






我本身是想实现,爬虫保存搜索而来的图片的。

正常一套流程,获取本页面html中的图像链接之后进行下载
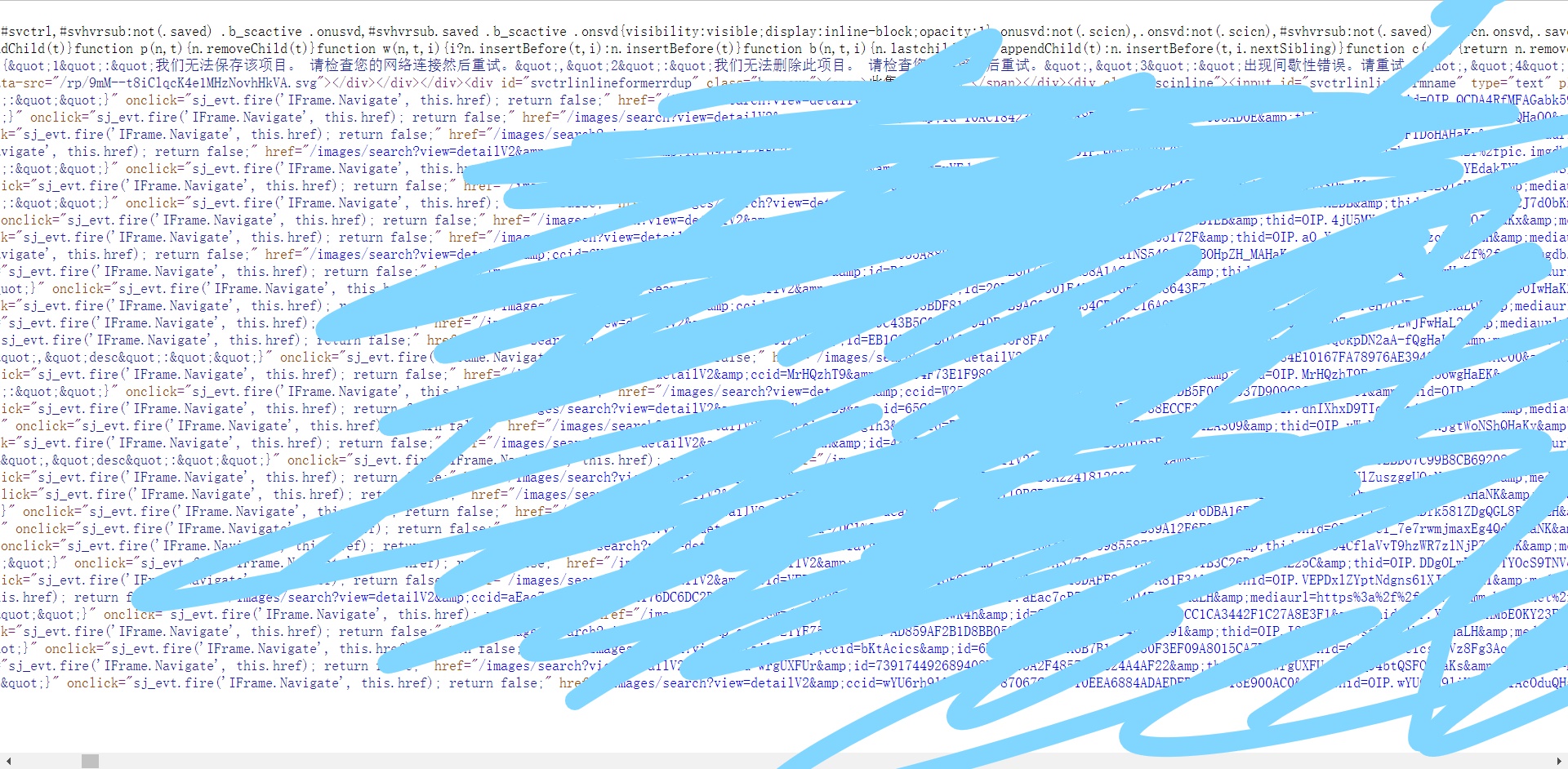
却发现下下来的图片无法显示,并且转过txt之后是一大堆页面源代码
后来发现,实际上搜索出来的图片库获取的图片链接不是真正的源图片链接,点进去实际上再查看单张图片,然后再在里面获取图片链接才是源图片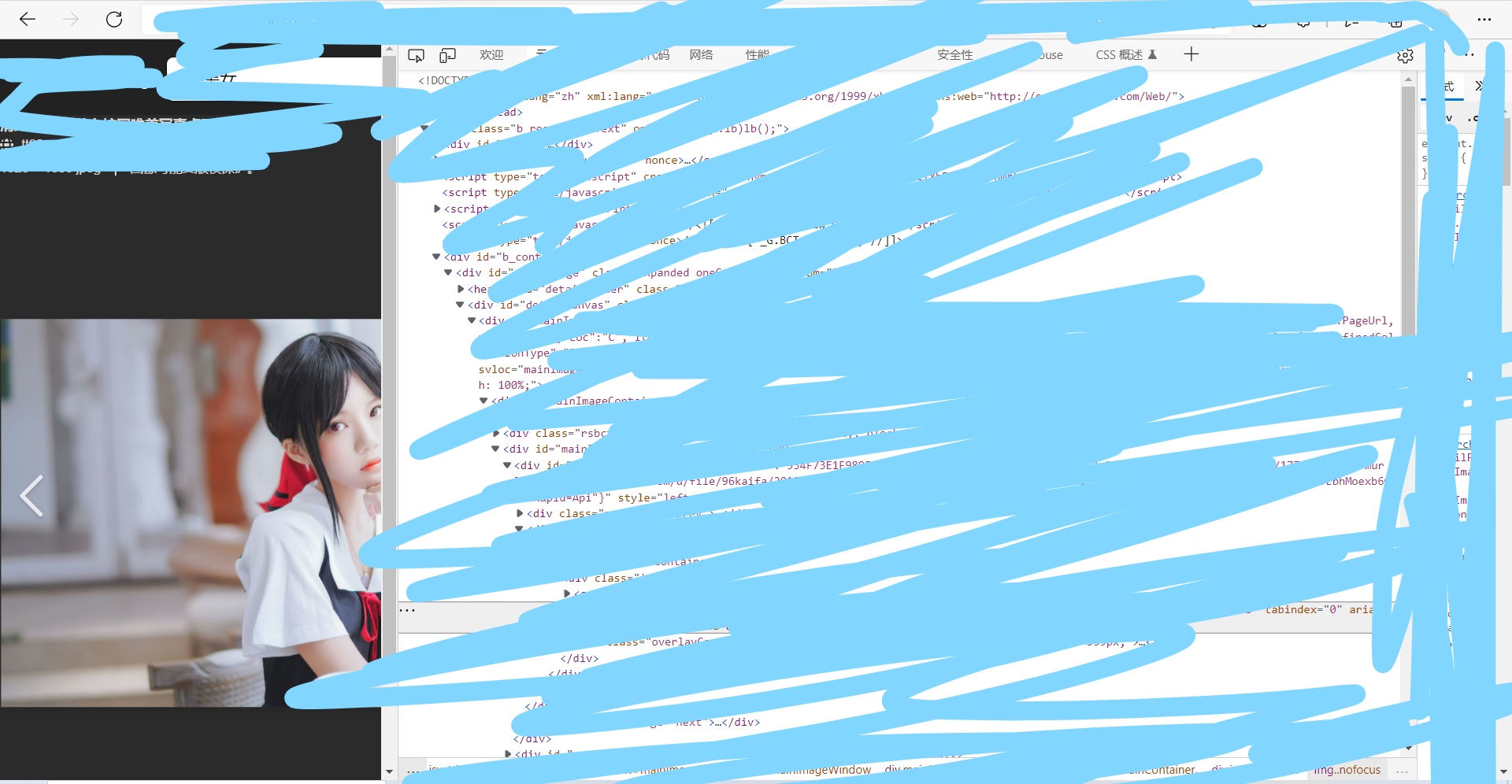
于是进一步获取此网页的源图片链接。自此问题解决
import requests
import urllib.request
import os
from bs4 import BeautifulSoup
import socket # 超时跳过
import urllib.error # 可能链接挂了
from tqdm import tqdm
def main(user_agent, noun, number, save_root):
"(1)初始化"
print("初始化...")
url = ...
headers = {
'user-agent': user_agent
}
opener = urllib.request.build_opener()
opener.addheaders = [('User-Agent', user_agent)]
urllib.request.install_opener(opener)
"(2)获取html"
print("获取html...")
response1 = requests.get(url=url,headers=headers)
html1 = response1.text
soup1 = BeautifulSoup(html1, 'html.parser')
divs = soup1.find_all('div', class_='imgpt') # 视具体网页而获取
"(3)获取图片链接"
print("获取链接与下载...")
count = 1
for div in divs:
# 不是源地址,再次获取
bing_url = '...' + div.find('a', class_="iusc").get('href')
try:
response2 = requests.get(bing_url, headers=headers)
html2 = response2.text
soup2 = BeautifulSoup(html2, 'html.parser')
# 视具体网页而获取
img_url = soup2.find('div', id="b_content").find('div', id='b_idpdata').get('data-firstimg')
img_url = img_url[img_url.index("thumbnailUrl")+len("thumbnailUrl")+3:img_url.index('fhs')-3]
# 准备
save_dir = os.path.join(save_root, noun)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
save_path = save_dir + '/%s-%d.jpg' % (noun, count)
"(4)下载"
socket.setdefaulttimeout(10)
try:
urllib.request.urlretrieve(img_url, save_path)
print("%s-第%d张下载完毕, from:%s" % (noun, count, img_url))
count += 1
except urllib.error.HTTPError:
print("链接挂了")
except socket.timeout:
try:
urllib.request.urlretrieve(img_url, save_path)
print("%s-第%d张下载完毕, from:%s" % (noun, count, img_url))
count += 1
except socket.timeout:
print("\n下载超时,跳过")
except urllib.error.ContentTooShortError:
try:
urllib.request.urlretrieve(img_url, save_path)
print("%s-第%d张下载完毕, from:%s" % (noun, count, img_url))
count += 1
except urllib.error.ContentTooShortError:
print("\n似乎网络不太好?已中断")
except:
print("未知错误,跳过")
except:
print("远程主机强迫关闭了一个现有的连接,跳过")
pass
if __name__ == "__main__":
user_agent = ...
amount = 10
save_root = 'images'
print("Download images from noun_vocab: ")
# noun_file = open('../../data/pororo_data/nouns_vocab.txt', 'r').readlines()
clean_noun_file = open('../../data/pororo_data/nouns_vocab_choose.txt', 'r+')
for line in tqdm(clean_noun_file):
noun = line.replace('\n', '')
main(user_agent, noun, amount, save_root)
clean_noun_file.close()













 1193
1193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









