







SIMD及NEON概览
SIMD
Single Instruction Multiple Data (SIMD)顾名思义就是“一条指令处理多个数据(一般是以2为底的指数数量)”的并行处理技术,相比于“一条指令处理几个数据”,运算速度将会大大提高。它是Michael J. Flynn在1966年定义的四种计算机架构之一(根据指令数与数据流的关系定义,其余还有SISD、MISD、MIMD)。
许多程序需要处理大量的数据集,而且很多都是由少于32bits的位数来存储的。比如在视频、图形、图像处理中的8-bit像素数据;音频编码中的16-bit采样数据等。在诸如上述的情形中,很可能充斥着大量简单而重复的运算,且少有控制代码的出现。因此,SIMD就擅长为这类程序提供更高的性能,比如下面几类:
- Block-based data processing.
- Audio, video, and image processing codes.
- 2D graphics based on rectangular blocks of pixels.
- 3D graphics.
- Color-space conversion.
- Physics simulations.
在32-bit内核的处理器上,如Cortex-A系列,如果不采用SIMD则会将大量时间花费在处理8-bit或16-bit的数据上,但是处理器本身的ALU、寄存器、数据深度又是主要为了32-bit的运算而设计的。因此NEON应运而生。
NEON
NEON就是一种基于SIMD思想的ARM技术,相比于ARMv6或之前的架构,NEON结合了64-bit和128-bit的SIMD指令集,提供128-bit宽的向量运算(vector operations)。NEON技术从ARMv7开始被采用,目前可以在ARM Cortex-A和Cortex-R系列处理器中采用。
NEON在Cortex-A7、Cortex-A12、Cortex-A15处理器中被设置为默认选项,但是在其余的ARMv7 Cortex-A系列中是可选项。NEON与VFP共享了同样的寄存器,但它具有自己独立的执行流水线。
NEON架构(数据类型/寄存器/指令集)
NEON支持的数据类型
- 32-bit single precision floating-point 32-bit单精度浮点数;
- 8, 16, 32 and 64-bit unsigned and signed integers 8, 16, 32 and 64-bit无符号/有符号整型;
- 8 and 16-bit polynomials 8 and 16-bit多项式。
NEON数据类型说明符:
- Unsigned integer U8 U16 U32 U64
- Signed integer S8 S16 S32 S64
- Integer of unspecified type I8 I16 I32 I64
- Floating-point number F16 F32
- Polynomial over {0,1} P8
注:F16不适用于数据处理运算,只用于数据转换,仅用于实现半精度体系结构扩展的系统。
多项式算术在实现某些加密、数据完整性算法中非常有用。
NEON寄存器(重点)
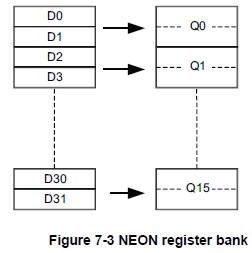
NEON寄存器有几种形式:
- 16×128-bit寄存器(Q0-Q15);
- 或32×64-bit寄存器(D0-D31)
- 或上述寄存器的组合。
注:每一个Q0-Q15寄存器映射到一对D寄存器。
寄存器之间的映射关系:
- D<2n> 映射到 Q 的最低有效半部;
- D<2n+1> 映射到 Q 的最高有效半部;
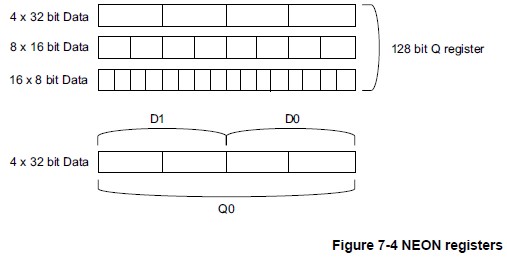
结合NEON支持的数据类型,NEON寄存器有如下图的几种形态:
NEON 数据处理指令可分为:
- Normal instructions can operate on any vector types, and produce result vectors the same size, and usually the same type, as the operand vectors.
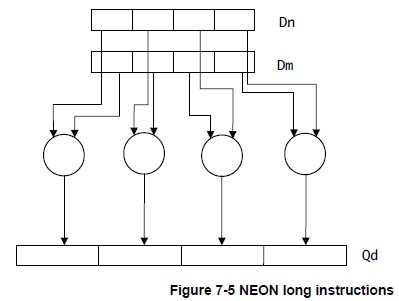
- Long instructions operate on doubleword vector operands and produce a quadword vector result.(操作双字vectors,生成四倍长字vectors) The result elements are usually twice the width of the operands, and of the same type.(结果的宽度一般比操作数加倍,同类型) Long instructions are specified using an L appended to the instruction.(在指令中加L)
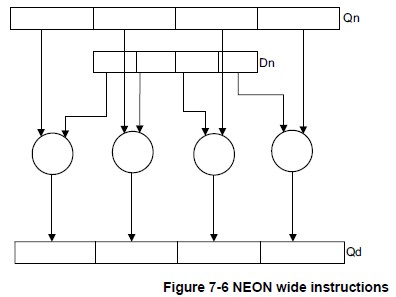
- Wide instructions operate on a doubleword vector operand and a quadword vector operand, producing a quadword vector result.(操作双字 + 四倍长字,生成四倍长字) The result elements and the first operand are twice the width of the second operand elements.(结果和第一个操作数都是第二个操作数的两倍宽度) Wide instructions have a W appended to the instruction.(在指令中加W)
- Narrow instructions operate on quadword vector operands, and produce a doubleword vector result.(操作四倍长字,生成双字) The result elements are usually half the width of the operand elements.(结果宽度一般是操作数的一半) Narrow instructions are specified using an N appended to the instruction.(在指令中加N)
- Saturating variants
- ARM中的饱和算法:
- 对于有符号饱和运算,如果结果小于 –2^n,则返回的结果将为 –2^n;
- 对于无符号饱和运算,如果整个结果将是负值,那么返回的结果是 0;如果结果大于 2^n – 1,则返回的结果将为 2^n – 1;
- NEON中的饱和算法:通过在V和指令助记符之间使用Q前缀可以指定饱和指令,原理与上述内容相同。
- ARM中的饱和算法:
下面给出几幅图解释上述指令的操作原理,图片来自Search Results Cortex-A Series Programmer’s Guide

NEON指令集(重点)
ARMv7/AArch32指令格式
所有的支持NEON指令都有一个助记符V,下面以32位指令为例,说明指令的一般格式:
V{<mod>}<op>{<shape>}{<cond>}{.<dt>}{<dest>}, src1, src2
- <mod>
- Q: The instruction uses saturating arithmetic, so that the result is saturated within the range of the specified data type, such as
VQABS,VQSHLetc. - H: The instruction will halve the result. It does this by shifting right by one place (effectively a divide by two with truncation), such as
VHADD,VHSUB. - D: The instruction doubles the result, such as
VQDMULL,VQDMLAL,VQDMLSLandVQ{R}DMULH. - R: The instruction will perform rounding on the result, equivalent to adding 0.5 to the result before truncating, such as
VRHADD,VRSHR.
- Q: The instruction uses saturating arithmetic, so that the result is saturated within the range of the specified data type, such as
- <op> - the operation (for example,
ADD,SUB,MUL). - <shape> - Shape,即前文中的Long (L), Wide (W), Narrow (N).
- <cond> - Condition, used with IT instruction.
- <.dt> - Data type, such as s8, u8, f32 etc.
- <dest> - Destination.
- <src1> - Source operand 1.
- <src2> - Source operand 2.
注: {} 表示可选的参数。
比如:
VADD.I16 D0, D1, D2 @ 16位加法
VMLAL.S16 Q2, D8, D9 @ 有符号16位乘加
NEON支持的指令总结
- 运算:和、差、积、商
- 共享的 NEON 和 VFP 指令:涉及加载、多寄存器间的传送、存储
具体指令请参见ARM® Compiler armasm User Guide - Chapter 12 NEON and VFP Instructions
注:VFP指令与NEON可能相像,助记符也可能与NEON指令相同,但是操作数等等是不同的,涉及多个基本运算。
NEON编程基础
使用NEON主要有四种方法:
- NEON优化库(Optimized libraries)
- 向量化编译器(Vectorizing compilers)
- NEON intrinsics
- NEON assembly
根据优化程度需求不同,第4种最为底层,若熟练掌握效果最佳,一般也会配合第3种一起使用。本文将会重点介绍第3、4种方法。先简要介绍前两种。
- Libraries:直接在程序中调用优化库
- OpenMax DL:支持加速视频编解码、信号处理、色彩空间转换等;
- Ne10:一个ARM的开源项目,提供数学运算、图像处理、FFT函数等。
- https://github.com/projectNe10/Ne10
- Vectorizing compilers:GCC编译器的向量优化选项
- 在GCC选项中加入向量化表示能有助于C代码生成NEON代码,如
-ftree-vectorize。
- 在GCC选项中加入向量化表示能有助于C代码生成NEON代码,如
NEON intrinsics
提供了一个连接NEON操作的C函数接口,编译器会自动生成相关的NEON指令,支持ARMv7-A或ARMv8-A平台。
所有的intrinsics函数都在GNU官方说明文档。
一个简单的例子:
//add for int array. assumed that count is multiple of 4
#include<arm_neon.h>
// C version
void add_int_c(int* dst, int* src1, int* src2, int count)
{
int i;
for (i = 0; i < count; i++)
dst[i] = src1[i] + src2[i];
}
}
// NEON version
void add_float_neon1(int* dst, int* src1, int* src2, int count)
{
int i;
for (i = 0; i < count; i += 4)
{
int32x4_t in1, in2, out;
in1 = vld1q_s32(src1);
src1 += 4;
in2 = vld1q_s32(src2);
src2 += 4;
out = vaddq_s32(in1, in2);
vst1q_s32(dst, out);
dst += 4;
}
}
代码中的vld1q_s32会被编译器转换成vld1.32 {d0, d1}, [r0]指令,同理vaddq_s32和vst1q_s32被转换成vadd.i32 q0, q0, q0,vst1.32 {d0, d1}, [r0]。若不清楚指令意义,请参见ARM® Compiler armasm User Guide - Chapter 12 NEON and VFP Instructions。
NEON assembly
NEON可以有两种写法:
- Assembly文件
- 纯汇编文件,后缀为”.S”或”.s”。注意对寄存器数据的保存。具体对通用寄存器的详解不是本文的重点,有兴趣的读者请自行补充该部分知识。
- inline assembly内联汇编
- 优点:在C代码中嵌入汇编,调用简单,无需手动存储寄存器;
- 缺点:有较为复杂的格式需要事先学习,不好移植到其他语言环境。
比如上述intrinsics代码产生的汇编代码为:
// ARMv7-A/AArch32
void add_float_neon2(int* dst, int* src1, int* src2, int count)
{
asm volatile (
"1: \n"
"vld1.32 {q0}, [%[src1]]! \n"
"vld1.32 {q1}, [%[src2]]! \n"
"vadd.f32 q0, q0, q1 \n"
"subs %[count], %[count], #4 \n"
"vst1.32 {q0}, [%[dst]]! \n"
"bgt 1b \n"
: [dst] "+r" (dst)
: [src1] "r" (src1), [src2] "r" (src2), [count] "r" (count)
: "memory", "q0", "q1"
);
}
NEON优化心得
笔者在前段时间连续使用NEON做ARM平台的优化,由于中文资料少得可怜,且英文资料零散琐碎,期间也遇到不少坑,先摘出部分经验至此,希望能够帮助到大家。︿( ̄︶ ̄)︿
建议的NEON调优步骤
-
理清所需的寄存器、指令。 建议根据要实现的任务,画出数据变换流程,和每步所需的具体指令,尽可能找到最优的实现流程。这一步非常关键,如果思路出错或是不够优化,则会影响使用NEON的效果,并且对程序修改带来麻烦,一定要找到最优的实现算法哦~
-
先实现intrinsics(可选)。 初学者先实现intrinsics是有好处的,字面理解性更强,且有助于理解NEON指令。建议随时打印关键步骤的数据,以检查程序的正误。
-
写成汇编进一步优化。 将intrinsics生成的汇编代码进行优化调整。一般来说,有以下几点值得注意【干货】:
- 只要intrinsics运算指令足够精简,运算类的汇编指令就不用大修;
- 大部分的问题会出在存取、移动指令的滥用、混乱使用上;
- 优化时要尽量减少指令间的相关性,包括结构相关、数据相关控制相关,保证流水线执行效率更高;
- 大概估算所有程序指令取指、执行、写回的总理论时间,以此估算本程序可以优化的空间;
- 熟练对每条指令准备发射、写回时间有一定的认识,有助于对指令的优化排序;
- 一定要多测试不同指令的处理时间!!原因是你所想跟实际有出入,且不同的编译器优化的效果可能也有些不同;
- 一定要有一定的计算机体系结构基础,对存储结构、流水线有一定的体会!!
【注意】在此笔者温馨提示各位看官(⊙o⊙)不仅是NEON,所有的性能优化是个经验活儿,需要自己动手才能领悟更多的诀窍,总结一下NEON优化就是:
- 第一优化算法实现流程;
- 第二优化程序存取;
- 第三优化程序执行;
- 第四哪儿能优化,就优化哪儿~~
对NEON优化使用的好坏直接导致优化效果,优化效果好的会节省70%以上的时间。
内联汇编使用心得
当读者熟练后就可以直接上手内联汇编了。时间有限,本文中不具体介绍inline assembly的使用方法,我后续可能会将这部分单独写成一篇博客。感兴趣者请参见ARM GCC Inline Assembler Cookbook
一些使用心得:
- inline assembly下面的三个冒号一定要注意
- output/input registers的写法一定要写对,clobber list也一定要写完全,否则会造成令你头疼的问题 (T-T) …
- 这个问题在给出的cookbook中也有介绍,但是并不全面,有些问题只有自己碰到了再去解决。 笔者就曾经被虐了很久,从生成的汇编发现编译器将寄存器乱用,导致指针操作完全混乱,毫无头绪…
- 一般情况下建议的写法举例:
asm volatile (
... /* assembly code */
: "+r"(arg0) // %0
"+r"(arg1) // %1 // Output Registers
: "r"(arg2) // %2 // Input Registers
: "cc", "memory", r0, r1
);
- 传入内联汇编程序段的C参数是有限的
- 笔者亲测对于Cortex-A7平台output/input registers基本在9以内才可保证,否则会报出
can't find a register in class 'GENERAL_REGS' while reloading 'asm'错误。
- 笔者亲测对于Cortex-A7平台output/input registers基本在9以内才可保证,否则会报出
















 2837
2837

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









