






我是大熊!某大厂数据负责人。
文末分享:我如何5年就带团队了?
截图是我重读《大数据之路1》做的笔记。因为2看了一些,它已经发展到走出阿里的阶段,视野更开拓,而我越觉得自己基础不扎实,所以才有此重读。

读书的意义是把前辈的经验,映射到自己的环境去解决实际问题。
首篇:日志采集
它有什么资格放首位?我问自己。
业界公认电商平台玩的就是流量,核心就是做流量分配,因此我回看了阿里24Q4财报。

淘天集团Customer Service费用增长9%,达到人民币1007.9亿,很大部分就是通过搜索、推荐广告和营销服务来实现的。
而用户行为日志是推荐算法的核心数据,我之前在《Amazon如何设计出高效的数仓流量域模型?》画过一个基于用户行为的推荐链路,
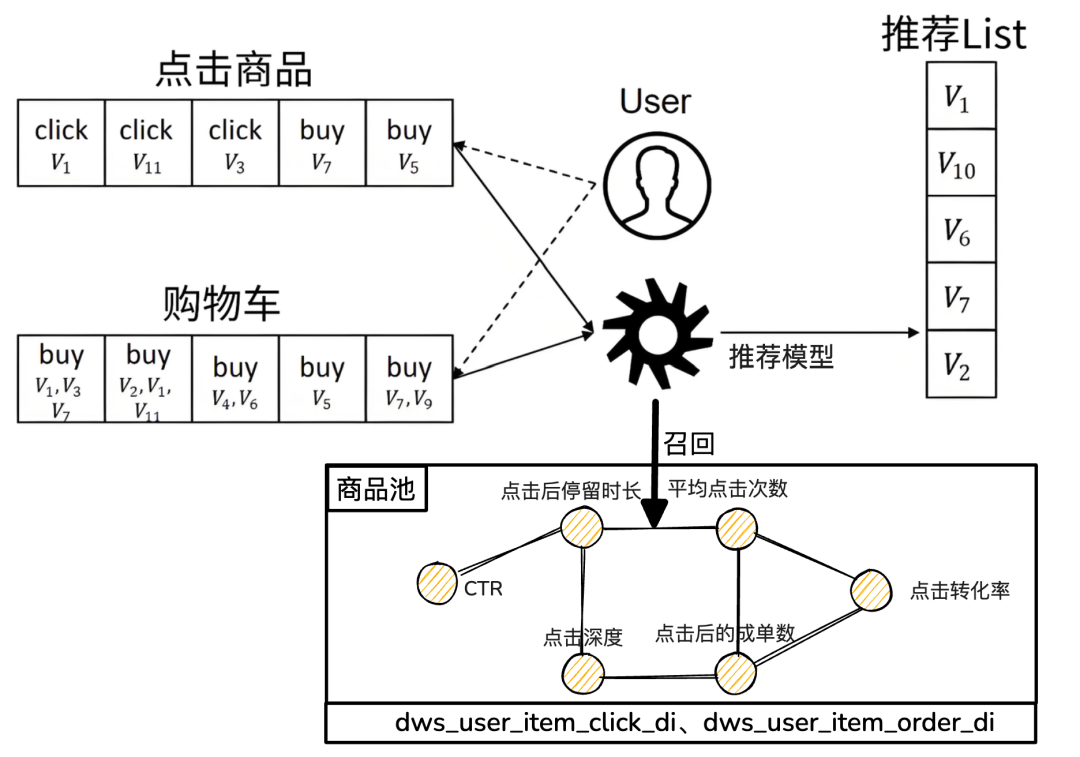
推荐的效率取决于用户行为日志的采集及时性和准确性,所以它活该放首篇。
继续阅读,埋点日志上报到kafka之后。
为什么电商平台尤其强调日志分流与用户行为治理?
我们先看他们做了什么事情:
识别流量攻击、作弊和爬虫
数据缺项补正
无效数据剔除
日志隔离分发
首先流量识别,我们也可以理解成打标签(Tag),先打标后处理,如何处理看不同部门的态度。
起步阶段,体量还小,作弊数据就是维持“表面生态繁荣”的的重要手段,哪怕用户不做,公司也有可能背后下场干这活。
成熟稳定阶段,那就必须打着“公平公正”的旗帜,避免劣币驱逐良币。
而打标的难点在于:定义延迟。
举个栗子🌰:连续几天重复下单才能被识别作弊,那之前作弊的事实已经产生,无法追溯。
再举一个栗子🌰:设备农场的用户通常会解压APK包串改信息,重新打包的签名不一致,都是事后检测。
作弊用户表和埋点流量表进行多流关联,关联不上就算了,不纠结!
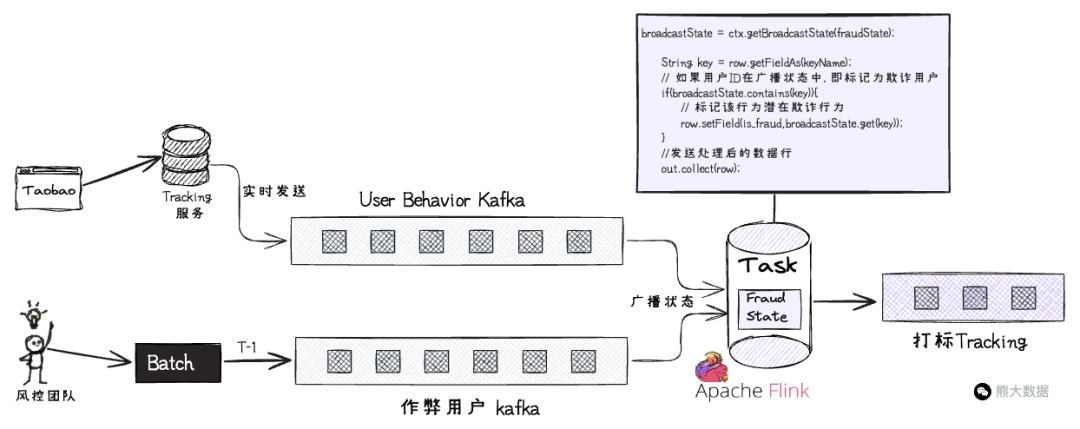
广播状态:作弊用户表存储于state中
这种关联和第五章的案例不一样,书本说的是做一旁路存储,通过外部存储来缓存,达到数据强一致性和备份恢复的目的。
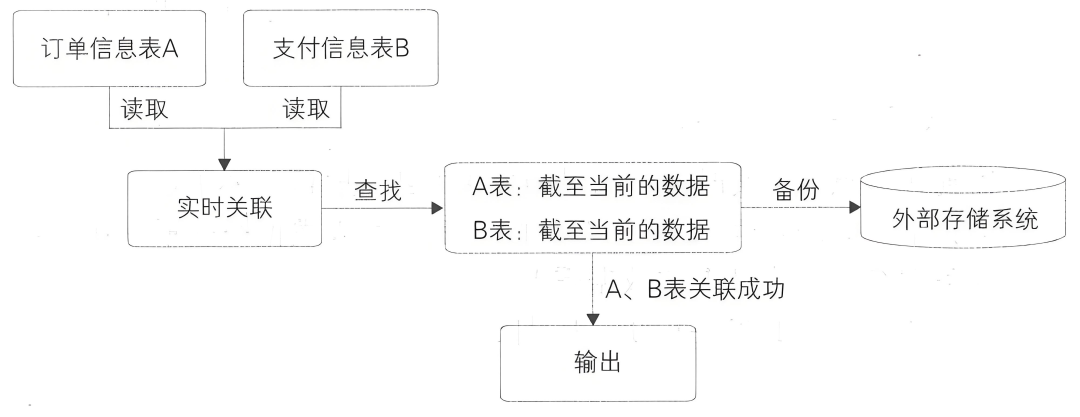
P83 原文截图
假设作弊用户的数据量比较小(10W规模),是可以通过状态来缓存。如果量级比较大,建议走外存Hbase或Redis,并小心设置:
lookup.cache.max-rows
lookup.cache.ttl
定期监控Hbase的命中率,如果命中率很低或Hbase被打爆,要及时调整缓存数量和TTL时间,同时也作为预警,及时和风控团队沟通攻击情况。
有一些骚操作,比如:遇到大量未登入用户也去频繁请求Hbase,提前过滤,避免去请求Hbase。
还有一些骚操作,比如:要给这些未登入用户打标,先给未登入用户设置userid = 9999,你再手动给Hbase插入一条9999的用户数据,这样可以缓存到状态里,避免未登入流量击穿外存。
数据缺项补正
这是一个很有趣的操作,为什么呢?我特么连缺什么字段都不知道,我咋补。
大部分埋点配置和上报缺少合理的校验,通常产品提的埋点需求是A,前端同学可以给你埋成B,还给你夹带一些私货 。
。
阿里和腾讯都有这种的埋点自动化校验和预警机制,但我相信99%的公司都没有。通常埋点会有这几种问题:
漏报1:产品要ABC,研发上报AB
漏报2:产品要ABC,研发上报ABC,但C空值超50%
夹私:产品要ABC,研发上报ABCD
...
还有好几种情况,在之前的小课《数据建模从设计到治理》有讲解,并实现了如何做埋点自动化检测。
一期的同学脑海赶紧回想那幅图!
标准化和反向补正
标准化很好理解,我们数据质量配置DQC的依据和规则来源。

往往谁话语权大,谁就是标准!
反向补正,书上说的是根据新日志对历史日志对个别数据做回补和修订,例如:用户登入后,对之前的日志做身份的回补,这个看情况,一般我们都将错就错。
数据分流
数据分流是流量治理的第一道屏障,它的本质是将海量数据的关联性、价值密度、消费时延进行分类解耦,避免无序数据冲击下游链路。
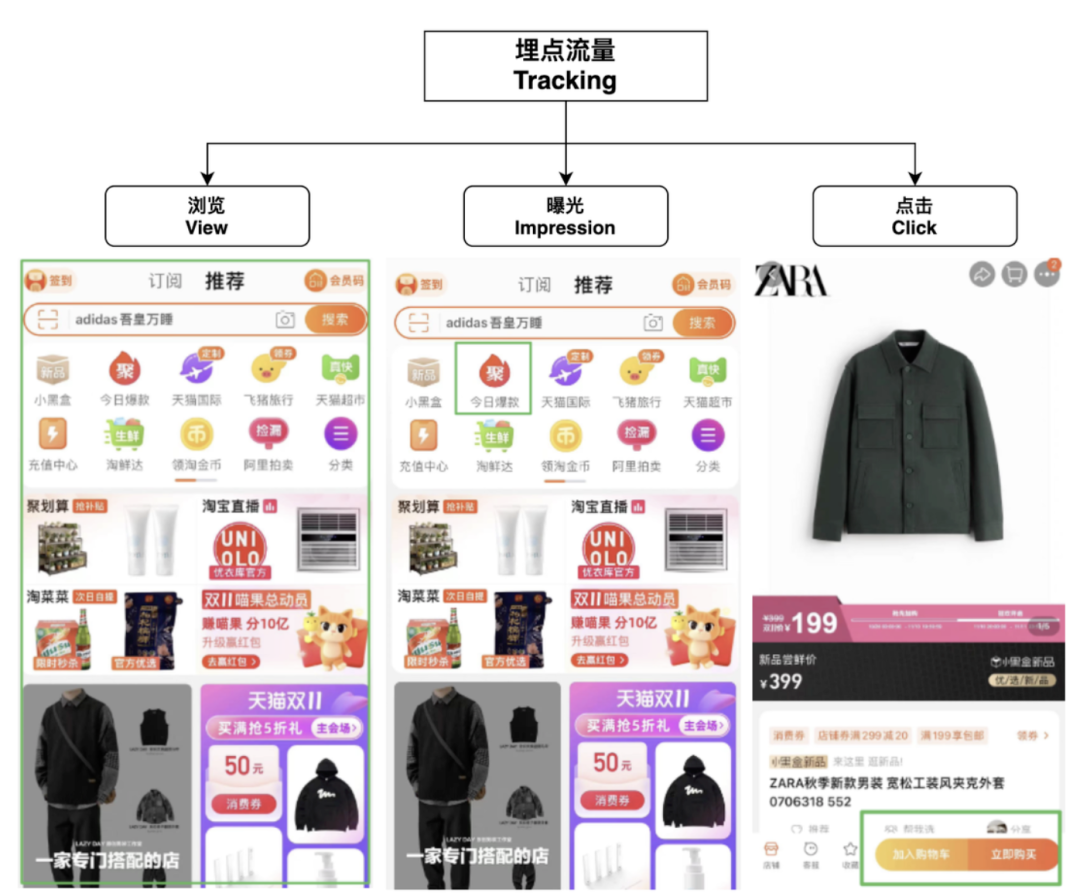
3类埋点流量数据
电商的短时热点流量集中爆发明显,晚上8点之后,登入淘宝的用户比较集中,就必须考虑业务分流(相互之间不应该存在明显的影响,爆发埋点不应该干扰正常业务日志处理),保持独立性的必要非常大。

根据业务线biz_id分流
另外对同一业务的日志优先级控制,也非常重要,比如:广告点击和曝光的扣费,一定是最高优的保障。
分流逻辑的核心诉求
在淘宝双十一场景中,每秒可能产生十亿级点击事件,但不同日志的消费价值存在明显差异。例如:
动作型日志(加购/收藏/支付)需100%准确性,直接驱动推荐样本生成
曝光型日志允许采样(如50%),用于大盘流量分析
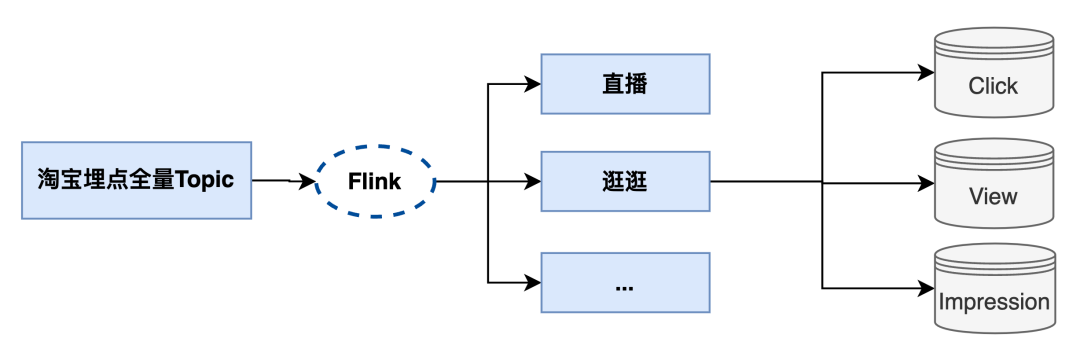
按业务分流后,再按埋点类型分流
这就要求在埋点SDK侧实现通道优先级策略,所以我们一些上报的策略可以这样来搞:
P0日志:单独高优通道,或后端单独接口进行上报
P1日志:正常上报,但高峰期接受限流和10分钟的延迟;
P2日志:延迟上报,日志缓存在客户端,恢复后在上传;
P3日志:采样上报,且采样不影响指标计算和反应实际情况才可以
。。。。
一不小心就2000字了,全书共4章,而我才到第一章的3/7进度,时间却来到了2点。

原创的道路是孤独的,关注的公众号或停更,或蹭热点带货,写干货的越来越少。
有人问我:数开3年经验如何40K?如何弯道超车?如何3年具备5年经验?
我说:这十年我写了237篇笔记呀 !不仅总结技术,也总结项目,甚至被老板骂,我也会总结复盘,或许这就是我5年管团队的原因吧。
!不仅总结技术,也总结项目,甚至被老板骂,我也会总结复盘,或许这就是我5年管团队的原因吧。

从OneNote->印象笔记->飞书

我现在想做件事
你付199元押金,加入【熊大笔耕不辍营】,连续创作3个月,押金全返。
你只需要保证每周1篇原创。
写SQL优化/复盘/技术思考/行业观察都行,无需考虑点击量,不在乎观点是否深刻,没有字数要求,要求一点也不高。
每周我会抽时间:
同步我的创作框架
定期点评你们的文章
失败案例比成功经验更有价值
这个时代不缺干货,缺的是敢于把思考落成文字的勇气


仅开放20个名额,实在精力有限。

加微信备注:熊大干货输出

每周2篇原创,分享大厂数据经验
<<< END >>>
往期精彩文章合集
【数据建模】
从业务到数仓-网约车平台Gra建模设计【数据性能优化】
【面试经验】
大熊啊
WHAT I WANT

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









