







云计算相关概念
首先做云计算平台的公司会买很多的物理机放在自己的数据中心中,再通过虚拟化的技术(如闭源的VMware,开源的Xen、KVM),将物理机分割成不同大小的资源(计算资源(CPU)、网络资源(带宽)、存储资源(硬盘))以满足不同用户的需求,如个人用户可能只需要一个CPU、1G内存、10G的硬盘、一兆的带宽
但是创建一台虚拟的电脑,需要人工指定这台虚拟电脑放在哪台物理机上的。这一过程可能还需要比较复杂的人工配置,所以仅仅凭虚拟化软件所能管理的物理机的集群规模都不是特别大,一般在十几台、几十台、最多百台这么一个规模。而几十上百万台机器要靠人去选一个位置放这台虚拟化的电脑并做相应的配置,几乎是不可能的事情,还是需要机器去做这个事情
所以人们发明了一种叫做调度(Scheduler)的算法,通俗一点说,就是有一个调度中心,几千台机器都在一个池子里面,无论用户需要多少CPU、内存、硬盘的虚拟电脑,调度中心都会自动在大池子里面找一个能够满足用户需求的地方,把虚拟电脑启动起来做好配置,用户就直接能用了。这个阶段称为池化或者云化
私有云:把虚拟化和云化的这套软件部署在别人的数据中心里面。使用私有云的用户往往很有钱,自己买地建机房、自己买服务器,然后让云厂商部署在自己这里
公有云:把虚拟化和云化软件部署在云厂商自己数据中心里面的,用户不需要很大的投入,只要注册一个账号,就能在一个网页上点一下创建一台虚拟电脑。例如AWS即亚马逊的公有云;例如国内的阿里云、腾讯云、网易云等
OpenStack:公有云第二名Rackspace和美国航空航天局合作创办了开源软件OpenStack,一个计算、网络、存储的云化管理平台。所有想做云的IT厂商都加入到这个社区中来,对这个云平台进行贡献,包装成自己的产品,连同自己的硬件设备一起卖。有的做了私有云,有的做了公有云,OpenStack已经成为开源云平台的事实标准
随着OpenStack的技术越来越成熟,可以管理的规模也越来越大,并且可以有多个OpenStack集群部署多套。在这个规模下,对于普通用户的感知来讲,基本能够做到想什么时候要就什么什么要,想要多少就要多少。还是拿云盘举例子,每个用户云盘都分配了5T甚至更大的空间,如果有1亿人,那加起来空间多大啊。其实背后的机制是这样的:分配你的空间,你可能只用了其中很少一点,比如说它分配给你了5个T,这么大的空间仅仅是你看到的,而不是真的就给你了,你其实只用了50个G,则真实给你的就是50个G,随着你文件的不断上传,分给你的空间会越来越多。当云平台发现快满了的时候(例如用了70%),会采购更多的服务器,扩充背后的资源,这个对用户是透明的、看不到的
IaaS(Infranstracture As A Service):到了这个阶段,云计算基本上实现了时间灵活性和空间灵活性;实现了计算、网络、存储资源的弹性。计算、网络、存储常称为基础设施Infranstracture, 因而这个阶段的弹性称为资源层面的弹性。管理资源的云平台,称为基础设施服务,也就是我们常听到的IaaS
PaaS(Platform As A Service):
- 自己的应用自动安装:安装的过程平台帮不了忙,但能够帮你做自动化,如用容器技术(Docker)
- 通用的应用不用安装:通用的应用可以变成标准的PaaS层的应用放在云平台的界面上。当用户需要时(如数据库),一点就出来了,用户就可以直接用了
大数据相关概念
数据的应用分为四个步骤:数据、信息、知识、智慧
最终的阶段是很多商家都想要的。你看我收集了这么多的数据,能不能基于这些数据来帮我做下一步的决策,改善我的产品。例如让用户看视频的时候旁边弹出广告,正好是他想买的东西;再如让用户听音乐时,另外推荐一些他非常想听的其他音乐
数据的处理分几个步骤,完成了才最后会有智慧
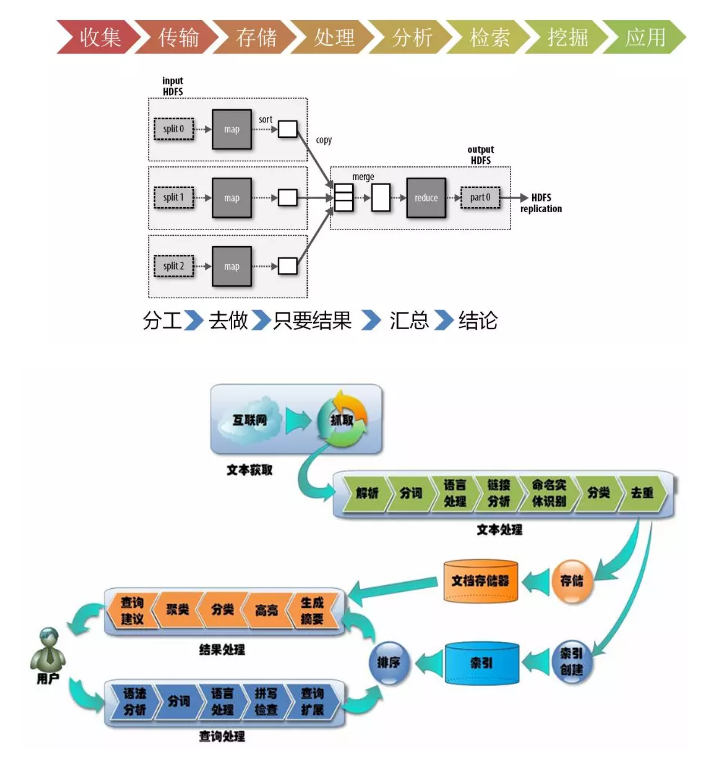
第一个步骤叫数据的收集。首先得有数据,数据的收集有两个方式:
- 抓取或者爬取
- 推送,如小米手环,可以将你每天跑步的数据,心跳的数据,睡眠的数据都上传到数据中心里面
第二个步骤是数据的传输
第三个步骤是数据的存储
第四个步骤是数据的处理和分析。通过清洗和过滤垃圾数据,得到一些高质量的数据。对于高质量的数据,就可以进行分析,从而对数据进行分类,或者发现数据之间的相互关系,得到知识
第五个步骤是对于数据的检索和挖掘
人工智能相关概念
机器是和人是完全不一样的物种,想要告诉计算机人类的推理能力是很难的,所以干脆让机器自己学习
基于统计学习:从大量的数字中发现一定的规律
统计学习比较容易理解简单的相关性:例如一个词和另一个词总是一起出现,两个词应该有关系;而无法表达复杂的相关性。并且统计方法的公式往往非常复杂,为了简化计算,常常做出各种独立性的假设,来降低公式的计算难度,然而现实生活中,具有独立性的事件是相对较少的
模拟大脑的工作方式:神经网络学习
人类的脑子里面不是存储着大量的规则,也不是记录着大量的统计数据,而是通过神经元的触发实现的,每个神经元有从其它神经元的输入,当接收到输入时,会产生一个输出来刺激其它神经元。于是大量的神经元相互反应,最终形成各种输出的结果
例如当人们看到美女瞳孔会放大,绝不是大脑根据身材比例进行规则判断,也不是将人生中看过的所有的美女都统计一遍,而是神经元从视网膜触发到大脑再回到瞳孔。在这个过程中,其实很难总结出每个神经元对最终的结果起到了哪些作用,反正就是起作用了
于是人们开始用一个数学单元模拟神经元。这个神经元有输入,有输出,输入和输出之间通过一个公式来表示,输入根据重要程度不同(权重),影响着输出。于是将n个神经元通过像一张神经网络一样连接在一起。n这个数字可以很大很大,所有的神经元可以分成很多列,每一列很多个排列起来。每个神经元对于输入的权重可以都不相同,从而每个神经元的公式也不相同。当人们从这张网络中输入一个东西的时候,希望输出一个对人类来讲正确的结果
学习的过程就是,输入大量的图片,如果结果不是想要的结果,则进行调整。如何调整呢?就是每个神经元的每个权重都向目标进行微调,由于神经元和权重实在是太多了,所以整张网络产生的结果很难表现出非此即彼的结果,而是向着结果微微地进步,最终能够达到目标结果。当然,这些调整的策略还是非常有技巧的,需要算法的高手来仔细的调整
神经网络的普遍性定理是这样说的,假设某个人给你某种复杂奇特的函数,f(x):不管这个函数是什么样的,总会确保有个神经网络能够对任何可能的输入x,其值f(x)(或者某个能够准确的近似)是神经网络的输出。如果这个函数代表着规律,也意味着这个规律无论多么奇妙,多么不能理解,都是能通过大量的神经元,通过大量权重的调整,表示出来的
人工智能可以做的事情非常多,例如可以鉴别垃圾邮件、鉴别黄色暴力文字和图片等。这也是经历了三个阶段的:
第一个阶段依赖于关键词黑白名单和过滤技术,包含哪些词就是黄色或者暴力的文字。随着这个网络语言越来越多,词也不断地变化,不断地更新这个词库就有点顾不过来
第二个阶段时,基于一些新的算法,比如说贝叶斯过滤等,你不用管贝叶斯算法是什么,但是这个名字你应该听过,这个一个基于概率的算法
第三个阶段就是基于大数据和人工智能,进行更加精准的用户画像和文本理解和图像理解
SaaS (Software AS A Service):软件即服务,人工智能算法多是依赖于大量的数据的,如果没有数据,就算有人工智能算法也白搭,而云计算厂商往往积累了大量数据的,于是就可以暴露一个服务接口,比如您想鉴别一个文本是不是涉及黄色和暴力,直接用这个在线服务就可以了
参考:
为什么说21世纪是一场ABC的革命?
作者:刘超














 5586
5586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









