







一、概述
当前KV数据库从存储介质可以分为两种模式,一种是以内存为主持久化为辅,如memcache(无持久化)、Redis等;一种是以持久化为主内存为辅,如ssdb(基于leveldb/rocksdb存储引擎)。这两种模式代表了两种不同的选择策略和哲学,适应不同的业务场景。简单地说,以内存为主的模式侧重高性能,信奉“内存是新的硬盘”的哲学;以持久化为主的模式则侧重大容量,兼顾性能。
对于以持久化为主的模式,因其天然支持大容量数据的快速读写,实现冷热数据分离是相对比较容易的,当前用到的数据就认为是热数据,只要把热数据保留于指定大小的内存即可。而对于以内存为主的模式,即使有持久化,也只是顺序写的持久化,在需要读硬盘时不能做到快速读取。因此这种模式要实现冷热分离,需要准确区分冷热数据、精心设计落地策略并保证可以快速读取。
这里冷热分离方案主要基于redis或者基于redis协议及命令实现。
二、方案汇总
2.1 方案一 改造redis,使之支持冷热分离
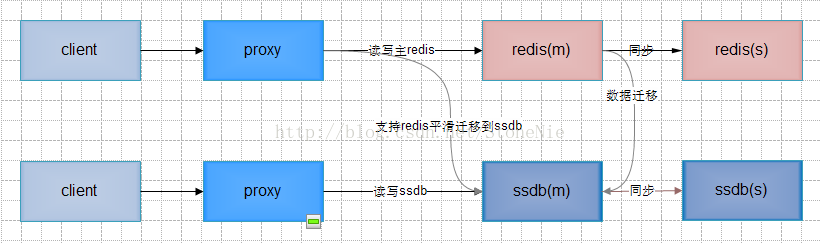
l 实现描述:
ü 可以使用开源的rocksdb或lmdb引擎读写落地数据;
ü 写操作全部记录在内存,不同步写磁盘;
ü 常驻写子进程定时将内存中的数据写到磁盘;
ü 内存中标记不存在的key,如果一个key在磁盘上不存在,则在标记之后不用再去磁盘查看这个值是否存在;
ü 读操作先读内存,如内存中不存在且key未被标识磁盘不存在,则由读子进程从磁盘读并写回到redis(key不存在才写回)。之后子进程通知主进程再次读取,此过程会阻塞主进程上单个连接的处理。
l 优点:真正意义上实现单机redis的冷热分离。Redis和落地数据在同一台机器,容易保证数据一致性。
l 缺点:实现较复杂。因为是基于redis做二次开发,后续不方便升级redis,不过单机redis已经非常稳定,后续升级可能性较小。
l 分析:
redis定位是内存KV数据库,只支持所有数据存放在内存,持久化只是数据安全性的一种保障方式。基于redis做冷热分离的例子有两个,一个是v2.0-2.4版的原生redis,一个是jimdb S,这两个做得都不成功。
redis 2.0版加入支持VM机制,VM机制即虚拟内存机制,参考操作系统的虚拟内存机制实现,暂时把不经常访问的数据从内存交换到磁盘中,需要时再从磁盘交换回内存,可以实现冷热数据分离。但由于VM机制在某些情况下会导致redis重启、保存和同步数据等太慢及代码复杂,所以2.4版后就不再支持了。
Jimdb S是京东云平台基于redis2.8实现的KV数据库,用SSD持久化数据。使用Jimdb S可以保存全量数据,把缓存+数据库的两层架构用一层架构取代。写操作时先写内存,再异步写cycledb。读操作如数据不在内存,则创建后台任务读cycledb。这个后台任务的作用是预热,读到数据后并不把结果载入内存,执行完成后由前台主线程再次读取,这次在内存中读不到则直接读取cycledb并载入内存。目前了解到的情况是使用不广泛,而且即将下线。主要原因是性能不如纯内存的redis,但不知道是否还有其它缺陷。
从以上redis删除VM机制和jimdb S的实践情况看,直接改造redis做冷热分离可能并不是一个很好的发展方向,即使做出来也很可能是一个平庸的产品。最根本的原因是纯内存的redis性能更好,而用户对性能的期望是没有最好,只有更好。随着内存越来越大、越来越便宜,更多的数据可以直接放到内存,会进一步导致冷热分离成为一个鸡肋功能。另外一个原因是实现冷热分离会导致redis代码复杂性增加不少,不利于后续的维护。
方案二 改造备redis和proxy,备redis落地数据
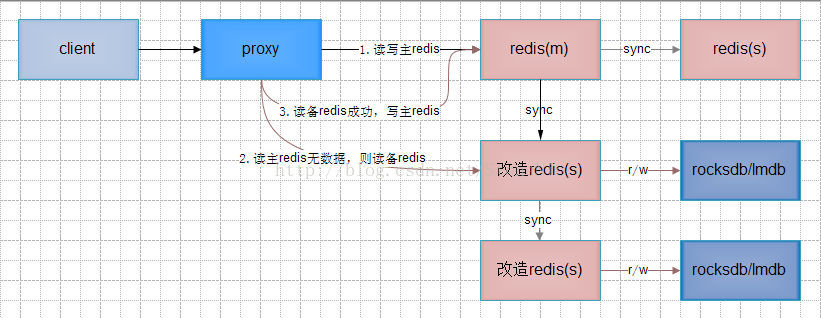

l 实现描述:
ü 写操作时proxy正常写主redis,由改造备redis写rocksdb;
ü 读操作时proxy先正常读主redis,如无数据,则读改造备redis;改造备redis在内存中读不到数据则读rocksdb,proxy从改造备redis读到数据再写主redis。
l 优点:写操作和当前流程完全一样;读操作和当前迁移流程中rrw流程基本一致,可以复用。不影响纯内存的原生redis使用,风险可控。
l 缺点:proxy和redis均需修改。在原有一主一备redis基础上需要增加改造备redis部署。
l 分析:
最大特点是不影响纯内存的原生redis使用,且proxy改动较小。
可以视情况选择部署一个或两个改造备redis。只部署一个改造备redis时落地数据是单点,可用于数据丢失不重要或后端另存有全量数据的场景。部署两个改造备redis可以避免单点,因为是链式同步,对主redis几乎无影响。
方案三 改造proxy,使用ssdb落地数据
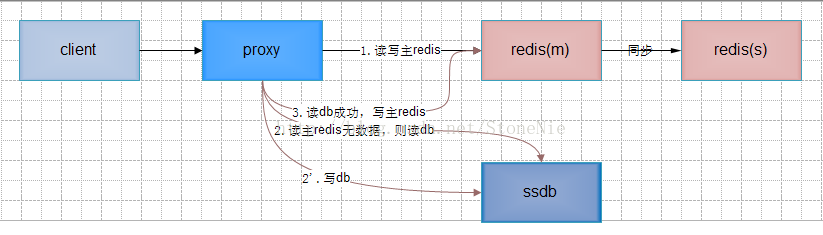
l 实现描述:
ü 写操作时proxy先正常写主redis,再同步或异步写ssdb;
ü 读操作时proxy先正常读redis,如redis无数据,则读ssdb;读ssdb成功,再写主redis。
l 优点:只改proxy,redis无须改动。
l 缺点:proxy实现较复杂,redis和ssdb的数据一致性不好保证。因为ssdb基于leveldb/rocksdb实现,在读操作且redis中无数据且ssdb内存中无数据时,可能极大影响性能。
方案四 提供ssdb,业务选择接入redis或ssdb
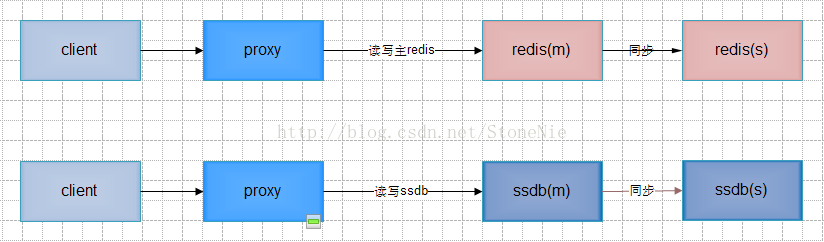
l 实现描述:redis和ssdb独立两套系统,类似之前腾讯提供CMEM和TSSD两套系统。业务开发根据业务特点决定使用哪一套系统。client、proxy可以复用,等同可以选择使用redis存储引擎或leveldb/rocksdb存储引擎。
l 优点:无须开发,只需引入ssdb系统即可。
l 缺点:业务开发可能没办法一开始确定使用哪一套系统。需要维护和运维两套系统。
方案五 提供ssdb,业务初始接入redis,可选择平滑迁入ssdb

l 实现描述:类似方案四,但可选择从redis平滑迁入ssdb。
l 优点:只需开发proxy支持迁入 ssdb系统即可。
l 缺点:需要维护和运维两套系统。
三、通用问题
l 读操作且redis中无数据的性能问题
不管是直接基于leveldb/rocksdb做数据落地,还是使用ssdb,都会碰到读操作且redis中无数据的性能问题,因为此时需要先读取redis,redis中读不到再一个level一个level去读取磁盘文件,这种情况的性能可想而知不会太好。
l Redis的淘汰
redis区分冷热数据都是设定redis的maxmemory,然后进行lru淘汰使内存中只保留热数据,而Redis的lru淘汰只是从随机选的一些key选出最符合lru规则的一个key进行淘汰,即只是一种近似淘汰,所以不能很好地区分冷热数据。因此有可能出现被lru淘汰的key实际并不是冷数据,这样下次读取时会因为redis中已无数据而去磁盘读,出现一些性能问题。
l 写操作先写内存还是先写磁盘?
先写内存,此时如果系统崩溃,内存中的数据还没有来得及Dump到磁盘,会丢失数据。先写磁盘,再写内存,则即使系统崩溃,不会造成数据的丢失,但可能导致磁盘和内存数据的不一致,为了避免这种不一致,又得先删除内存中的key,再写磁盘,再写内存,影响性能。总的来说,对于以内存为主的KV数据库,优先选择先写内存。
l SSD应用风险
为了提高读写磁盘的性能,需要使用SSD。而SSD本身存在一些问题——
• 毛刺问题:同时读写SSD盘时,读SSD盘有可能会耗时数秒。被挂住的几率为万分之一;
• 坏盘问题:SSD坏盘几率比普通sas硬盘要高;
• 坏块问题:SSD盘中可能存在某个块可以写入,但是读不出来,此时这个块的数据将会丢失。
四、总结和建议
总的来说,基于redis做冷热分离从技术上是可行的,从业务实用角度看却不一定。因为首先redis不能很好区分冷热数据,然后很难避免读取落地冷数据时的性能问题,因此肯定不如纯内存的redis性能好,而用户对KV数据库性能的期望是没有最好,只有更好。随着内存越来越大、越来越便宜,更多的数据可以直接放到redis内存,会进一步导致冷热分离成为一个无人使用的鸡肋功能。
最理想的冷热分离是redis能够满足如下三个条件:
l lru淘汰做到淘汰的是最冷数据;
l 只在lru淘汰时落地冷数据;
l 能快速从磁盘读取冷数据并写回到内存。
这样就能在maxmemory足够时完全是纯内存KV数据库模式,不受冷数据落地的丁点影响;而在maxmemory满时进入冷热数据分离模式,又能在设大maxmemory时恢复纯内存KV数据库模式。当然要达到这个目标非常难。
从实际考虑,当前有业务确实想要冷热分离的话,建议方案四,即提供两套KV系统——以内存为主的redis系统和以持久化为主的ssdb系统,根据业务特点选择使用。考虑现有已使用redis的业务需要迁到ssdb的话,则优先选择方案五。
五、附录
附各C/C++持久化KV数据库简介和分析:
l Leveldb
LevelDb是google开源的能够处理十亿级别规模KV型数据持久性存储的C++程序库。LevleDb在存储数据时,是根据记录的key值有序存储。LevelDb的写操作要大大快于读操作,而顺序读写操作则大大快于随机读写操作。
level一个写操作仅涉及一次磁盘文件追加写和内存SkipList插入操作,因此leveldb的写操作非常高效。
由于 LevelDB 在某一层查找不存在的数据时, 会继续在下一层进行查找, 所以对于不存在的数据的查找会速度非常慢. 所以, 需要结合 Bloom Filter, 利用 Bloom Filter 能快速地判定”不存在”的特点。
l Rocksdb
Facebook 维护的一个活跃的 LevelDB 的分支。RocksDB 在 LevelDB 上做了很多的改进,比如多线程 Compactor、分层自定义压缩、多 MemTable 等。另外 RocksDB 对外暴露了很多配置项,可以根据不同业务的形态进行调优。
l Lmdb
LMDB 选择在内存映像文件 (mmap) 实现 B+Tree,而且同时使用了 Copy-On-Write 实现了 MVCC 实现并发事务无锁读的能力,对于高并发读的场景比较友好;同时因为使用的是 mmap 所以拥有跨进程读取的能力。
l Ssdb
基于leveldb/rocksdb存储引擎实现,加入网络支持,兼容redis协议和redis数据类型(不支持set集合),支持主从复制和负载均衡。SSDB/LevelDB 在进行数据库整理(Compaction)操作时, 磁盘io高,持续的时间一般随着数据变大而变长, 一般只持续数秒。不能指定执行compaction的时间。有些redis命令不支持,有些支持的redis命令可能不完全和redis一致。
l Mangodb
分布式文档数据库。MongoDB的最大卖点是不需构建非主键索引也能执行很多查询。
l Fatcache
SSD上实现的memcached,内存中保存索引数据,机器重启索引数据会丢失。假如只需要支持string类型数据落地,可使用代替ssdb。
l Tair
淘宝开源的分布式KV数据库。抽象存储层的架构设计使Tair很容易接入新的存储引擎,当前支持的存储引擎有非持久化的MDB(自主研发的类memcache)/RDB(抽离Redis的存储部分),持久化的LDB(接入LevelDB)。
l TTC
非严格意义上的KV数据库。支持无数据源和持久数据源两种工作模式。无数据源模式就是一个简单的基于共享内存的cache服务。持久数据源后接MySQL,写操作先写db,再写内存;读操作先读内存,内存中不存在再去读db,读db成功再添加到内存。所以TTC本质上是一个带缓存功能的mysql数据库,可以想见其读写性能肯定不如纯内存数据库,也没有leveldb高效写的特点,注定是一个平庸的产品,再加上使用繁琐,早已被淘汰。
l CMEM
分布式KV内存数据库,支持主从同步和平滑迁移,数据可落地,高性能。仅做KV缓存还不错,但支持数据类型和命令不如redis丰富。















 1649
1649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









