







文章目录
前言
体能状态先于精神状态,习惯先于决心,聚焦先于喜好。
本文只提供基本概念
作为MySql学习的基础,本文不对二叉树、B-Tree、B+Tree的概念做深入介绍,如想深入了解,请自行查阅其他资料。
理解二叉树和相关变体
如果你理解二叉树相关的内容可以略过此部分
- 二叉树的特质 :简单来说,一棵树只有一个根节点,根节点有0-2个子节点,没一个自节点有0-2个子节点;
- 查询二叉树:如果二叉树中每一个左节点总是小于其右节点,那么这个二叉树就被称为查询二叉树——使用中序遍历二叉树可以得到一个有序的节点序列
- 平衡二叉树(AVL):又叫平衡二叉查找树。查询二叉树可能造成只有一个分支的树,导致查询效率降低为和线性队列一样,计算复杂度从O(log n)变为O(n),平衡二叉树会增加一个限制,每一个节点的子树的高度差最多相差为1,这样从图形来看,这个树总是趋于平衡的。
- 红黑树:红黑树是一种通过给节点增加颜色属性,并且通过一些规则最终实现——节点有序,且从任意一个节点,其两个子树的高度差不大于2倍的目标。
B-Tree
B Tree和B-Tree 是一个概念
由于翻译的缘故,国内习惯于把 B Tree 称为 B-Tree,本文使用 B-Tree进行描述
B-Tree 基本概念
B-Tree 是一种多路平衡二叉树
相比于二叉树,B-Tree 的每一个节点可以存储多个数据,并且每一个节点可以有多个子节点,其数据存储依旧是有序的
其性能逼近二叉查找树
下图(来自互联网https://www.jianshu.com/p/0371c9569736)
展示了一个简单的B-Tree,
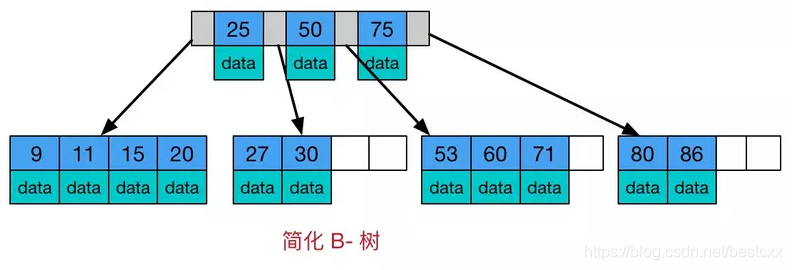
其实可以继续区分层级
B-Tree 是为了减少磁盘 I/O
看过上面的内容你应该可以明显的感觉到二叉树和B-Tree的区别,B-Tree 每一个节点存储了多个数据内容,这样的好处是,当数据存储在磁盘时,一次搜索可以得到多个数据,从而减少I/O交互次数,要知道 I/O的代价是很“昂贵的”相比于内存操作。
B+Tree
B+Tree 是对B-Tree的一个改进。
如果我们想要遍历B-Tree一定要通过根节点来进行一个中转。
B+Tree 为每一个子节点增加了索引内容,本子节点可以直接和下一个子节点连接,并且第一个子节点可以和最后一个子节点连接。
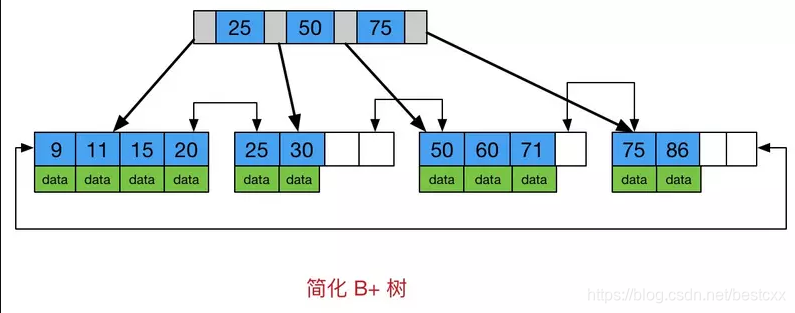
InnoDB 使用 B+树保存索引
平级节点之间可以相互关联,每一层的最前节点和最后节点可以关联,节点关联不是必须通过根节点.
非叶子结点只保存索引信息,对于主键索引叶子结点保存所有列数据——此时主键索引又被叫做聚簇索引,聚集索引
对于辅助索引,叶子结点保存主键值,如果需要列信息,则需要用该主键值做二次查询
如果是联合索引,规则和单列索引一样
主键索引和辅助索引的区别在于叶子节点,主键索引叶子节点存储所有行数据,辅助索引叶子节点存储主键的值(主键值太大会怎样?)
主键索引和辅助索引的非叶子节点,存贮自身索引和下一级索引。
MyISAM 使用 B+ 树保存索引
MyISAM索引同样使用B+树,区别在于,其主键索引和辅助索引在结构上并无区别,因为其行数据保存在单独的文件系统中,即非叶子节点存储本级索引和下级索引,叶子节点存储索引和行号(或者地址),行号指向文件系统中具体的某一列。
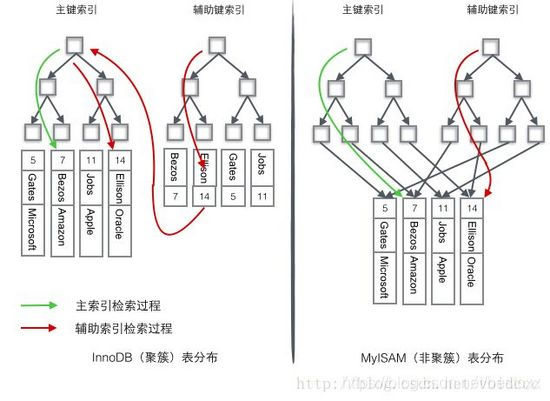
聚簇索引和非聚簇索引
图片来自互联网 https://www.cnblogs.com/usa007lhy/p/7001522.html?utm_source=itdadao&utm_medium=referral
左边是 InnoDB的主键索引和辅助索引
右边是MyISAM的主键索引和辅助索引
参考链接
[1]、https://segmentfault.com/a/1190000014037447
[2]、https://blog.csdn.net/chuixue24/article/details/80027689














 449
449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









