cout << " enter foo, before inc(): inner a = " << a.val() << endl;
a.inc();
cout << " enter foo, after inc(): inner a = " << a.val() << endl;
}
int main()
{
Object a; ①
cout << " before call foo : outer a = " << a.val() << endl;
foo(a); ②
cout << " after call foo : outer a = " << a.val() << endl; ③
return 0 ;
}
before call foo : outer a = 1
Object::Object( const Object & ) ⑤
enter foo, before inc(): inner a = 1 ⑥
enter foo, after inc(): inner a = 2 ⑦
Object:: ~ Object() ⑧
after call foo : outer a = 1 ⑨
Object:: ~ Object()
可以看到,④处的输出为①处对象a的构造,而⑤处的输出则是②处foo(a)。调用开始时通过构造函数生成对象a的复制品,紧跟着在函数体内检查复制品的值。输出与外部原对象的值相同(因为是通过拷贝构造函数),然后复制品调用inc()函数将值加1。再次打印出⑦处的输出,复制品的值已经变成了 2。foo函数执行后需要销毁复制品a,即⑧处的输出。foo函数执行后程序又回到main函数中继续执行,重新打印原对象a的值,发现其值保持不变(⑨ 处的输出)。
重新审视foo函数的设计,既然它在函数体内修改了a。其原意应该是想修改main函数的对象 a,而非复制品。因为对复制品的修改在函数执行后被"丢失",那么这时不应该传入Object a,而是传入Object& a。这样函数体内对a的修改,就是对原对象的修改。foo函数执行后其修改仍然保持而不会丢失,这应该是设计者的初衷。
如果相反,在foo函数体内并没有修改a。即只对a执行"读"操作,这时传入const Object& a是完全胜任的。而且还不会生成复制品对象,也就不会调用构造函数/析构函数。
综上所述,当函数需要修改传入参数时,如果函数声明中传入参数为对象,那么这种设计达不到预期目的。即是错误的,这时应该用应用传入参数。当函数不会修改传入参数时,如果函数声明中传入参数为对象,则这种设计能够达到程序的目的。但是因为会生成不必要的复制品对象,从而引入了不必要的构造/析构操作。这种设计是不合理和低效的,应该用常量引用传入参数。
下面这个简单的小程序用来验证在构造函数中重复赋值对性能的影响,为了放大绝对值的差距,将循环次数设置为100 000:
#include < windows.h >
using namespace std;
class Val
{
public :
Val( double v = 1.0 )
{
for ( int i = 0 ; i < 1000 ; i ++ )
d[i] = v + i;
}
void Init( double v = 1.0 )
{
for ( int i = 0 ; i < 1000 ; i ++ )
d[i] = v + i;
}
private :
double d[ 1000 ];
};
class Object
{
public :
Object( double d) : v(d) {} ①
/* Object(double d) ②
{
v.Init(d);
} */
private :
Val v;
};
int main()
{
unsigned long i, nCount;
nCount = GetTickCount();
for (i = 0 ; i < 100000 ; i ++ )
{
Object obj( 5.0 );
}
nCount = GetTickCount() - nCount;
cout << " time used : " << nCount << " ms " << endl;
return 0 ;
}
类Object中包含一个成员变量,即类Val的对象。类Val中含一个double数组,数组长度为1 000。Object在调用构造函数时就知道应为v赋的值,但有两种方式,一种方式是如①处那样通过初始化列表对v成员进行初始化;另一种方式是如②处那样在构造函数体内为v赋值。两种方式的性能差别到底有多大呢?测试机器(VC6 release版本,Windows XP sp2,CPU为Intel 1.6 GHz内存为1GB)中测试结果是前者(①)耗时406毫秒,而后者(②)却耗时735毫秒,如图2-1所示。即如果改为前者,可以将性能提高 44.76%。
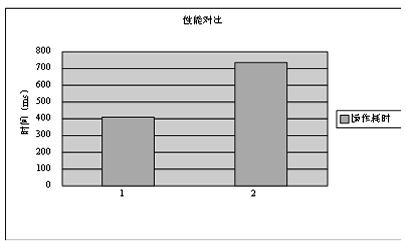
从图中可以直观地感受到将变量在初始化列表中正确初始化,而不是放置在构造函数的函数体内。从而对性能的影响相当大,因此在写构造函数时应该引起足够的警觉和关注。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









