




 本文介绍了在爬虫应用中如何使用OCR技术,特别是Google的Tesseract OCR引擎,它被认为具有高准确率。文章列举了几个在线OCR工具,并强调了Tesseract,一个开源的OCR库,支持多种语言包装器。通过Java的tess4j包装器作为示例,展示了添加依赖和基本的使用方法,同时提到了模型数据的获取以及识别结果的输出。文章还提及了Tesseract的性能优化和自定义训练模型的资源链接。
本文介绍了在爬虫应用中如何使用OCR技术,特别是Google的Tesseract OCR引擎,它被认为具有高准确率。文章列举了几个在线OCR工具,并强调了Tesseract,一个开源的OCR库,支持多种语言包装器。通过Java的tess4j包装器作为示例,展示了添加依赖和基本的使用方法,同时提到了模型数据的获取以及识别结果的输出。文章还提及了Tesseract的性能优化和自定义训练模型的资源链接。
目前有很多OCR工具或者类库都提供了准确率挺高的PDF和图片识别功能。在爬虫应用中,时常需要识别验证码或者目标站点处于数据保护而使用图片来替代直接的文本。除了直接的软件和类库外,还有一些在线工具可以直接识别,使用free online ocrGooglr可以搜索到下面这几个:
- http://www.onlineocr.net/
- http://www.free-ocr.com/
- http://www.ocrconvert.com/
- https://www.newocr.com/
众多的工具中,有个wiki页面做了比较详细的比较:
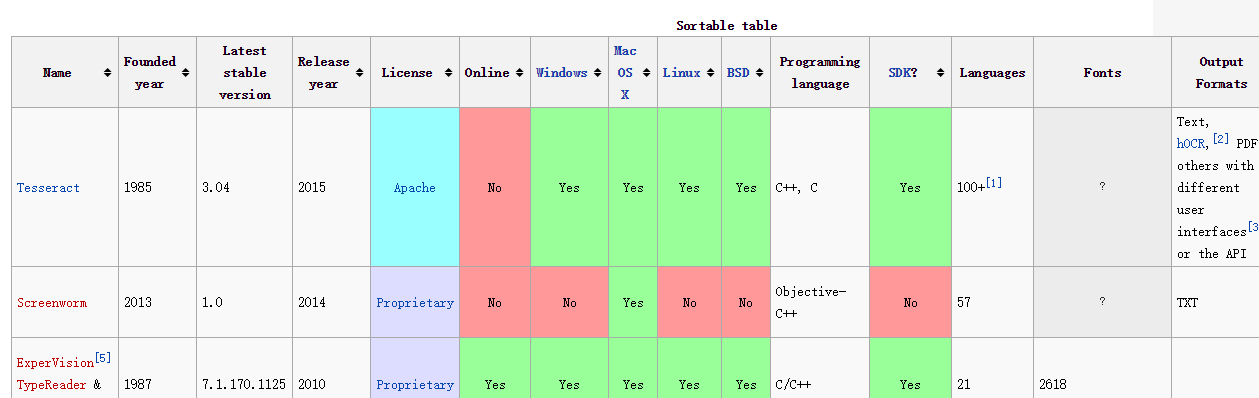
详细内容请参考Comparison_of_optical_character_recognition_software。
在众多软件中,Google出品的Tesseract口碑不错,有些人认为是所有OCR软件中准确率最高的,甚至比一些商业软件还高。Google的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









