




一、大数据血缘整体介绍
1.背景&目标
随着公司业务的不断扩展,进入大数据平台的业务数据日益增多,数据之间的产出与使用关系变得愈发复杂。元数据血缘的建设是理清这些复杂数据关系的最佳途径,它不仅能够明确数据的来源、流向和变更历史,向用户清晰明了的展示出数据之间的依赖关系,还为数据平台内的数据治理、数据质量和数据安全提供了重要的支持。
在元数据血缘建设的初期,血缘信息分散在数据同步、数据开发、数据应用等各个业务模块。每当用户需要对数据进行改造/治理时,往往需要分别从各业务模块收集数据实体被下游业务方使用或依赖的情况,最终汇总评估改造/治理成本。如果遗漏了某个模块的血缘数据,可能会在改造/治理过程中对下游业务造成不可预见的影响;在数据质量方面,数据平台需要对用户提供数据产出的基线保障,如果无法全局盘点出保障任务的上游链路会导致基线保障不准确,无法将高优资源给到相应的保障任务;在数据安全方面,数据平台需要利用全链路血缘对敏感数据入仓和使用进行监控,防止敏感数据在流转、加工和使用过程中出现未授权访问、违规流转或泄露等风险,确保数据在全生命周期内的合规性和安全性。
因此,我们着手对元数据血缘进行统一收口,推动各业务模块将血缘信息集中上报和采集,汇聚到统一元数据血缘平台。通过对大数据平台内整个数据加工链路的血缘关系进行统一抽象、统一建模和统一存储,使用户和数据平台服务能够从全局视角便捷地洞察和分析数据的加工流转关系,高效的利用元数据血缘。
2.数据加工全链路
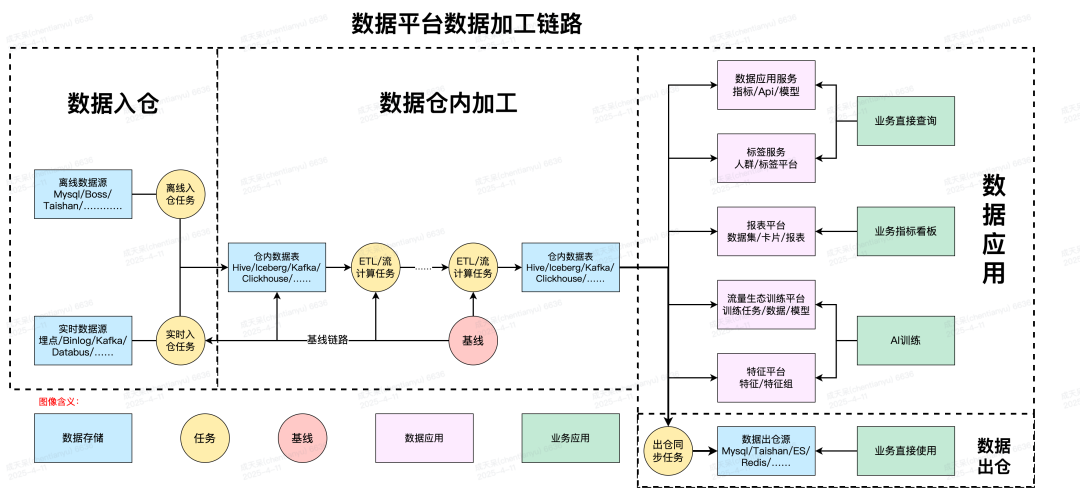
数据加工链路分为3个阶段:
-
数据入仓:
-
埋点数据:主要来源于APP端、WEB端和服务端埋点,这些埋点以消息的方式进行上报,通过实时入仓任务解析后进入到数据平台。
-
业务数据:主要来源公司各业务平台的业务数据,主要来源于Mysql、TiDB、Boss、Taishan等业务存储,最终将数据同步到Hive/Clickhouse等数据平台存储中。
-
数据仓内加工:
-
离线加工:用户可以通过Spark Sql、Spark Jar、Presto Sql、python脚本等方式对仓内数据进行ETL加工。
-
实时加工:用户可以通过Flink Sql、Flink Jar等方式对仓内实时数据(Kafka)进行ETL加工。
-
数据应用/数据出仓:
-
数据应用:业务将最终加工出来的数据应用到各个场景中进行使用,有指标服务、报表平台、AI训练等等场景中。
-
数据出仓:业务也可以将仓内加工好的数据同步回业务自有的业务存储中,对数据进行再使用。
从上面数据加工链路来看,其实就是大数据平台数据加工的核心链路血缘,从数据入仓开始一直到数据被应用,我们需要对其中每个数据加工的过程都进行解析和获取,从而获取到数据完整的使用链路,使得数据血缘应用场景有更全面和更加精准。
3.血缘模型
在血缘模型设计层面,我们采用通用性模型架构实现对数据平台全加工链路中多维度血缘关系的覆盖,通过统一范式进行标准化存储,确保模型具备良好的可扩展性和复用性。
经过持续迭代优化,最终沉淀出两套标准血缘模型。当前平台已覆盖的所有血缘类型均可通过该模型体系进行精准描述,为各类血缘关系的规范化管理和高效应用提供统一框架。

模型一:
用于数据加工产出链路,主要用于有明确数据加工的血缘场景,其中source和target是实体对应的点,而builder则是加工逻辑中对应的边,从而构成了完整数据加工血缘;
模型二:
用于2个实体之间的依赖(或者说某一个实体来源于另一个实体),其中target(builder)依赖或者来源于source实体;
有了上面2套血缘模型,我们可以将所有解析到的血缘铺平存储到我们的关系型存储中,后续用于查询和同步图数据库。
4.血缘演进
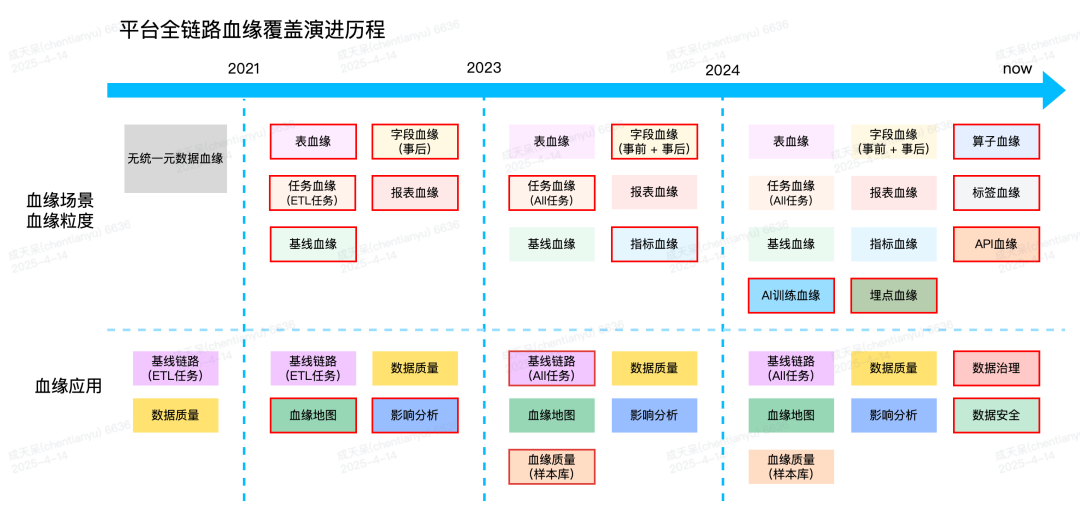
数据平台统一元数据血缘的建设与整合自2021年启动,平台根据血缘覆盖的业务场景和粒度差异,分阶段、按需推进血缘体系的完善。随着血缘覆盖范围和细致度的不断提升,平台同步推出了多样化的血缘应用,助力业务用户更加直观、高效地利用血缘信息,全面提升数据治理与业务支撑能力。
根据上图,我们可以将血缘覆盖的历程分为4个阶段:
2021年之前:(血缘混沌时期)
在缺乏统一元数据血缘管理的情况下,表级血缘信息分散存储于各业务方的系统服务中。若需统计某张表的血缘关系,往往需要分别向各业务方的业务数据库逐一查询,过程繁琐且耗时,极大降低了查询效率和使用便捷性。
2021年 - 2023年:(初步建立血缘体系)
从零开始搭建统一的元数据血缘系统,统一采集各业务方的表级数据血缘。平台通过统一的元数据血缘服务,依据血缘模型规范对业务上报的血缘信息进行解析与入库,实现了对表级血缘及引擎执行后字段级血缘的全面覆盖。
在血缘应用层面,数据平台提供了血缘地图和影响分析等功能模块,用户可自主在相关模块中便捷查询和分析数据血缘关系,助力数据流转全链路的可视化与影响追溯。
2023年 - 2024年:(血缘体系的扩展和优化)
依托各业务方上报的表级数据血缘,平台将不同类型的任务通过表级数据血缘进行串联,构建了完整的任务依赖血缘网络,为数据平台的质量基线建设和全链路任务完成情况监控提供了坚实基础。
在字段血缘方面,平台利用基础架构的Sqlscan服务实现了事前解析,无需引擎实际执行SQL即可快速获取字段级血缘信息,显著提升了血缘解析的实时性。
同时,我们高度重视血缘解析的准确性,调研业界最佳实践后,采用血缘样例库机制收集和管理bad case。用户可将存在解析误差的SQL录入样本库,平台根据用户反馈的错误样本进行分析与修正,并将修正后的准
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 626
626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









