







看到hadoop join和hbase都有bloom filter的实现,找了找他的介绍文档
转http://blog.csdn.net/wbia2010lkl/article/details/5953629
转http://blog.csdn.net/jiaomeng/article/details/1495500
在javaEyes上找到一篇挺有用的文章,希望能对大家理解Bloom filter有帮助
1 Overview
Bloom filter最早由 Burton Howard Bloom提出,是一种用于判断成员是否存在于某个集合中的数据结构。 Bloom filter的判断基于概率论:
-
- 如果某个成员存在于集合中,那么Bloom filter不会返回假(即不存在),也就是说false negative是不可能的。
- 如果某个成员实际上不存在于集合中,Bloom filter可能返回真(即存在),这种情况被称为false positive。
- (hbase的hfile使用bloom fitler,可以确定的告诉你指定的rk不在当前hfile中,但是不确定他是否在当前hfile中)
Bloom filter通常被实现为一个包含 m 位的位数组(bit array),所有位的初始值都为0。Bloom filter支持以下两种类型的操作:
- add。将成员添加到Bloom filter中。以该成员为参数调用 k 个索引函数(index functions),得到 k 个位数组的索引值,取值范围是 [0, m), 然后将位数组的对应位设置为1。
- query。判断某个成员是否已经添加到Bloom filter中。以该成员为参数调用 k 个索引函数,得到 k 个位数组的索引值,然后根据这些索引值检查位数组:当位数组中所有的对应位均为1时,那么认为该成员已经存在。
如果query的结果为真(即positive),那么实际上存在以下两种可能性:
- 该成员已经被add到集合中,即该成员的确存在。
- 该成员未被add到集合中,但是query过程中检查的所有位均被设置为1(由于添加的其它成员导致)。这种情况被称为false positive。
传统的Bloom filter 不支持从集合中删除成员。对于每个添加到Bloom filter中的成员,实际上将其位数组中的 k 位设置为1。尽管将这些位重置为0可以保证从Bloom filter中删除该成员,但是这样做的副作用是可能会影响某些其它成员,因为其它成员也可能被映射到这些被重置为0的位中的一位或者多位, 从而最终导致false negatives。对于Bloom filter而言,false negatives是不被允许的。 Counting Bloom filter由于采用了计数,因此支持remove操作。
Bloom filter 使用的 k 个index functions,有时也被称为hash functions,它们通常被假定为彼此独立,返回值在可能的取值范围内均匀分布(这是以下一系列数学证明的基础)。
2 The Math
Bloom filter的基本概念并不复杂,接下来分析一下query操作对某个未被添加的成员返回positive(即false positive)的概率:
假设p是位数组中某一位为1的概率, 那么false positive的概率是 pk 。如果n是已经添加到Bloom filter中的成员个数,那么 p = 1 – (1 – 1/m)nk,经过一系列推导得到 p ≈ ( 1 – e-kn/m ) k , 当 k = m / n * ln2 时(ln 即 loge ),p为最小值。 例如当k = 8, m/n = 10时, false positive的理论值为0.00846。以下是段计算false positive的实例代码:
Java代码
- public static double calculateFalsePositiveProbability(int k, int m, int n) {
- return Math.pow((1 - Math.exp(-k * (double) n / (double) m)), k);
- }
对于某些应用而言,false positive的概率已经是一个足够好的判断Bloom filter准确性的指标,Peter C.Dillinger 和 Panagiotis Manolios 在其Bloom Filters in Probablistic Verfification的论文中指出,对于query过程中的不确定性, state omission 是一个更合适的指标。建议感兴趣的读者阅读该论文,顺便也可以复习一下相关的数学知识。
3 Refinement
So far, so good。 跟普通的HashMap相比, Bloom filter不需要在内存中保存key和value, 而是位数组中的若干个位即可,这在内存使用上是个巨大的节省,当然前提是能容忍一定概率的false positives。但是传统的Bloom filter存在以下两个严重的缺陷:
- 为了保证足够低的false positive概率,通常索引函数的个数 k 比较大(例如十几甚至几十,但通常不超过32)。 能找到这么多个random,uniform and independent的索引函数并不是一件容易的事情。
- 数量众多的索引函数,导致add和query的性能不高。
Peter C.Dillinger 和 Panagiotis Manolios在其论文中指出,fingerprinting Bloom filter可以有效地减少索引函数的个数,并且对准确性的影响可以小到忽略。这对于传统的Bloom filter来说,是个重大的改进。笔者使用了其中介绍的triple hashing,认为效果比较明显。
4 Implementation
如果Google以Java实现的Bloom filter, java-bloomfilter 可能是最容易找到的实现之一。它采用的是传统的Bloom filter算法:使用的 k 个索引函数(默认都是MD5),只是索引函数在进行计算时对参数的加盐(salting)不同而已。笔者认为 java-bloomfilter 的性能可能有待提升。
Hadoop common的util包中也提供了一个Bloom Filter的实现,此外其hash包还提供了JenkinsHash 和 MurmurHash 两个Hash算法。笔者感觉Hadoop 的Bloom filter的实现方式类似fingerprinting Bloom filter,但是没有使用double hashing 或者tripple hashing。
此外关于位数组的实现方式,可能最直接想法的是使用java.util.BitSet。不过笔者认为如果处理的数据量很大、或者性能要求比较高,那么不建议使用java.util.BitSet, 因为java.util.BitSet的内存使用方式、总体性能都不是很理想。
5 Reference
- Bloom Filters in Probablistic Verfification. Peter C.Dillinger and Panagiotis Manolios
- Hadoop的Bloom filter实现。http://hadoop.apache.org/common/
- java-bloomfilter. http://code.google.com/p/java-bloomfilter/
-------------------------------------------------------------------------------
Bloom Filter概念和原理
焦萌 2007年1月27日
Bloom Filter是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。Bloom Filter的这种高效是有一定代价的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
集合表示和元素查询
下面我们具体来看Bloom Filter是如何用位数组表示集合的。初始状态时,Bloom Filter是一个包含m位的位数组,每一位都置为0。

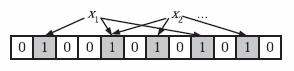
为了表达S={x1, x2,…,xn}这样一个n个元素的集合,Bloom Filter使用k个相互独立的哈希函数(Hash Function),它们分别将集合中的每个元素映射到{1,…,m}的范围中。对任意一个元素x,第i个哈希函数映射的位置hi(x)就会被置为1(1≤i≤k)。注意,如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。在下图中,k=3,且有两个哈希函数选中同一个位置(从左边数第五位)。
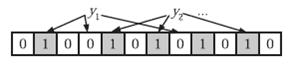
在判断y是否属于这个集合时,我们对y应用k次哈希函数,如果所有hi(y)的位置都是1(1≤i≤k),那么我们就认为y是集合中的元素,否则就认为y不是集合中的元素。下图中y1就不是集合中的元素。y2或者属于这个集合,或者刚好是一个false positive。
错误率估计
前面我们已经提到了,Bloom Filter在判断一个元素是否属于它表示的集合时会有一定的错误率(false positive rate),下面我们就来估计错误率的大小。在估计之前为了简化模型,我们假设kn<m且各个哈希函数是完全随机的。当集合S={x1, x2,…,xn}的所有元素都被k个哈希函数映射到m位的位数组中时,这个位数组中某一位还是0的概率是:
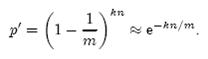
其中1/m表示任意一个哈希函数选中这一位的概率(前提是哈希函数是完全随机的),(1-1/m)表示哈希一次没有选中这一位的概率。要把S完全映射到位数组中,需要做kn次哈希。某一位还是0意味着kn次哈希都没有选中它,因此这个概率就是(1-1/m)的kn次方。令p = e-kn/m是为了简化运算,这里用到了计算e时常用的近似:
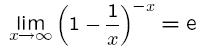
令ρ为位数组中0的比例,则ρ的数学期望E(ρ)= p’。在ρ已知的情况下,要求的错误率(false positive rate)为:
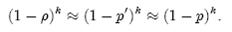
(1-ρ)为位数组中1的比例,(1-ρ)k就表示k次哈希都刚好选中1的区域,即false positive rate。上式中第二步近似在前面已经提到了,现在来看第一步近似。p’只是ρ的数学期望,在实际中ρ的值有可能偏离它的数学期望值。M. Mitzenmacher已经证明[2] ,位数组中0的比例非常集中地分布在它的数学期望值的附近。因此,第一步的近似得以成立。分别将p和p’代入上式中,得:
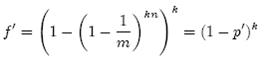
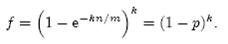
相比p’和f’,使用p和f通常在分析中更为方便。
最优的哈希函数个数
既然Bloom Filter要靠多个哈希函数将集合映射到位数组中,那么应该选择几个哈希函数才能使元素查询时的错误率降到最低呢?这里有两个互斥的理由:如果哈希函数的个数多,那么在对一个不属于集合的元素进行查询时得到0的概率就大;但另一方面,如果哈希函数的个数少,那么位数组中的0就多。为了得到最优的哈希函数个数,我们需要根据上一小节中的错误率公式进行计算。
先用p和f进行计算。注意到f = exp(k ln(1 − e−kn/m)),我们令g = k ln(1 − e−kn/m),只要让g取到最小,f自然也取到最小。由于p = e-kn/m,我们可以将g写成
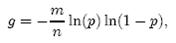
根据对称性法则可以很容易看出当p = 1/2,也就是k = ln2· (m/n)时,g取得最小值。在这种情况下,最小错误率f等于(1/2)k ≈ (0.6185)m/n。另外,注意到p是位数组中某一位仍是0的概率,所以p = 1/2对应着位数组中0和1各一半。换句话说,要想保持错误率低,最好让位数组有一半还空着。
需要强调的一点是,p = 1/2时错误率最小这个结果并不依赖于近似值p和f。同样对于f’ = exp(k ln(1 − (1 − 1/m)kn)),g’ = k ln(1 − (1 − 1/m)kn),p’ = (1 − 1/m)kn,我们可以将g’写成
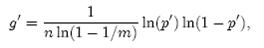
同样根据对称性法则可以得到当p’ = 1/2时,g’取得最小值。
位数组的大小
下面我们来看看,在不超过一定错误率的情况下,Bloom Filter至少需要多少位才能表示全集中任意n个元素的集合。假设全集中共有u个元素,允许的最大错误率为є,下面我们来求位数组的位数m。
假设X为全集中任取n个元素的集合,F(X)是表示X的位数组。那么对于集合X中任意一个元素x,在s = F(X)中查询x都能得到肯定的结果,即s能够接受x。显然,由于Bloom Filter引入了错误,s能够接受的不仅仅是X中的元素,它还能够є (u - n)个false positive。因此,对于一个确定的位数组来说,它能够接受总共n + є (u - n)个元素。在n + є (u - n)个元素中,s真正表示的只有其中n个,所以一个确定的位数组可以表示
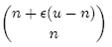
个集合。m位的位数组共有2m个不同的组合,进而可以推出,m位的位数组可以表示
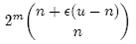
个集合。全集中n个元素的集合总共有
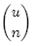
个,因此要让m位的位数组能够表示所有n个元素的集合,必须有
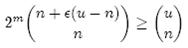
即:
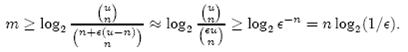
上式中的近似前提是n和єu相比很小,这也是实际情况中常常发生的。根据上式,我们得出结论:在错误率不大于є的情况下,m至少要等于n log2(1/є)才能表示任意n个元素的集合。
上一小节中我们曾算出当k = ln2· (m/n)时错误率f最小,这时f = (1/2)k = (1/2)mln2 / n。现在令f≤є,可以推出
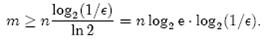
这个结果比前面我们算得的下界n log2(1/є)大了log2 e ≈ 1.44倍。这说明在哈希函数的个数取到最优时,要让错误率不超过є,m至少需要取到最小值的1.44倍。
总结
在计算机科学中,我们常常会碰到时间换空间或者空间换时间的情况,即为了达到某一个方面的最优而牺牲另一个方面。Bloom Filter在时间空间这两个因素之外又引入了另一个因素:错误率。在使用Bloom Filter判断一个元素是否属于某个集合时,会有一定的错误率。也就是说,有可能把不属于这个集合的元素误认为属于这个集合(False Positive),但不会把属于这个集合的元素误认为不属于这个集合(False Negative)。在增加了错误率这个因素之后,Bloom Filter通过允许少量的错误来节省大量的存储空间。
自从Burton Bloom在70年代提出Bloom Filter之后,Bloom Filter就被广泛用于拼写检查和数据库系统中。近一二十年,伴随着网络的普及和发展,Bloom Filter在网络领域获得了新生,各种Bloom Filter变种和新的应用不断出现。可以预见,随着网络应用的不断深入,新的变种和应用将会继续出现,Bloom Filter必将获得更大的发展。
参考资料
[1] A. Broder and M. Mitzenmacher. Network applications of bloom filters: A survey. Internet Mathematics, 1(4):485–509, 2005.
[2] M. Mitzenmacher. Compressed Bloom Filters. IEEE/ACM Transactions on Networking 10:5 (2002), 604—612.
[3] www.cs.jhu.edu/~fabian/courses/CS600.624/slides/bloomslides.pdf
[4] http://166.111.248.20/seminar/2006_11_23/hash_2_yaxuan.ppt














 498
498











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









