







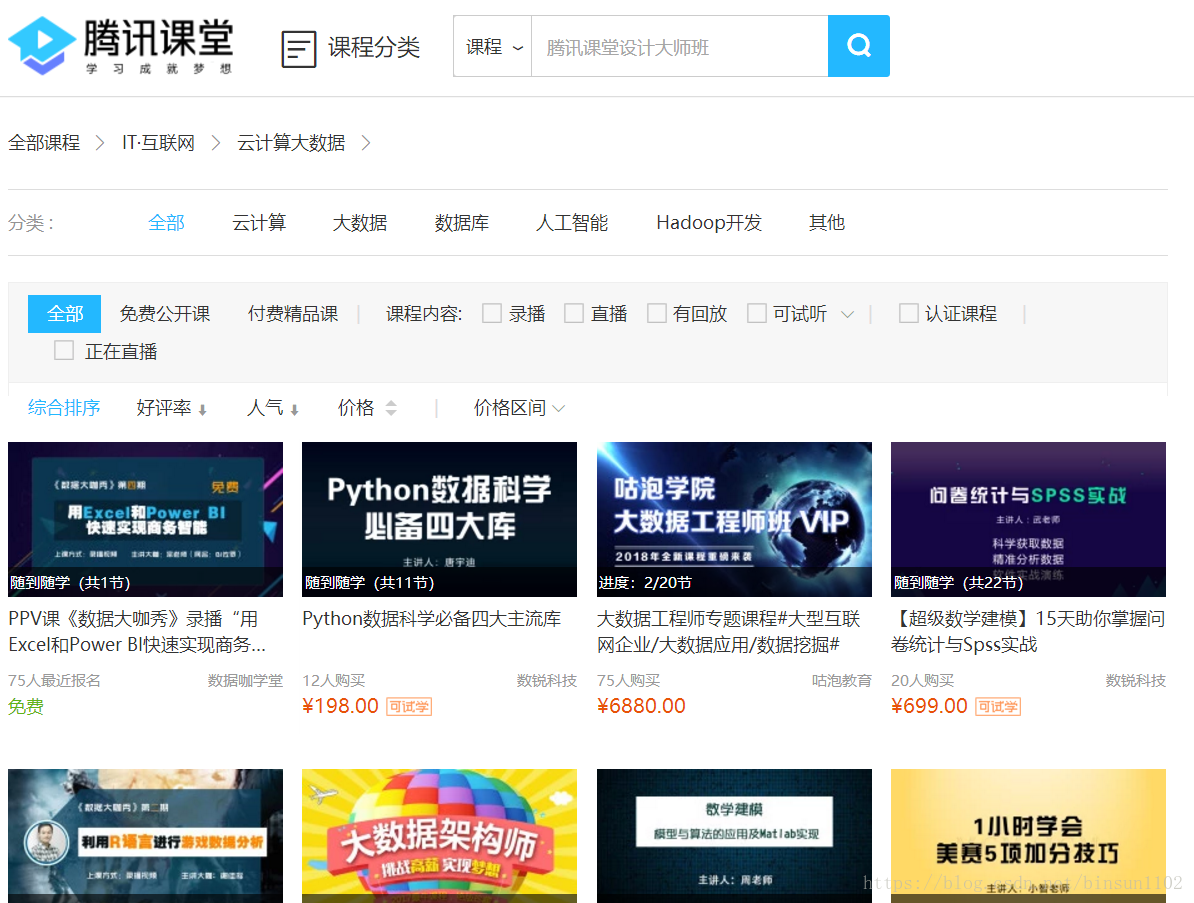
业务需求:
需要爬取腾讯课堂IT.互联网类别下的云计算大数据子类别下的所有课程数据:
课程名称、价格、购买人数、机构名称
1、编写item.py文件
定义要爬取的数据字段:
import scrapy
class TxktcrawlerItem(scrapy.Item):
# define the fields for your item here like:
title=scrapy.Field()
users=scrapy.Field()
price=scrapy.Field()
agency=scrapy.Field()2、在mysql中建表
因为需要将爬取到的数据存储到mysql中,所以首先在mysql中建表:
use test;create table txkt(
id int unsigned auto_increment primary key,
title char(50),
users int(10),
price float(10),
agency char(50)
); 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2185
2185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











