



面向低延迟视觉数据处理的能量感知移动边缘计算与路由
摘要
移动边缘计算(MEC)等新范式正变得可行,可用于例如灾难事故响应期间的实时决策,以应对网络边缘产生的数据激增。然而,当前的 MEC 部署缺乏灵活的物联网设备数据处理能力,例如无法满足用户对实时处理与节能处理的偏好。此外,MEC 还可以从基于策略的边缘路由中受益,以在高效能耗的前提下维持持续性能水平。本文研究了 MEC 在能源管理方面的潜力,旨在解决资源受限的物联网设备在有限电源条件下的应用问题,同时提供对高分辨率视觉数据的低延迟处理。通过使用在灾难事故响应场景中至关重要的一个人脸识别应用,我们提出了一种新颖的“卸载决策”算法,该算法分析计算策略中的权衡,以在低到高工作负载下将视觉数据处理任务卸载至边缘云或核心云。该算法还分析了在不同视觉数据消耗需求(即使用胖客户端或瘦客户端的用户)条件下,决策对能耗的影响。为解决处理吞吐量与能效之间的权衡,我们提出了一种“可持续的基于策略的智能驱动边缘路由”(SPIDER)算法,该算法在移动自组织网络(MANETs)中利用机器学习。该算法具有能量感知特性,能够提升地理路由基线性能(即最小化局部极小值的影响),实现吞吐量性能的可持续性,同时支持灵活的策略配置。我们在 GENI 云基础设施中的真实边缘和核心云测试平台进行了实验,并在模拟中重现了龙卷风破坏的灾难场景,以评估所提出的算法。我们的实证结果表明,在人脸识别应用的视觉数据处理中,MEC 可以为希望在节能与低延迟之间进行取舍的用户提供灵活性。此外,我们的仿真结果显示,在不同用户偏好、节点移动性和严重节点故障条件下,我们的路由方法优于现有解决方案。
索引术语
移动边缘计算,基于策略的云管理,能量感知边缘路由,低延迟视觉数据处理
一、引言
物联网(IoT)在制造业和公共安全等智慧城市应用的创新中正变得越来越重要。移动设备、可穿戴智能设备和传感器通过多样化的网络连接选项(例如,简陋基础设施、网络边缘的千兆级网络速度)实现互联,应用程序能够从这些物联网设备的数据中获取有价值的洞察。特别是对于灾难事件响应或执法等应用,视觉数据(例如,高分辨率来自物联网设备的图像、视频片段等视觉数据需要实时处理。实时性要求可能意味着例如人脸识别应用以每秒15帧或 ≈0.1秒/图像[1]的速度进行处理。从视觉数据中获得的相关洞察可帮助事故指挥官快速分析现场并部署资源(例如急救人员、救护车、医疗物资)[2]。通过与云计算融合,基于物联网的应用数据可在多个网络边缘站点大规模处理,并具备按需计算能力。
然而,并不总是可以合理地假设存在功能完备的计算/网络基础设施和无限的电源来满足视觉数据处理的需求。在涉及地震、龙卷风、野火、飓风或涉及恐怖主义的人为灾害等自然灾害情况下,边缘基础设施可能会丧失。因此,灾难事件响应决策所需的计算可能不得不依赖于在计算、网络或电力资源方面受限的移动设备。我们可以设想一种有用的基于物联网的应用,即面部识别技术,当存在高分辨率图像数据以及高性能的计算/网络能力时,该技术能够通过与大型/分布式图像数据库进行比对,实现快速且准确的身份识别。这种识别有助于寻找“失踪人员”、识别“不良行为者”[3],或统计第一响应者在灾难场景中的到场级别。通常,这些识别操作需要在有限的功耗预算下,通过在网络边缘实时处理大量不同分辨率的图像来完成。

图1展示了移动边缘计算(MEC)[4],[5]新范式如何在示例性人脸识别应用背景下出现,支持原始图像的上传和处理后图像的下载请求。MEC架构通过蜂窝运营商在无线接入网络(RANs)中实现分布式计算与应用程序开发者和内容提供商合作。通过使用移动边缘计算(MEC),我们可以增强关键基础设施,使云计算资源更分布式并靠近无线网络边缘。例如,它允许基站基础设施或“云节点”处理地理位置邻近的移动设备发出的计算请求[6],[7]。因此,MEC提供了将计算任务从物联网设备卸载的选项,以解决资源受限的物联网设备在有限电源下的能源管理问题,同时利用复杂的计算机视觉算法实现视觉数据的低延迟处理。诸如[8]的研究表明,与在资源受限的移动设备上进行处理相比,云服务器卸载可节省功耗(高达25倍)并提升处理速度(达3倍)。然而,当边缘云与核心云结合使用时,仍需更深入理解MEC范式的潜力及其优势或局限性,特别是在核心云存在以下情况时:(a) 不理想的长往返时间,(b) 间歇性连接,或 (c) 过度拥塞,如在严苛或恶劣的网络边缘环境中所见。
为了解决MEC架构中处理吞吐量与能源效率之间的权衡问题,需要基于策略的灵活边缘路由(即地理路由的一种变体)。此类边缘路由协议应能够应对动态网络状况,同时具备能量感知能力。例如,在灾难事故现场的移动自组织网络(MANET)中,移动节点的位置可能频繁变化,或由于电源问题导致固定基础设施中的静态节点消失。这将引发不可预测的拓扑变化[9],并对可持续服务连续性以及维护路由表带来挑战。先前提出的地理路由协议(如 [10],[11])本质上是有状态的。这类有状态协议通过在数据库中维护节点位置,并在事件(如高移动性或节点故障)发生时更新位置信息,但会导致巨大的通信开销,并消耗电力受限的物联网设备的能源。其他无状态地理路由协议(如[12],[13])虽无需维护路由表,但其性能会因局部极小值问题而下降,即可能导致路由中的无限循环。
在本文中,我们旨在通过灾难事故响应场景中的人脸识别应用背景,研究移动边缘计算(MEC)范式的潜力。我们的目标是在人脸识别应用框架内采用MEC,并分析在低到高工作负载下,将视觉数据处理卸载至边缘或核心云的计算策略之间的权衡,以及这些策略在不同视觉数据消耗需求下的能耗影响。
我们的贡献
作为论文贡献的一部分,我们特别考虑了具有瘦客户端或胖客户端配置的用户的视觉数据消费;用户端的瘦客户端配置假设所有处理后的图像都存储并查看于远程云资源,而胖客户端配置则假设处理后的图像被下载并在移动用户设备层面进一步进行后处理。在可用的情况下,我们假定核心云具备提供多个计算实例有助于并行处理视觉数据工作负载,相较于资源有限的边缘云以串行方式处理工作负载。此外,我们还考虑在图像传输中使用压缩的情况,这可以在恶劣网络中节省带宽消耗,但会增加能耗,可能对电源受限的物联网设备或具有有限电源的边缘云产生负面影响。
为了为基于物联网的应用提供一种灵活的选择,以决定在上述用户需求情况下是否将视觉数据处理卸载到边缘云或核心云,我们提出了一种新颖的“决策算法”。该算法能够处理存在硬实时处理需求的情况,或在网络边缘需要处理规模变化的视觉数据处理工作负载的情况,同时满足注重能源或要求快速处理的用户需求。
为满足基于策略的灵活边缘路由需求,我们提出了一种“基于可持续策略的智能驱动边缘路由”(SPIDER)算法,该算法利用机器学习技术对卫星图像进行分析,以学习现有物理障碍物的地理信息。我们利用通过全球定位系统(GPS)获取的地理坐标,提升地理路由的吞吐量性能可持续性,从而提高基线性能(即避免局部极小值的影响)。此外,我们展示了SPIDER路由引擎的实现,其源代码在[14]公开可用。我们的实现在边缘网络路由中提供了灵活的策略配置,能够应对动态网络情况,同时兼顾用户在处理吞吐量与能效之间的权衡决策。
我们在一个真实的边缘和核心云测试平台中,通过实验评估了我们基于能量感知和低延迟的移动边缘计算框架,该框架结合了人脸识别应用以及我们的卸载决策算法。对于边缘云,我们使用校园服务器;对于核心云,我们使用GENI 云资源[15]。我们利用基于Android的PowerTutor工具 [16]来分析并估算在测试平台内基于OpenCV [17]的人脸识别应用的能耗(指标:焦耳)。实验结果表明,在基于视觉物联网的应用数据处理中,移动边缘计算如何为用户提供灵活性,使其能够在节能与低延迟(指标:处理时间)之间进行权衡。我们比较了在低到高视觉数据处理工作负载下,采用瘦客户端或胖客户端配置的效果差异,以及卸载策略如何影响能效或满足低延迟的用户需求。
我们通过在NS‐3(网络模拟器)[18]仿真中重现 2011年美国密苏里州乔普林地区的龙卷风破坏事件中的灾难场景来评估我们的SPIDER算法。我们的仿真包含了涉及多样化用户偏好、节点移动性和严重节点故障条件的灾难场景和情况。我们利用‘平均剩余电量’(指标:焦耳)测量值,该值反映了我们在基于UDP的流媒体应用仿真中的网络寿命。我们的仿真结果表明,我们的SPIDER路由引擎优于现有解决方案[19],[20]并且可以提供灵活性,为用户提供灵活性,使用户能够在移动边缘计算环境中优先考虑节能而非吞吐量性能可持续性,或反之。
论文结构
本文其余部分的结构如下:第二节回顾了相关前期工作。在第三节中,我们介绍了人脸识别应用以及一个用于研究计算卸载策略的移动边缘计算框架,以平衡物联网设备从小到大规模工作负载在能效与低延迟处理之间的权衡。第四节中,我们提出了结合机器学习的 SPIDER算法,以提升地理路由的基线性能。我们在第六节展示了基于真实GENI云测试平台实验的性能评估,以及涉及重建灾难场景的仿真。第七节总结全文并提出未来工作方向。
II. 相关工作
计算卸载决策
关于计算卸载的现有文献可分为两类。第一类研究,例如[21],[22],提出了“程序划分”的概念,即将给定处理任务的一部分卸载到边缘服务器上执行,而任务的其余部分在用户设备上运行。具体而言,他们提出了离线启发式算法,以支持大规模移动应用,从而减少所有应用程序用户的完成时间。第二类研究,例如 [23],[24],[25],[26],考虑了一种“迁移”策略,即将整个应用程序卸载到边缘服务器上。具体而言,[23]中的作者根据信道和基站资源分配状态创建了设备分类,以优先处理计算任务。在[24],中,作者使用马尔可夫决策过程在服务内动态卸载计算。[25],[26]中的作者利用软件定义网络(SDN)来优化边缘(或雾)服务器的选择以及流量引导。具体而言,他们提出了PRIMAL框架,该框架结合SDN和整数二次规划,旨在最大化利润并最小化延迟,以实现用户应用程序卸载。如果卸载不可行,如 [27],[28]中的研究则提出“负载分割”这一流行的数据流管理技术。负载分割涉及在边缘设备上自动丢弃或调整数据包质量。我们的工作与现有研究不同之处在于,我们考虑了能量感知和低延迟用户需求的处理,灵活地允许视觉数据处理在边缘云或核心云中进行,具体取决于相关的权衡。
视觉数据消费
为了显示来自远程系统的视觉数据,通常使用瘦客户端或胖客户端解决方案。瘦客户端[29]通常可以在本地计算机硬件(例如键盘、鼠标、显示器)上运行,能够远程连接到基于云托管或位于远程服务器上的远程桌面。这种情况下,计算负担将集中在服务器端,屏幕截图数据被发送到客户端。而胖客户端则可被视为具备显著计算资源的功能完整计算机或设备,可用于根据用户下钻或缩放对视觉数据进行后处理进出。根据[30], ,无状态的胖客户端可能仍需要定期从云或远程服务器获得连接和计算支持。无论如何,用户在图像渲染质量和交互方面的满意度取决于会话延迟,而会话延迟又受客户端/服务器端的网络带宽和计算资源影响。作者在[31]中通过实际测量发现,即使在网络带宽良好的100 Mbps情况下,瘦客户端的延迟在不同城市中仍处于33‐100 毫秒范围内。此外,他们建议采用“云微端”或“移动边缘计算”架构作为降低端到端延迟的合适解决方案。我们的工作在此建议基础上展开,应用于基于 MEC架构的人脸识别应用中的视觉数据处理流程。
面向移动自组织网络的能量感知地理路由
在移动自组织网络(MANET)中,存在关于地理路由的研究,例如目的节点序列距离向量(DSDV)[32]。使用DSDV时,每个节点会定期更新其路由表,包含通往目的地的下一跳信息和跳数,但未考虑能效问题。相比之下,[33]等研究提出在路由决策中跟踪网络节点的电池电量。为进一步提高能效,[34],[35]等近期研究提出了基于用户移动性和节点能耗的聚类方法,并选择簇头将数据包路由至边缘网关。然而,此类簇头需要扫描邻近节点信号并存储其信息以形成簇,难以天然应对高移动性和严重节点故障。[36],[37]等研究中的认知路由方法采用通信信道自适应技术,利用信息质量(QoI)和流量感知等指标优化数据传输的能效。上述所有方法均需维护一定的网络状态信息,即在路由表管理方面是有状态的。相比之下,我们提出的新型SPIDER算法是无状态的,并基于我们前期工作[38] ,该工作利用部署在边缘的基于深度学习的检测器[39],[40],从卫星图像中提取物理障碍物信息。此类信息有助于通过局部最小值恢复机制[42],提升吞吐量可持续性,优于此 前的有状态地理路由算法[19],[20]以及[41]等无状态地理算法。此外,我们的SPIDER算法具备能量感知和吞吐量性能可持续性特性,这对于灾害响应场景下涉及严苛 MEC与网络环境的人脸识别应用至关重要。
III. 事件支持型移动边缘计算
A. 应用背景与实现

在移动设备上的应用程序中使用面部识别技术,可以帮助识别或验证从本地摄像头/视频源采集的数字图像中人物的身份。我们在研究中使用的面部识别过程包含多个步骤,如图2所示,涉及客户端的数字图像以及服务器端的较大图像样本数据集。
为了在短时间内(即低延迟)初步检测给定图像数据库中的人脸,我们使用开发的移动应用执行一个预处理步骤。在此预处理步骤中,我们将所有输入图像压缩为原始尺寸的1/4,即在每个维度上降采样一半。由于我们预期移动应用将使用相对较小的数据集(数量级为数十张图像),因此压缩对分类精度几乎没有影响。
图像压缩后,将裁剪并缩放为224x224的人脸图像(减去平均人脸)输入到ResNet‐34[43]中的基于深度学习的人脸识别神经网络。该卷积神经网络输出一个嵌入向量,用于最近邻搜索以标记人脸图像。我们采用DLib C ++工具包中用于机器学习[44]的人脸识别模块作为实现平台。DLib的人脸识别(验证任务)实现使用了经过简化、移除若干层且每层滤波器数量减半的ResNet‐34紧凑版本。DLib的人脸识别网络是在来自多个来源(包括 VGG [45])的近7500名个体的300万张人脸图像的合并数据集上进行训练的。初始的N类分类或人脸识别网络仅用作引导阶段,以学习嵌入向量。在验证任务中,目标是判断两张人脸图像是否属于同一身份或代表两个不同的人。
DLib 人脸识别架构在标准的野生标注人脸(LFW)基准数据集上的验证准确率为 99.38% [46]。该性能优于使用 400万张图像、4000个身份训练的 Facebook DeepFace 孪生网络架构(在 LFW 基准上的验证准确率为 97.35% [47], ),以及使用 260万张图像、超过 2600人 训练的 VGG‐Face (验证准确率为 98.95% [45],),并且与 Google FaceNet 的 99.63% 准确率相当,后者采用了对齐技术,并使用了超过 800万个不同身份的 2亿张人脸图像进行训练[48]。
与许多深度学习人脸识别架构类似,DLib 实现学习一个嵌入(一个128维人脸描述向量,使得相同人脸的特征聚集在一起,而不同人的脸在度量学习后(即欧氏距离)能够被有效分离。该128维人脸描述符随后用于人脸识别。也就是说,在训练阶段结束后,可以移除输出训练数据库中所有人员身份权重的softmax分类器层,并将前一层的得分向量用作身份验证的嵌入[45]。为了提高人脸验证性能,通常使用三元组损失训练方案对嵌入特征向量进行调优或直接学习,该方案最小化锚点或基准人脸与正样本之间的距离,同时最大化锚点与负身份之间的距离[48]。在DLib 中,采用一种结构化度量损失,试图通过小批量训练集上的成对hinge损失将所有身份投影到半径0.6的不重叠的球体内,并包含难负例挖掘。嵌入网络在来自数千个唯一身份的数百万张训练人脸的大规模集合上一次性完成学习。当面对新的身份集合进行人脸识别时,首先计算每个训练人脸图像(例如灾害响应人脸图像集合中的图像)的嵌入,然后利用可扩展数据结构进行最近邻搜索,以匹配给定的查询人脸图像。
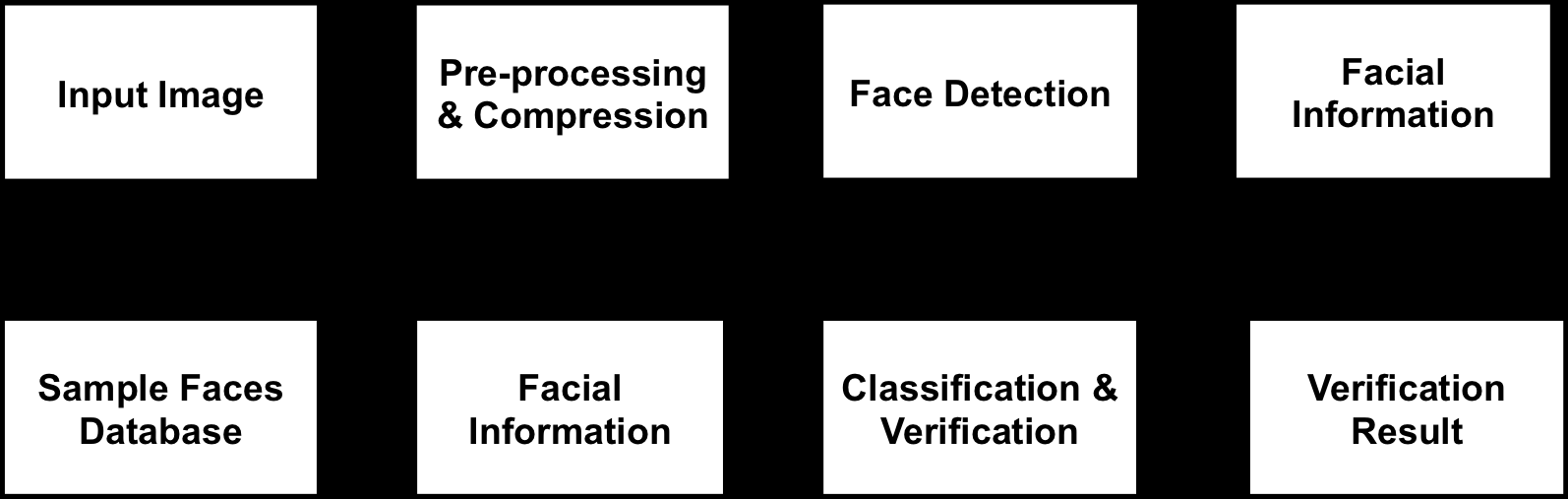
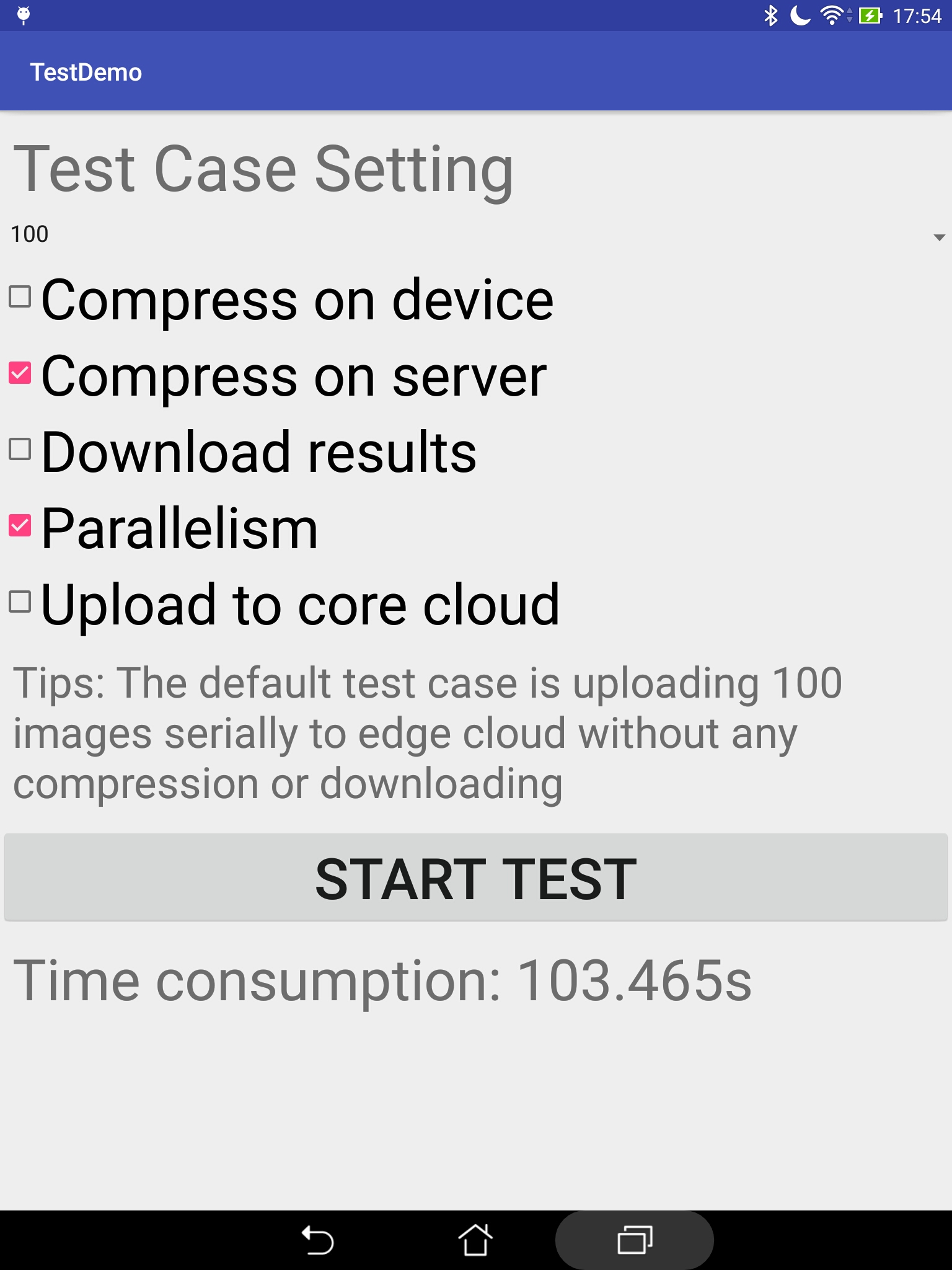
图3显示了我们为安卓设备使用Java编程语言开发的应用程序实现的图形用户界面。上述人脸识别过程已通过 OpenCV [17]进行图像管理,并利用DLib [44]的 Python脚本实现。用户可通过该界面选择不同的计算和图像传输策略(如图3左半部分所示),例如:设备或服务器上的压缩、瘦客户端或胖客户端、串行或并行处理,从而获取匹配图像的名称等结果。目标识别的结果图像及处理时间消耗可从服务器端获得(如图3左半部分所示),支持来自一个或多个物联网设备的同时单张或多张图像上传。
B. 计算卸载决策方法
瘦客户端或胖客户端应用只需将移动设备上的数据发送到云服务器,即可在低延迟处理及相关能耗方面获得更好的结果。然而,在将计算卸载到边缘云还是核心云之间的决策取决于用户需求和工作负载规模。[6]中的作者表明,边缘云可将响应时间从200毫秒缩短至80毫秒,并使能耗降低30%‐40%。然而,由于拥有无限资源和并行实例以加快处理速度,核心云仍然具有优势。因此,我们提出一种算法,根据用户的选择对场景进行分类,以帮助确定最佳的视觉数据处理决策。
图像/照片处理的应用逻辑如图4所示。在照片拍摄完成后,多个决策将对能耗和处理延迟产生影响。例如,照片的转换可以并行或串行方式进行,具体取决于用户的实时处理需求。此外,照片在上传到云平台之前可以进行压缩。显然,压缩后照片尺寸更小,因此上传所需的带宽更低,但会带来额外能耗和时间消耗。若不进行比较和分析,很难判断整体效果是正面还是负面。在胖客户端情况下,当根据用户需求将结果返回设备时,同样会出现类似问题。我们的实验旨在评估从低到高工作负载规模下这些不同条件中的权衡。应用程序的实时性要求是另一个因素,例如,如果人脸识别结果需要立即获取以用于后续操作。在客户端进行后处理时,需要优化工作流程。然而,如果人脸识别结果不需要立即获取,则可以直接在服务器端显示结果,而无需将结果传回客户端。这样可以根据用户需求以及客户端/服务器能力,消除冗余步骤并实现更优的性能。
在考虑能量感知的情况下,将工作负载分配给边缘云或核心云为各种场景引入了额外的挑战。例如,在需要节能且计算时间较短的情况下,必须通过云平台完成处理。然而,由于远程处理,传输图像所产生的额外能耗也会影响处理延迟。在此情况下,将计算任务卸载到边缘云可以节省能源和图像传输时间,但边缘云可能具有有限资源,难以处理大规模工作负载或支持并行处理。因此,应针对不同的工作负载对能耗和延迟指标赋予不同的优先级(或权重),以便在视觉数据处理的端到端步骤中选择合理策略。
算法1 卸载决策
数据:负载信息: resolution, sizeOfLoad, lowWorkload
数据:服务器策略: edgeCloud, coreCloud, numOfServers
数据:用户策略: downloadResults, realTimeProcess, saveEnergy
结果:节省能源并实现低延迟处理的高效方法
函数 threads← createThreads()
/* 在移动设备上创建多个线程以卸载负载均衡数据 */ 到不同的服务器 */
如果 realTimeProcess= true 那么
threads← parallelThreads(sizeOfLoad, numberOfServers)
else
threads← serialThreads(sizeOfLoad, numberOfServers)
end
end
函数 offload(threads)
/*决定将数据卸载到何处进行处理*/
如果 saveEnergy= false 那么
compress(threads)
end
如果 workload(resolution, sizeOfLoad) ≤ lowWorkload 那么
sendTo← edgeCloud
else
sendTo← coreCloud
end
send(threads, sendTo)
end
函数 主函数()
/* 确定最佳客户端配置 */
如果 downloadResults 那么
使用胖客户端
else
使用瘦客户端
end
threads← createThreads()
offload(threads)
end
算法1展示了我们在计算卸载中对能源和延迟的感知步骤。main()函数首先执行,以检查用户是否需要从服务器接收最终结果(如胖客户端情况),或用户端是否适用瘦客户端假设。一旦确定使用瘦客户端或胖客户端,将依次执行两个操作:首先, createThreads()函数确保移动设备根据realTimeProcess和 numberOfServers策略创建多个线程,用于并行或顺序处理;随后,所创建的线程用于启动与所有服务器的UDP/TCP会话在核心云或边缘云中配置的实例。其次,offload() 函数根据 saveEnergy 用户的策略决定是否对线程进行压缩,以权衡能耗与延迟(即处理时间)。具体而言,图像压缩可通过减少数据传输时间来降低延迟,但会增加用户设备的能耗。 offload() 函数还根据工作负载规模决定将数据发送到边缘云还是核心云服务器。直观来说,如果工作负载较大,即图像数量或其分辨率较高,移动设备将直接向核心云发送数据。此外,为避免边缘云过载,移动设备可定期监控边缘/核心云资源,并在传输数据前检查资源可用性。
我们指出,工作负载阈值以及核心/边缘云位置选择取决于应用/基础设施(包括用户设备能力)因素,并分别通过 lowWorkload、 coreCloud和edgeCloud策略进行设定。在存在多个核心/边缘云的情况下,我们的算法可与其他现有方案(如[25],[26])结合使用。此类方案可首先优化核心/边缘云服务器的选择,以确定coreCloud和 edgeCloud服务器策略。基于已确定的用户/服务器策略,我们的算法可随后执行以做出最终的卸载决策。在第六节A部分,我们在实验性的核心/边缘云基础设施中,针对运行的人脸识别应用,对图像处理工作负载水平进行了实验量化。
算法1 渐近计算复杂度。
算法1 以决策树的方式执行,即通过检查一系列预定义策略来确定卸载策略。由于策略数量 P是常数,因此算法1具有以下渐近计算复杂度:
O(P)= O(1). (1)
从公式1可以看出,算法1的复杂性既不依赖于工作负载的大小,也不依赖于基础设施规模。但需要注意的是,指定某些策略(例如 edgeCloud或 coreCloud(最优)服务器(在算法1中使用))可能需要更复杂的算法。
IV. 能量感知与持续性能边缘路由
采用基于策略的卸载决策方案,使我们能够灵活地决定将用户的视觉数据处理任务卸载到“何处”。然而,一个全面的框架还必须解决“如何”卸载用户数据以实现期望的应用质量的问题。在某些灾难事件响应场景中,用户可能更倾向于低延迟的数据处理,而非在电力受限的物联网设备上实现更优的能源管理。因此,亟需一种在灾难事件场景中具备智能性且在决策上灵活、能够应对多样化用户策略的边缘路由算法。在本节中,我们将介绍我们提出的基于可持续策略的智能驱动边缘路由(SPIDER),该方案建立在近期相关研究进展的基础之上地理路由文献在涉及高节点移动性和严重节点故障的灾难事件等挑战性条件下的应用。

A. 移动边缘计算与边缘路由的关系
我们首先描述卸载决策机制与MEC框架内边缘路由之间的关系。图5展示了MEC框架的生命周期:在第一步中,用户向卸载引擎指定其策略,例如瘦客户端与胖客户端、压缩数据与非压缩数据、顺序处理与并行处理、以及节能计算与低延迟计算。基于这些策略,卸载引擎生成关于“何处”卸载用户数据的决策,以满足其潜在需求。该引擎会考虑多种计算/存储因素,如物理资源的不同工作负载水平、设备类型和服务器能力。随后,卸载引擎将用户策略针对计算/存储因素转换为边缘路由引擎所需的网络QoS要求。基于这些要求,路由引擎继而控制‘如何’ 引导用户数据,同时考虑各种网络因素,如节点故障、拥塞和带宽不足。最后,根据所提供的QoA水平,用户可以修改其偏好,并尝试不同的策略组合。
我们指出,采用一种优化吞吐量与能效权衡的基于策略的边缘路由,能够以尽力而为方式协同改进物联网数据卸载。特别是,此类路由优化可实现用户/服务器策略重新考虑,从而进一步改善卸载决策(见第三节‐B)。改变卸载策略反过来还可通过更好地平衡剩余无线网络能量容量与其吞吐量,进一步帮助优化网络性能。然而,这种尽力而为的优化方案相对于网络/计算资源的联合优化而言仍可能是次优的。此外,由于用户策略的事先未知性(例如物联网设备的能效与相应的端到端处理时间之间的权衡),或由于难以获取基础设施的及时全局知识(其无线节点可能受到)移动性和故障(例如,在自然灾害或人为灾难事件中常见的情况)。为了满足移动自组织网络中常见的用户策略和各种网络因素(即严重节点故障、节点移动性、交通拥塞和带宽不足)相关的网络QoS需求,我们提出的SPIDER算法的详细信息将在下一节中介绍。
B. SPIDER解决方案方法
如前所述,我们不仅关注提高在灾后受影响区域的路由吞吐量性能可持续性,还希望使我们的解决方案具备基于策略的特性,以更好地满足移动边缘计算用户的需求。为此,我们的SPIDER解决方案方法利用了以下信息:
1) 每个数据包头部包含一个目标区域(例如,目的IP地址及其GPS位置)以及相应的转发策略(即,节能 versus 低延迟)
2) 每个节点都知道其所有邻居节点的位置和剩余能源级别,例如通过周期性地向它们发送信标发送1
3) 每个节点还了解由边缘云网关检测到的局部障碍物的半径和位置
我们指出,我们的SPIDER解决方案方法对给定的移动自组织网络拓扑结构没有强假设,例如单位圆盘图或对称链路。此外,我们的SPIDER解决方案改进了地理路由的基线性能,并基于我们前期关于吸引力、排斥力和压力贪婪转发(ARPGF)[38]的工作。与ARPGF类似,我们的 SPIDER解决方案交替使用Attraction、Repulsion和 Pressure转发模式。当数据包以吸引力模式转发时,它会根据其地理位置接近目的地而被吸引;相反,当数据包以排斥模式转发时,可根据第四节‐B1中描述的势函数将其从物理障碍物推开。最后,当节点无法在吸引力和排斥力模式下转发数据包时,数据包将在压力模式下进行转发,直到恢复吸引力或排斥力模式为止。
1) SPIDER 目标函数
让我们考虑以下模型,其中节点 n 将数据包 p 转发至目的地 d。在此模型中,节点 n 需要决定将 p 发送给哪个邻居,以首先向 d 推进,并其次在邻居的剩余能量与 p 的总延迟之间根据指定策略进行平衡。需要注意的是, p 的更高延迟可能是由于路径较长,因为较短路径上的节点通常电池消耗更多。我们通过选择节点 n 的邻居 e,使其具有以下目标函数的最小值,从而实现这种平衡:
f(e, d.x, d.y, λ)=λ‖ϕ(e.x, e.y, d.x, d.y)‖+(1−λ)‖E(e)‖,(2)
在某些情况下,信标发送GPS坐标和邻居节点会导致网络能效低下,从而缩短网络寿命并导致无线覆盖范围下降。为了避免这种情况,可以考虑根据节点移动性调整节点的信标发送频率,以延长网络寿命,并覆盖更大的地理距离,例如“战区级”(≈2城市街区)或“区域级”( > 30城市街区)距离。
其中, ϕ(e.x, e.y, d.x, d.y) 是节点 e 相对于目的地节点 d 的凸势函数,该函数可为数据包投递提供理论保障,并以 O (3.291) 的近似度逼近最短路径 [38]; E(e) 表示节点 e 的剩余能量; λ ∈[0, 1] 是一个参数,用于根据指定的 MEC策略 在最短路径近似 ϕ(以实现较低的延迟)与节点的剩余能量 E 水平(以提高整体网络能效)之间进行权衡。
然而,请注意,最小化公式2中的目标函数并不能保证在数据包延迟或整体网络能效方面收敛到全局最优解。这是因为我们的路由方案是一种贪心优化算法,即贪心转发数据包至目的地。相反,全局优化需要完整的网络拓扑知识,而由于严重节点故障、高节点移动性以及其他与灾害事件现场相关的挑战所导致的移动自组织网络的动态性,这种知识在实践中难以获取。
为了计算 ϕ(e.x, e.y, d.x, d.y),SPIDER需要获取有关物理障碍物的额外地理信息,例如人造建筑或天然池塘/ 湖泊以及其他可能因其地理位置[38]附近无线覆盖不足而导致数据包丢失的障碍物。我们将在下一节讨论节点如何获取这些障碍物的半径和中心坐标等地理信息。一旦节点 e获知其本地障碍物 j的半径Rj以及中心坐标 Cj.x和 Cj.y,它将按如下方式计算 ϕ:
ϕ(e.x, e.y, d.x, d.y)= − 1
dist(e.x, e.y, d.x, d.y)
+
+
M
∑
j=1
oj(d.x, d.y)
dist(e.x, e.y, Cj .x, Cj .y)δ
(3)
其中, dist(x1, y1, x2, y2) 是地理距离(例如欧几里得距离); δ 是障碍物势场的衰减阶数,经验证当 δ ∈[1, 2][38] 时性能最佳;而 o j( d.x, d.y) 表示由目的地节点d引起的障碍物 j的势场强度,如下所示:
o j(d.x, d.y)= R δ+1 j δ ·(dist(Cj .x, C j .y, d.x, d.y)+ R j)
2 (4)
2) SPIDER算法
算法2概述了每个节点如何使用吸引模式、排斥模式或压力贪婪转发模式来转发数据包。我们注意到,吸引力模式旨在在无感知障碍物的情况下传输数据包,而排斥模式则旨在具备障碍物感知能力以传输数据包。因此,我们交替使用这两种模式,以在执行数据包的贪婪转发时,最大限度地主动避免陷入局部极小值。压力模式最初由[42]提出,可通过在贪婪转发过程中主动恢复数据包来摆脱局部极小值,从而保证数据包的可达性。
算法2 SPIDER
函数 Repulsive_Forwarding(e, P)
fe← f(e, Pd.x, Pd.y, Pλ)
/* 根据 ϕ获取下一跳 */
nextNodes← Feasible Neighbors(e, P)
nextAddr← argmin
n∈nextNodes
f(n, Pd.x, Pd.y, Pλ)
如果 fe< f(n, Pd.x, Pd.y, Pλ)那么
return nextAddr
else
return NIL
end
end
函数 Attraction_Forwarding(e, P)
//在时间上设置 e.C~← ∅和 e.R~← ∅以省略 P排斥力
fe← f(e, Pd.x, Pd.y, Pλ)
//根据仅包含第一项的 ϕ函数获取下一跳
nextNodes← Feasible Neighbors(e, P)
nextAddr← argmin
n∈nextNodes
f(n, Pd.x, Pd.y, Pλ)
如果 fe< f(n, Pd.x, Pd.y, Pλ)那么
返回 nextAddr
else
返回 NIL
end
end
函数 Pressure_Forwarding(e, P)
//始终返回一个尽力而为的下一跳用于转发
visitsmin← min n∈Nbrs(e) Pvisits(n)
Candidates←{nextAddr ∈ Nbrs(e) 和 Pvisits(n)== visitsmin}
Pvisits(n)← Pvisits(n)+ 1
nextAddr←argmin
n∈Nbrs(e)
f(n, Pd.x, Pd.y, Pλ)
返回 nextAddr
结束
函数 Feasible_Neighbors(e, P)
//根据朝向目的地的方向获取下一跳集合
ϕe←ϕ(e.x, e.y, Pd.x, Pd.y)
foreach n ∈ Nbrs(e) do
ϕn←ϕ(n.x,n.y, Pd.x, Pd.y)
if ϕn < ϕ e then
nextNodes← nextNodes ∪n
end
end
return nextNodes
end
函数main()
//在节点 e接收数据包 P后,算法决定将其发送到 e的哪个邻居
发送 P下一跳
如果 P d ∈ Nbrs(e)那么
nextAddr← P d
else
nextAddr← NIL
如果 e.C~∈/ ∅且 e.R~∈/ ∅则
nextAddr← Repulsive_Forwarding(e, P)
end
如果 nextAddr= NIL 那么
nextAddr← Attraction_Forwarding(e, P)
end
如果 nextAddr= NIL 那么
nextAddr← Pressure_Forwarding(e, P)
end
send(P, nextAddr)
end
算法2的渐近计算复杂度。在最坏情况下,算法2会依次执行全部三种模式:吸引模式、排斥模式和压力模式。每种模式的渐近计算复杂度为 O(k),其中 k为平均节点度。这是因为每个节点需检查
其所有邻居节点的目标函数值 f。因此,算法2具有如下渐近计算复杂度:
O(3 · k)= O(k). (5)
但需要注意的是,无线自组织网络通常具有无标度特性,即此类网络中的平均节点度 k遵循幂律分布,例如 P (k) ∼ k −γ,并且具有较强的聚类特性。因此, k通常不依赖于网络规模。
V. MEC框架架构
在本节中,我们描述了我们的MEC框架架构,该架构结合了卸载决策方案和SPIDER解决方案方法,应用于包含以下特点的灾难场景:(a) 用于增强视觉态势感知的人脸识别应用;(b) 用于提升SPIDER性能的深度学习。
如图6所示,我们组合的MEC框架架构由三个逻辑组件构成:MEC框架本身;与其用户物联网设备和仪表板交互的卸载引擎;以及利用核心云中的深度学习服务来协调我们在移动自组织网络环境中的SPIDER路由的MEC路由引擎。
边缘处的MEC框架
我们架构的第一个核心逻辑组件是部署在边缘云上的MEC框架,通过网关与用户物联网设备进行低延迟交互。我们的MEC框架包含两个主要服务组件——卸载引擎和路由引擎,它们协同决定在混合核心/ 边缘云中‘何处’以及‘如何’卸载物联网数据处理任务。特别是,我们的卸载引擎需要在考虑指定的用户策略和各种计算资源的情况下,为物联网增强所需的存储和计算资源。计算/存储因素,如工作负载水平、设备类型和服务器能力。我们的路由引擎需要根据指定的用户策略以及各种网络因素(如故障节点、流量拥塞和带宽不足)来引导流量,以实现所需的网络QoS。
MEC卸载引擎、用户仪表板和物联网
物联网设备(如安防摄像头、民用智能手机和空中视角)收集患者视觉数据,这些数据的处理需要混合边缘/核心云提供的计算和存储资源。为了向用户物联网设备补充所需的计算/存储资源,我们使用了“卸载引擎”。根据指定的用户策略,该引擎决定合适的卸载策略,例如,是否应将物联网数据处理卸载到边缘或核心云。在我们的架构中,我们使用仪表板允许用户指定其卸载策略,即压缩/非压缩、瘦客户端/胖客户端、并行/顺序处理以及节能卸载与低延迟处理之间的权衡。最后,在获得新的处理数据后,用户可能还希望使用仪表板在地图上搜索数据集,或通过核心云存储共享这些数据以供公众访问,例如,新的面部数据可以上传至公共患者数据库,用于匹配和验证,从而有助于寻找失踪人员。
MEC路由引擎、SPIDER和深度学习
在接收到来自卸载引擎的网络QoS指导以及用户策略(见第IV‐A节)后,我们的路由引擎会指示相应的用户物联网设备如何发送其数据。为此,路由引擎向这些物联网设备发送特定的 λ 参数,这些参数需要存储在其数据包头部中,以供后续在我们的SPIDER目标函数 f中使用(见公式2)。此外,基于用户物联网设备的地理位置,有必要学习地理环境障碍物(如人造建筑或天然湖泊或池塘),以提升本区域 SPIDER算法的地理路由性能。我们指出,此类障碍物在其半径范围内可能因无线连接缺失而导致数据包丢失。在救援区域被学习完成后,我们的“路由引擎”通过网关将发现的地理障碍物信息传播给灾害事件现场的MANET节点。进一步地,MANET中的节点 n仅存储位于其两个半径范围内的障碍物信息[38]。我们指出, n需要此信息来计算其 ϕ(n)(见公式3)。
为了获取有关地理障碍的信息(无论是主动还是被动),我们的路由引擎可以利用深度学习检测器和包含灾害事件现场卫星图像(不一定是最新图像)的公开地图API。当用户仪表板上提供地图API时,我们的路由引擎甚至可以在不使用核心云深度学习服务的情况下检测障碍物,即离线运行。例如,“你只需看一次(YOLO)”[39]深度学习检测器仅使用一个包含26层的神经网络对图像中的对象进行标注,这使其更易于在资源受限的边缘云上运行。然而,与更复杂(即资源需求更高)的深度学习检测器 [39],[40]相比,其性能可能较差。因此,我们建议避免在边缘云服务器上使用深度学习,而应在核心云中使用。为此,需要将收集并部分标注的训练样本上传至核心云,以进行监督或半监督深度学习[49],从而提升检测器未来的性能。我们指出,在给定的卫星地图上找到最优(即最准确)的障碍物检测方法可进一步提升我们路由引擎的性能,但此类研究超出了本文的范围。
六、性能评估
在本节中,我们首先通过多种策略评估了我们的能量感知和低延迟MEC框架,这些策略包括从低到高的工作负载、瘦客户端或胖客户端,以及在核心云和边缘云上的顺序或并行处理。随后,我们通过大量仿真评估了SPIDER算法的性能,仿真中采用了多种策略以及在高节点移动性和严重节点故障条件下的真实灾害场景中的受损区域。
A. 视觉数据处理评估
实验设置。 图7显示了我们的实验测试平台设置,其中我们使用密苏里大学本地服务器资源[15]作为边缘云,并在纽约大学(NYU)校园使用 10个GENI服务器实例作为核心云。我们的边缘云服务器具有70GB内存、12核,带宽约为90 Mbps。每个核心云服务器具有1核和1GB内存,并以约900 Mbps的带宽连接。我们使用配备2GB内存、1.33 GHz AtomZ3735处理器和 8小时电池续航(在正常使用情况下)的华硕Zenpad平板电脑作为运行第三节中描述的人脸识别应用的移动设备。

比较方法与指标。 我们比较了使用瘦客户端或胖客户端配置的情况。具体而言,用户的瘦客户端配置假设所有处理后的图像都存储并查看于远程云资源,而胖客户端配置则假设处理后的图像被下载并在移动设备层面进一步进行后处理。我们通过将移动设备上的应用程序线程卸载到云计算层以进行远程处理来启动实验,如图7所示。我们将处理工作负载从100到1000张图像(大小为2048 x 1536像素)变化,并通过UDP协议将这些图像传输到远程服务器端。我们还采用了不同的MEC策略,包括并行(Par)处理与串行或顺序(Seq)处理,以及数据压缩(C)与无压缩(NC)策略。我们使用基于Android的PowerTutor工具[16]在测试平台设置中对人脸识别应用的能耗进行分析和估算(指标:焦耳)。我们的端到端处理时间包括将图像导出/导入边缘云或核心云及其远程处理所需的时间(指标:处理时间(秒))。在物联网设备上,我们在向核心云或边缘云卸载时,使用瘦客户端(见顶部)和胖客户端(见底部),并结合并行(Par)或顺序(Seq)处理策略,以及数据压缩(C)或无数据压缩(NC)策略。
B. 讨论
基于策略的优化。 我们通过讨论MEC框架的最优策略集(由图4中的决策参数组合定义)来开始对其评估,这些策略集涵盖了多样化的用户需求和输入数据规模。根据图8a和 8e中的能耗结果,我们观察到为实现移动设备的最长运行时间所需的策略:对于瘦客户端和胖客户端配置,都需要在非压缩数据上采用并行处理。这一观察结果的原因在于,数据压缩会显著占用移动设备的CPU资源,而顺序数据卸载还会因数据导出/导入带来额外能耗。但需注意,在这种情况下,将任务卸载至边缘云或核心云对移动设备内部的能耗没有影响。然而,图 8b和 8f中显示的处理时间结果表明,我们针对最小端到端处理时间的最优MEC策略已发生变化。特别是,对于瘦客户端和胖客户端配置,现在都需要在压缩数据上采用并行处理。此外,当工作负载规模较低时(例如 ≤ 500张图像),我们可以通过将任务卸载至边缘云而非核心云来进一步加快远程处理速度。这种差异是由于将数据传输到云存在更高延迟,且随着工作负载规模的增加,该延迟的影响加剧;在这种情况下,边缘云处理所有数据所需的时间比核心云更长。还需注意,在两种情况下,顺序卸载策略均能同时带来能耗和处理时间上的优势。然而,该策略适用于实时图像数据(如视频流),其中新帧是按顺序捕获的。此外,在瘦客户端和胖客户端配置下,提升交互性在所有情况下都会导致更高的能耗。
工程权衡与帕累托最优。 在实践中,用户通过考虑在合理能耗下的可接受性能,而不仅仅是关注之前讨论的单一因素,也能从中受益。下面,我们展示不同的策略选择如何成为针对不同应用能耗和处理时间权衡的帕累托最优 MEC框架策略的一部分。具体而言,当观察低工作负载规模(即处理 ≈300张图像时)的图 8c和图 8g时,我们可以看到在边缘或核心云对压缩数据和非压缩数据进行并行处理,均属于瘦客户端和胖客户端配置下的帕累托最优解集。更具体地说,以瘦客户端为例,在核心云上对压缩数据和非压缩数据进行并行处理可能位列最优解决方案的前两位。总体而言,这两种方案都能实现相对较低的能耗和较短的端到端计算时间,但各自具有特殊优势。使用压缩数据进行处理的计算时间比处理非压缩数据减少65%,但其能耗高出46%;而处理非压缩数据的能耗可能降低31.5%,但端到-end处理的计算时间增加191.4%。在某些情况下,用户可以选择最优解决方案根据它们特定的处理需求。总之,所有这些策略组合都不会导致应用性能在能耗和端到端处理时间两个方面同时下降的情况。
然而,对于高数据工作负载(即处理 ≈1000张图像时)情况则不同。特别是,观察图 8d和 8h可以发现,在使用胖客户端配置时,边缘云对压缩数据和非压缩数据的并行处理并不属于帕累托最优解集的一部分。在此场景下,核心云对非压缩数据进行并行处理是最优解,因其具有最低的能耗和第三短的端到-end计算时间(相比最短计算时间方案仅多消耗83%的计算时间,但节省了49%的能耗)。出现这一结果的原因在于,边缘处理时间主导了较高的数据导出/导入云延迟。因此,在我们的人脸识别应用背景下,对于胖客户端在高数据工作负载下将计算卸载至边缘云,始终不如卸载至核心云更优。
C. 边缘路由评估
为了评估我们的SPIDER性能,我们在NS‐3中使用具有严重节点故障和高节点移动性的现实灾难事件场景。然后将其性能与灵活无状态贪婪路由GEAR协议[41]进行比较。我们还将SPIDER与常见的有状态自组织路由解决方案进行比较:已知的反应式按需距离向量(AODV)协议 [19];以及结合了反应式(使用AODV)和主动路由(使用生成树)的混合无线网状网络(HWMP)协议 802.11s标准[20]。
仿真设置。 在评估中,我们在NS‐3仿真器[18]中实现了我们的SPIDER算法。还使用了因2011年袭击密苏里州乔普林的龙卷风导致乔普林高中和乔普林医院建筑物受损的真实受灾场景(见图9 (a) 和 (b))。我们从现有的卫星影像地图中获取了显示龙卷风影响的受灾场景信息 [50]。利用该场景信息,我们在移动性和严重节点故障条件下评估无状态贪婪转发算法的性能。我们假设受损建筑的信息(i.e.、其中心坐标和半径)由边缘云通过网关提供,数据来源于救援区域的卫星图像以及核心云中利用深度学习障碍检测器进行分析的结果(见第五节)。
在我们的灾难事件实验场景中,一名急救员作为数据源,通过移动自组织网络将数据发送到网关。现场采集的视频流通过UDP会话发送到边缘云,并与核心云协同进行进一步的数据处理。我们模拟了由急救员佩戴的抬头显示设备 e.g.(谷歌眼镜作为视觉数据源)通过UDP连接传输5 Mbps高清图像的过程。需要指出的是,此类物联网设备不具备足够的计算和存储资源来本地执行人脸识别功能,因此必须将其捕获的视频流发送到混合边缘/核心云。急救员在每位患者位置停留3分钟,并以慢跑速度(≈ 6 mph)在这些位置之间移动。该模拟设计使得当急救员靠近第二或第三位患者位置时,地理路由将面临一个废弃的无线覆盖区域。
除了源移动性外,在节点故障仿真场景中(见图9a),由于存在间歇性可用电源或灾难现场附近的物理损坏,障碍物周围的节点可能会在接下来的30秒内发生故障。其故障概率从[5%,50%], i.e.区间内抽取,范围从低到严重节点故障。在这些故障情况下,由于丢包(例如由数据包碰撞引起)随路径长度或有状态路由方法的路径重建而增加,导致有效吞吐量下降。请注意,在此类节点故障场景中,任何“存储转发”解决方案都可能不适用 [51],[52]。
然后,我们在第二次仿真场景中评估节点移动性的影响(见图9b),其中急救人员只能通过在道路车辆上的移动与边缘网关通信,速度从 ≈ 10 mph(低)变化到 ≈ 40 mph(高)。需要注意的是,在此类移动性条件下,任何有状态路由方案(i.e.,依赖于网络拓扑知识如生成树)都将表现出较差的性能[53]。
最后,节点被放置在步长为50 ‐ 150米的网格上,每个节点的无线通信范围为250米,并且在该网格中心附近有一个障碍物(一座建筑物)。每个节点大约有 3 − 10个邻居节点以实现容错性。表I总结了我们所有的模拟细节。
表I:仿真环境设置
| 总体设置: | 节点数量: 30 ‐ 40 | 频率: 2.4 GHz |
| — | — | — |
| | 节点故障周期: ≈ 0.033 Hz | 发射功率: 20 分贝毫 |
| | 节点故障概率:0.05 ‐ 0.5 | 发射增益: 6 dB |
| | 移动节点速度:10 ‐ 40英里/小时 | 收增益: 0 dB |
| | 每个位置的时间: 180 秒 | 检测阈值:‐68.8 dBm |
| | 源速度: 6 英里/小时 | 延迟传播模型:CONSTANTSPEED |
| | 仿真时间: 720 ‐ 780 秒 | 损耗传播模型:双射线 |
| | 信标频率: 1 ‐ 4赫兹 | 802.11g/s |
| | | 调制: OFDM |
| | | 数据速率: 54 Mb p s |
| 拓扑结构: | 网格放置: 50 ‐ 150 米 | 技术: 802.11g/s |
| | 1 st障碍物大小: 600 x 300 米 | |
| | 2 nd障碍物大小 400x 400 米 | |
| | 无线通信范围: 250米 | |
| | 平均节点度: ≈ 3 − 10 | |
| 传输层/应用层: | 传输协议: UDP | |
| | 有效载荷: 1448 字节 | |
| | 应用比特率:5兆比特每秒 | |
比较方法与指标 在我们的实际仿真中,我们通过不同策略的实验来评估SPIDER和GEAR的路由性能。例如,我们尝试设置 λ= 1以获得最佳的延迟和吞吐量结果, λ= 0以实现最佳能效,以及 λ ∈{0.25, 0.50, 0.75}以在能效、吞吐量和延迟之间取得平衡的解决方案。我们使用一个简单的能量模型,其中每个节点的初始能源预算相同(即1000焦耳),在发送或接收一个数据包时均消耗一个单位的能量。然后通过计算网络中所有节点电池的剩余能量的平均值,得出网络的residualenergy(单位为焦耳)。我们还测量急救视频流到边缘云的应用层throughput(单位为Mbps)。
D. 讨论
SPIDER 和 HWMP 是帕累托最优的路由策略。 图10 显示,在公式2 中测试的每个参数下,我们的 SPIDER 在应用吞吐量水平方面均优于相关的 GEAR 和 AODV 协议,同时在能效方面也相当或更优。然而,由于 HWMP 能够利用生成树来减少控制消息的数量,因此其能效优于 SPIDER。但是,这些生成树在严重节点故障或高节点移动性情况下会降低 HWMP 的性能,导致其应用吞吐量相较于其他协议最低。因此,我们得出结论:SPIDER 和 HWMP 在移动自组织网络中均为帕累托最优的路由策略,即这些路由策略不存在能够在不使至少一个偏好准则(如能源或低延迟)变差的情况下,使任一偏好准则更优的替代策略。
过度强调单跳能效可能导致网络能效变差。 观察图10时,我们注意到 λ= 0并不总是带来GEAR和SPIDER的最佳网络能效。例如,图10a、10b和10d显示了GEAR和 SPIDER分别在 λ= 0.75、 λ= 0.5和 λ= 0.25时达到最佳网络能效。该结果的原因在于,过分强调数据包单跳转发的能效可能会迫使它们经过更长路径,从而导致这些数据包的路由消耗整个网络更多的能源。因此,我们建议使用 λ= 0.25来优化路由能效,并使用 λ= 1以实现最高的应用层吞吐量以及低延迟处理。或者,也可以考虑在实时中更改 λ策略,以动态适应各种灾难事件场景。
SPIDER improves routing sustainability in MANETs. 由于救援区域的额外地理知识(以及地理坐标),我们的SPIDER实现了如图10所示,吞吐量性能可持续性最高。这是因为在进入废弃的无线网络覆盖区域时,常见的基于地理位置的路由方法(例如GEAR)仅依靠地理坐标无法转发数据包;该问题在优化领域中被称为局部最小值问题。因此, GEAR进入恢复模式并使用平面化方法,而这反过来可能导致路径显著延长。然而,路径延长会降低应用层吞吐量并增加数据包延迟,进而导致人脸识别或任何其他灾害响应应用中传输视频流的质量下降。
尽管AODV和HWMP相较于纯主动状态路由解决方案具有优势,但在复杂灾害场景中,它们并未表现出可接受的吞吐量水平。这可能导致服务中断或频繁断开连接。近期在状态式地理路由文献中的解决方案有助于应对部分灾害事件挑战[54],[55]。例如,近期的地理路由方案在严重节点故障情况下已显示出良好的效果[55]。然而,我们尚未发现能够同时应对严重节点故障和高节点移动性条件的地理路由算法。
基于上述结果,我们得出结论:我们的SPIDER算法通过了解救援区域内的地理障碍,提高了路由可持续性,表现出能量感知能力,并提升了用户应用程序的质量——在大多数情况下,这使其能够利用其排斥力转发模式避免局部极小值。
VII. 结论与未来工作
本文研究了移动边缘计算(MEC)范式如何为希望在节能与低延迟之间进行权衡的用户提供灵活性,特别是在基于视觉物联网的应用数据处理中。我们的工作基于一个基本原理:计算应尽可能靠近数据源进行,而将云服务尤其是向网络边缘靠近,能够为满足用户在能耗和快速处理时间方面的需求提供机会。我们开发了一款用于移动设备的人脸识别应用,通过该应用展示了在低到高视觉数据处理工作负载下,瘦客户端或胖客户端配置各自更为有效的场景,并探讨了卸载策略如何影响能效或低延迟的用户需求。特别地,实验结果表明,在高工作负载下,胖客户端采用边缘云卸载策略始终不如核心云卸载策略最优;但在相同条件下,这一情况并不适用于瘦客户端。
此外,我们解决了在移动自组织网络中缺乏可持续且灵活的路由方法来卸载人脸识别应用处理的问题,以在能源感知与低延迟数据传输至受损基础设施区域内的边缘云网关之间进行权衡。具体而言,我们提出了可持续基于策略的智能驱动边缘路由(SPIDER)算法,该算法建立在地理路由领域最新进展的基础之上。为了提升其基础地理路由性能,SPIDER采用了附加的从救援区域公开可用的卫星图像中获取的地理知识,以及在核心云中使用深度学习检测器获得的信息。为了以尽力而为的方式在能量感知和低延迟数据传输之间取得平衡,我们的SPIDER算法采用了可调节的目标函数。通过考虑多种实际灾害事件相关场景,我们展示了与无状态地理路由方案(即GEAR和GPGF)以及有状态的反应式网状路由(即AODV和HWMP)相比,我们的SPIDER算法更具灵活性和可持续性。
作为未来工作的一部分,可以实现具有负载均衡的实用路由协议,以在移动边缘计算环境中存在多个服务器时支持并行处理。此外,当移动自组织网络中由于用户活动频繁导致无线网络出现干扰时,可采用信道自适应技术来应对干扰,该技术能够:(a) 最小化数据包丢失的可能性,以及 (b) 提升物联网设备的能效。

















 41
41

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









