







bluestore : a faster backend for ceph
—–sage weil 的公开课导读
ceph创始人sage大叔前些日子在国际版的公开课里面介绍了根据ceph的特定环境定制的新的文件系统bluestore,用以作为ceph的存储后端,本文主要以sage的presentation:
“bluestore - a new faster storage backend for ceph”
为基础,简单的介绍bluestore的设计方案与性能分析,部分知识点会比较粗糙或有错误,欢迎各位指正,谢谢!。
主要内容:
1、ceph背景,目前状况;
2、POSIX简介,与ceph的问题;
3、第一版解决方案 new store;
4、新一代解决方案 bluestore;
5、性能分析 ;
6、总结 ;
一、Motivating
ceph从一开始问世到目前已经接近了十年时间,从最开始的sage 的论文中对CEPH的文件系统描述:
“a scalable, high performance distributed file system”
sage说,作为ceph存储的后端,他强调“performance, reliability, and scalability”三大核心发展方向,可靠性和拓展性相对简单,而性能便一直是最具有挑战性的课题。
如下是经典的ceph的架构逻辑,ceph向外提供了三大接口,用以提供不同的存储功能,底层都是建立在RADOS之上,具体的rados内容可以参考weil的学术论文。
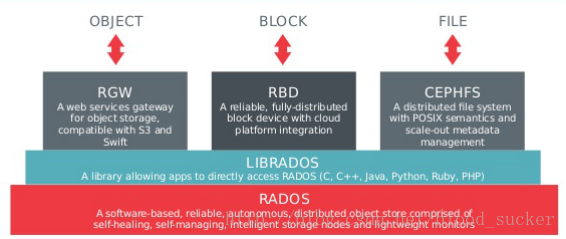
从结构拓扑看,每个集群都可以看做是一棵树,主机作为数据的叶子节点,主机根据分工不同可以作为数据存储节点,也可以作为元数据存储节点,在存储节点上,最底层是磁盘,磁盘上是文件系统,目前主要的包括btrfs、xfs、ext4等POSIX标准文件系统,上层就是我们的OSD守护进程,用来维护对象的存储操作与映射等内容:
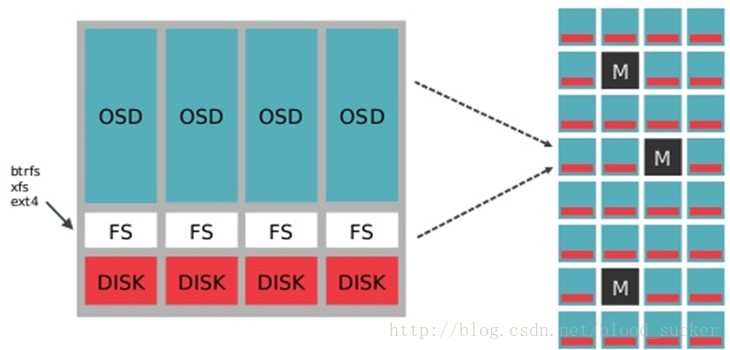
由于ceph的数据的特殊结构,在实际的生产实践中,我们在标准的文件系统之上又增加了一层模块—Filestore:
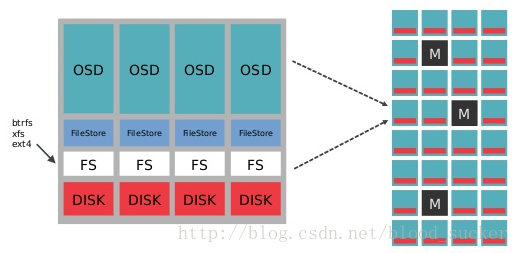
filestore在旧版本的Ceph中作为与文件系统的桥梁,用来暴露接口给上层OSD daemons来存储本地数据,他负责实际的写数据的交互逻辑。
对于FileStore的实现称之为对象存储ObjectStore,提供给ceph存储对象数据到物理磁盘的一系列接口,他的核心要素包括三部分:
a)对象object,可以映射为我们需要存储的中的文件,不论使用何种方式存储何种类型的数据,经过ceph最终都换转换成为一个object,它包含基础数据、对象属性数据attributes以及一些用来维护的omap数据,attributes是该对象的拓展属性,相当于POSIX类文件系统的元数据,受于底层文件系统的限制,这种k/v型的数据大小、个数是有上限的,一旦我们需要的该文件的描述信息无法存到其中,就需要存储到omap中,他会在fs之上存储在内存数据库中(leveldb)。
b)集合collections,简单的理解,可以类比文件系统中的目录结构,但是经过OSD daemons处理过后,向下传递的对象数据更加有序并且归置效果更高,对其分组更类似于一对对象的集合概念。对底层的POSIX文件系统而言,ceph拥有一个大的对象池,并将其分片城多个placement groups,这些pg
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1645
1645











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









