







网页包含三个层次(没错,它们都需要各自分离):
3layers
- HTML结构
- CSS表现
- JavaScript行为
HTML结构层是网页最重要的基础。HTML标签给予内容含义。CSS表现层则是定义您的HTML该如何显示。JavaScript行为层为页面增加交互。
不管如何,一个网页必需HTML结构层。没有HTML,没有网页。CSS和JavaScript都是可选项,旧的,无名的,罕见的浏览器可能不支持 CSS和/或JavaScript,在这种情形下,这两层或其中一层都不起作用。后果是显而易见的,任何网站应能在行为层(或者表现层,但这种情形相比较少)的缺席下还能“存活”。也就是说,网站不能完全依赖于JavaScript,但要保证无障碍即使JavaScript不起作用。
分离的关系
一般来说,最好单独管理好每一层。最基础的,确保:
- HTML是结构性的,不要太复杂,没有CSS和JavaScript下保持语义。
- CSS表现层和JavaScript表现层分别归属于独自的
.css和.js文件。
分离更容易维护。您可以轻而易举地把分离的文件连接到整站的网页上,简单举个例子,您需要把字体从12px改成0.8em,您只需打开CSS文件编辑它,这样网页变化即刻生效。除此之外,分离让您可以不需修改HTML结构层或者JavaScript行为层,只需修改整个CSS表现层就可让网站换上新衣。
CSS盒子模型是为了设计表现(布局)的:
内容(CONTENT)就是盒子里装的东西;
而填充(PADDING)就是怕盒子里装的东西(贵重的)损坏而添加的泡沫或者其它抗震的辅料;
下面是Box Model的图示:
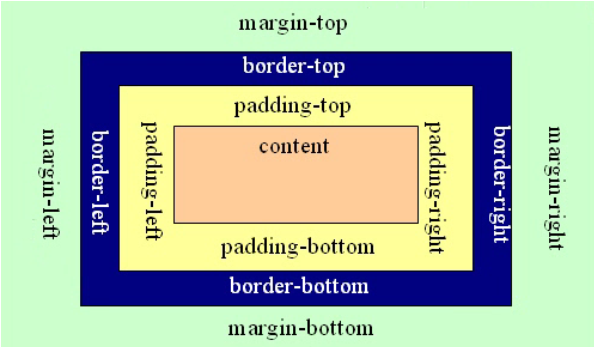
Box-Model 1
说明:上图中,由内而外依次是元素内容(content)、内边矩(padding-top、padding-right、padding- bottom、padding-left)、边框(border-top、border-right、border-bottom、border- left)和外边距(marging-top、margin-right、margin-bottom、margin-left)。
内边距、边框和外边距可以应用于一个元素的所有边,也可以应用于单独的边。而且,外边距可以是负值,而且在很多情况下都要使用负值的外边距。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









