







BP算法
又称为BP网络.BP学习算法是一种有效的学习方法,但由于在权值调整上采用梯度下降法作为优化算法,容易陷入局部最小,不能保证得到全局最优解。非循环多级网络的训练算法
弱点:训练速度非常慢、局部极小点的逃离问题、算法不一定收敛。
优点:广泛的适应性和有效性。
网络的构成
神经元的网络输入:
神经元的输出:
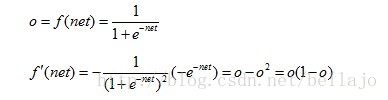
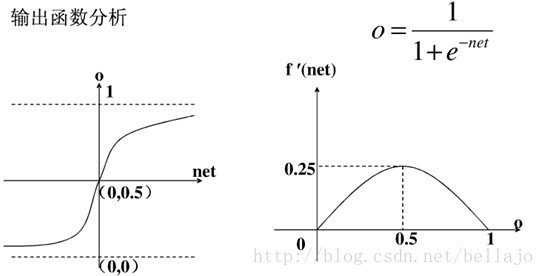
应该将net的值尽量控制在收敛比较快的范围内
可以用其它的函数作为激活函数,只要该函数是处处可导的
BP网络中是基于最小平方误差准则和梯度下降优化方法来确定权值调整法则。
网络的拓扑结构
1,BP网的结构
2.输入向量、输出向量的维数、网络隐藏层的层数和各个隐藏层神经元的个数的决定
3.实验:增加隐藏层的层数和隐藏层神经元个数不一定总能够提高网络精度和表达能力。
4.BP网一般都选用二级网络。
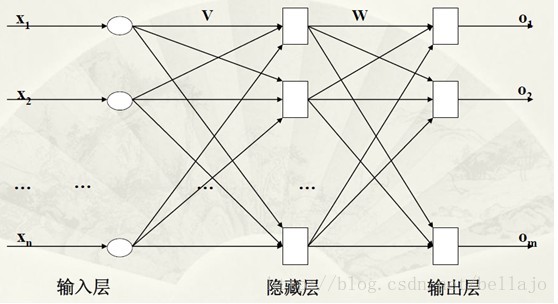
三层(两级)神经网络模型
算法的理论基础
基本假设
网络含有L层
联接矩阵: W(1) ,W(2) ,…,W(L)
第k层的神经元:Hk个
自变量数: n*H1+H1*H2+H2*H3+…+HL*m
样本集: S={ (X1,Y1),(X2,Y2),…,(Xs,Ys)}
用E代表E(P),用(X,Y)代表(XP,YP)
X=(x1,x2,…,xn)
Y=(y1,y2,…,ym)
该样本对应的实际输出为
O=(o1,o2,…,om)
误差测度
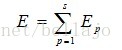
用理想输出与实际输出的方差作为相应的误差测度
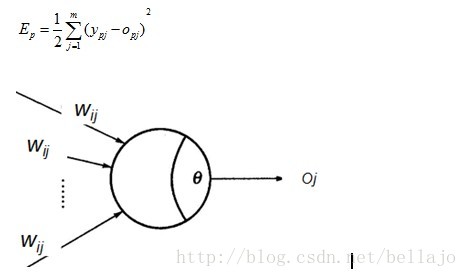
第K层(有Hk个神经元)隐含层和输出层神经元的操作:
输入整合:

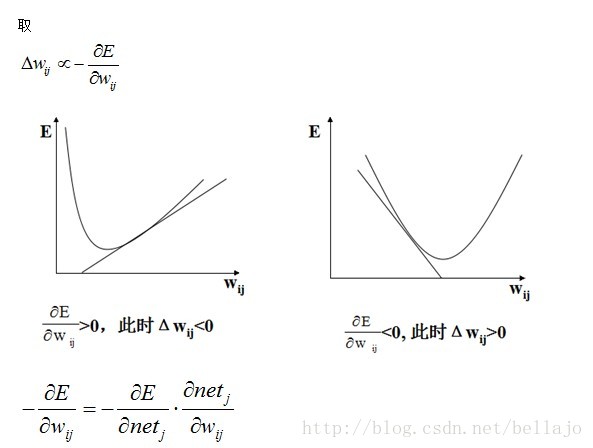
最速下降法,要求E的极小点
其中:
W(ij)=表示第k-1层神经元i与第k层第j个神经元j之间的连接权重。
Net(j)表示第k层神经元j的总输入
O(i)表示第k-1层神经元的输出

所以:



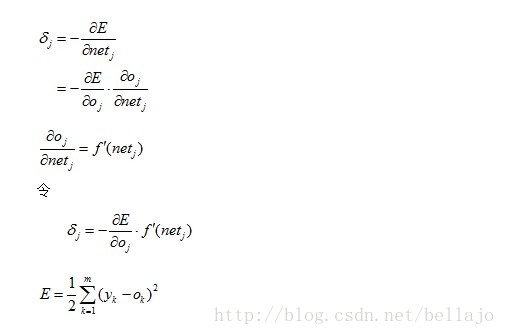
(注意:E始终是输出层的误差,即K是输出层的神经元,由于BP为三层网络,J是隐藏层的神经元,K是J的后一层,二者不在一层上,到此处为止公式与情况一相同)


也就是说,对于隐含层H的神经元j来说,将所有与之相连的输出神经元(或者是下一层的隐含层的神经元)k输出端的误差乘以对应的权值w(jk),并求和,作为隐含层神经元j的输出误差。所以这个过程也成为“误差反向传播”。
BP基本算法
For k= 1 to L do
初始化W(k);
//共有L层,初始化各层权值对各层的权系数W(Li) i=1,2...n
//置一个较小的非零随机数,
初始化精度控制参数ε;
E=ε+1;
while E>ε do
E=0;
对S中的每一个样本(Xp,Yp):
计算出Xp对应的实际输出Op;
计算出Ep;
E=E+Ep;
根据相应式子调整W(L);
k=L-1;
While k≠0 do
根据相应式子调整W(k);
k=k-1
E=E/2.0
BP网络的应用:
1)函数逼近:用输入矢量和相应的输出矢量村联一个网络逼近一个函数
2)模式识别:用一个特定的输出矢量将它与输入矢量联系起来
3)分类:把输入矢量以所定义的合适方式进行分类
4)数据压缩:减少输出矢量维数以便于传输或存储















 5836
5836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









