







在Java编程语言中,最基本的结构就是两种,一个是数组,另外一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造的,HashMap也不例外。HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结构,但是在jdk1.8里
加入了红黑树的实现,当链表的长度大于8时,转换为红黑树的结构。
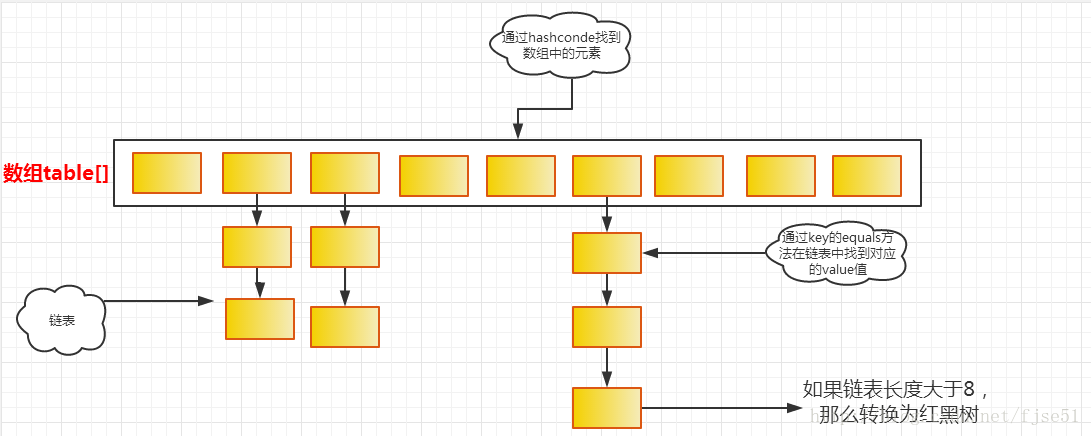
从上图中可以看出,Java中HashMap采用了链地址法。链地址法,简单来说,就是数组加链表的结合。在每个数组元素上都一个链表结构,当数据被Hash后,得到数组下标,把数据放在对应下标元素的链表上。
*/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;//用于定位数组索引的位置
final K key;
V value;
Node<K,V> next;//链表的下一个Node
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
Node是HashMap的一个内部类,实现了Map.Entry接口,本质是就是一个映射(键值对)。
有时两个key会定位到相同的位置,表示发生了Hash碰撞。当然Hash算法计算结果越分散均匀,Hash碰撞的概率就越小,map的存取效率就会越高。
HashMap类中有一个非常重要的字段,就是 Node[] table,即哈希桶数组,明显它是一个Node的数组。如果哈希桶数组很大,即使较差的Hash算法也会比较分散,如果哈希桶数组数组很小,即使好的Hash算法也会出现较多碰撞,所以就需要在空间成本和时间成本之间权衡,其实就是在根据实际情况确定哈希桶数组的大小,并在此基础上设计好的hash算法减少Hash碰撞。那么通过什么方式来控制map使得Hash碰撞的概率又小,哈希桶数组(Node[] table)占用空间又少呢?答案就是好的Hash算法和扩容机制。
如果哈希桶数组很大,即使较差的Hash算法也会比较分散,如果哈希桶数组数组很小,即使好的Hash算法也会出现较多碰撞,所以就需要在空间成本和时间成本之间权衡,其实就是在根据实际情况确定哈希桶数组的大小,并在此基础上设计好的hash算法减少Hash碰撞。
这里存在一个问题,即使负载因子和Hash算法设计的再合理,也免不了会出现拉链过长的情况,一旦出现拉链过长,则会严重影响HashMap的性能。于是,在JDK1.8版本中,对数据结构做了进一步的优化,引入了红黑树。而当链表长度太长(默认超过8)时,链表就转换为红黑树,利用红黑树快速增删改查的特点提高HashMap的性能,其中会用到红黑树的插入、删除、查找等算法
HashMap 在JDK 7 与 JDK8 下的差别
顺便理一下HashMap.get(Object key)的几个关键步骤,作为后面讨论的基础。
1.1 获取key的HashCode并二次加工
因为对原Key的hashCode质量没信心,怕会存在大量冲突,HashMap进行了二次加工。
JDK7的做法:
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
JDK8 因为对自己改造过的哈希大量冲突时的红黑树有信心,所以简单一些,只是把高16位异或下来。
return h ^ (h >>> 16);
所以即使Key比较均匀无哈希冲突,JDK8也比JDK7略快的原因大概于此。
顺便科普一下,Integer的HashCode就是自己,Long要把高32位异或下来变成int, String则是循环累计结果*31+下一个字符,不过因为String是不可变对象,所以生成完一次就会自己cache起来。
1.2 落桶
index = hash & (array.length-1);
桶数组大小是2的指数的好处,通过一次&就够了,而不是代价稍大的取模。
1.3 最后选择Entry
判断Entry是否符合,都是首先哈希值要相等,但因为哈希值不是唯一的,所以还要对比key是否相等,最好是同一个对象,能用==对比,否则要走equals()。 比如String,如果不是同一个对象,equals()起来要一个个字符做比较也是挺累的。
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
更累的是存在哈希冲突的情况,比如两个哈希值取模后落在同一个桶上,或者两条不同的key有相同的哈希值。
JDK7的做法是建一条链表,后插入的元素在上面,一个个地执行上面的判断。
而JDK8则在链表长度达到8,而且桶数量达到64时,建一棵红黑树,解决严重冲突时的性能问题。
2. 很多人忽视的加载因子Load Factor
加载因子存在的原因,还是因为减缓哈希冲突,如果初始桶为16,等到满16个元素才扩容,某些桶里可能就有不止一个元素了。所以加载因子默认为0.75,也就是说大小为16的HashMap,到了第13个元素,就会扩容成32。
2.1 考虑加载因子地设定初始大小
相比扩容时只是System.arraycopy()的ArrayList,HashMap扩容的代价其实蛮大的,首先,要生成一个新的桶数组,然后要把所有元素都重新Hash落桶一次,几乎等于重新执行了一次所有元素的put。
所以如果你心目中有明确的Map 大小,设定时一定要考虑加载因子的存在。
Map map = new HashMap(srcMap.size())这样的写法肯定是不对的,有25%的可能会遇上扩容。
Thrift里的做法比较粗暴, Map map = new HashMap( 2* srcMap.size()), 直接两倍又有点浪费空间。
Guava的做法则是加上如下计算
(int) ((float) expectedSize / 0.75F + 1.0F);
2.2 减小加载因子
在构造函数里,设定加载因子是0.5甚至0.25。
如果你的Map是一个长期存在而不是每次动态生成的,而里面的key又是没法预估的,那可以适当加大初始大小,同时减少加载因子,降低冲突的机率。毕竟如果是长期存在的map,浪费点数组大小不算啥,降低冲突概率,减少比较的次数更重要。
3. Key的设计
对于String型的Key,如果无法保证无冲突而且能用==来对比,那就尽量搞短点,否则一个个字符的equals还是花时间的。
甚至,对于已知的预定义Key,可以自己试着放一下,看冲不冲突。比如,像”a1”,”a2”,”a3” 这种,hashCode是个小数字递增,绝对是不冲突的:)
4. EnumMap
对于上面的问题,有些同学可能会很冲动的想,这么麻烦,我还是换回用数组,然后用常量来定义一些下标算了。其实不用自己来,EnumMap就是可读性与性能俱佳的实现。
EnumMap的原理是,在构造函数里要传入枚举类,那它就构建一个与枚举的所有值等大的数组,按Enum. ordinal()下标来访问数组,不就是你刚才想做的事情么?
美中不足的是,因为要实现Map接口,而 V get(Object key)中key是Object而不是泛型K,所以安全起见,EnumMap每次访问都要先对Key进行类型判断。在JMC里录得不低的采样命中频率。
所以也可以自己再port一个类出来,不实现Map接口,或者自己增加fastGet(),fastPut()的函数。
5. IntObjectHashMap
Netty以及其他FastUtils之类的原始类型map,都支持key是int或 long。但两者的区别并不仅仅在于int 换 Integer的那点空间,而是整个存储结构和Hash冲突的解决方法都不一样。
HashMap的结构是 Node[] table; Node 下面有Hash,Key,Value,Next四个属性。
而IntObjectHashMap的结构是int[] keys 和 Object[] values.
在插入时,同样把int先取模落桶,如果遇到冲突,则不采样HashMap的链地址法,而是用开放地址法(线性探测法)index+1找下一个空桶,最后在keys[index],values[index]中分别记录。在查找时也是先落桶,然后在key[index++]中逐个比较key。
所以,对比整个数据结构,省的不止是int vs Integer,还有每个Node的内容。
而性能嘛,IntObjectHashMap还是稳赢一点的,随便测了几种场景,耗时至少都有24ms vs 28ms的样子,好的时候甚至快1/3。
优化建议
- 考虑加载因子地设定初始大小
- 减小加载因子
- String类型的key,不能用==判断或者可能有哈希冲突时,尽量减少长度
- 使用定制版的EnumMap
- 使用IntObjectHashMap















 389
389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









