







### Hive是什么
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射成为一张数据库表,并提供类SQL的查询功能。可以将sql语句转化为MapReduce任务进行运行。Hive提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。
### 为什么使用Hive
1.) 直接使用hadoop所面临的问题
人员学习成本太高
项目周期要求太短
MapReduce实现复杂查询逻辑开发难度太大
2.)
操作接口采用类SQL语法,提供快速开发的能力。
避免了去写MapReduce,减少开发人员的学习成本。
扩展功能很方便。
### Hive 的特点
1.)可扩展
Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。
2.)延展性
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
3.)容错
良好的容错性,节点出现问题SQL仍可完成执行
### Hive 的优缺点
优点:
1. 学习成本低,只要会sql就能用hive
2. 开发效率高,不需要编程,只需要写sql
3. 模型简单,易于理解
4. 针对海量数据的高性能查询和分析
5. HiveQL 灵活的可扩展性(Extendibility)
6. 高扩展性(Scalability)和容错性
7. 与 Hadoop 其他产品完全兼容
缺点:
1. 不支持行级别的增删改
2. 不支持完整的在线事务处理
3.本质上仍然是MR的执行,效率不算高
### HIVE 架构
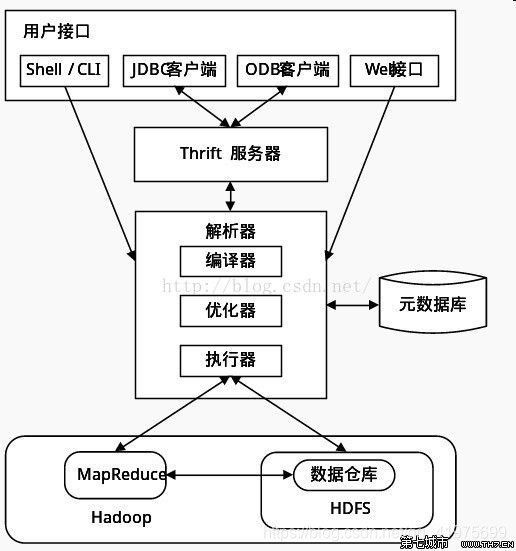
1.) 用户接口:包括 CLI、JDBC/ODBC、WebGUI。
2.) 元数据存储:通常是存储在关系数据库如 mysql , derby中。
3.) 解释器、编译器、优化器、执行器。
### Hive 中的压缩格式 RCFile、 TextFile、 SequenceFile 各有什么区别?
TextFile:默认格式,数据不做压缩,磁盘开销大,数据解析开销大。
SequenceFile:Hadoop API提供的一种二进制文件支持,使用方便,可分割,可压缩,支持三种压缩,NONE,RECORD,BLOCK。
RCFILE:是一种行列存储相结合的方式。首先,将数据按行分块,保证同一个record在同一个块上,避免读一个记录读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。数据加载的时候性能消耗大,但具有较好的压缩比和查询响应。
### Hive 数据倾斜的解决方案
数据倾斜是进行大数据计算时最经常遇到的问题之一。当我们在执行HiveQL或者运行MapReduce作业时候,如果遇到一直卡在map100%,reduce99%一般就是遇到了数据倾斜的问题。数据倾斜其实是进行分布式计算的时候,某些节点的计算能力比较强或者需要计算的数据比较少,早早执行完了,某些节点计算的能力较差或者由于此节点需要计算的数据比较多,导致出现其他节点的reduce阶段任务执行完成,但是这种节点的数据处理任务还没有执行完成。
1)group by
group by,我使用Hive对数据做一些类型统计的时候遇到过某种类型的数据量特别多,而其他类型数据的数据量特别少。当按照类型进行group by的时候,会将相同的group by字段的reduce任务需要的数据拉取到同一个节点进行聚合,而当其中每一组的数据量过大时,会出现其他组的计算已经完成而这里还没计算完成,其他节点的一直等待这个节点的任务执行完成,所以会看到一直map 100% reduce 99%的情况。
解决方法:set hive.map.aggr=true ;
set hive.groupby.skewindata=true
原理:hive.map.aggr=true 这个配置项代表是否在map端进行聚合
hive.groupby.skwindata=true 当选项设定为 true,生成的查询计划会有两个 MR Job。第一个 MR Job 中,Map 的输出结果集合会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;第二个 MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。
2)map和reduce优化。
1.当出现小文件过多,需要合并小文件。可以通过set hive.merge.mapfiles=true来解决。
2.单个文件大小稍稍大于配置的block块的大写,此时需要适当增加map的个数。
解决方法:set mapred.map.tasks个数
3.文件大小适中,但map端计算量非常大,如select id,count(*),sum(case when...),sum(case when...)...需要增加map个数。
-解决方法:set mapred.map.tasks个数,set mapred.reduce.tasks个数
3)当HiveQL中包含count(distinct)时
如果数据量非常大,执行如select a,count(distinct b) from t group by a;类型的SQL时,会出现数据倾斜的问题。
解决方法:使用sum...group by代替。如select a,sum(1) from (select a, b from t group by a,b) group by a;
4)当遇到一个大表和一个小表进行join操作时
解决方法:使用mapjoin 将小表加载到内存中。
如:select /*+ MAPJOIN(a) */
a.c1, b.c1 ,b.c2
from a join b
where a.c1 = b.c1;
5)遇到需要进行join的但是关联字段有数据为空,如表一的id需要和表二的id进行关联
解决方法1:id为空的不参与关联
比如:select * from log a
join users b
on a.id is not null and a.id = b.id
union all
select * from log a
where a.id is null;
解决方法2:给空值分配随机的key值
如:select * from log a
left outer join users b
on
case when a.user_id is null
then concat(‘hive’,rand() )
else a.user_id end = b.user_id;
### Hive中追加导入数据的4种方式是什么?请写出简要语法
|
### Hive 分区表
分区表指的是在创建表时指定的partition的分区空间,避免全表扫描,提高查询效率
### Hive 桶
分区提供了一个隔离数据和优化查询的便利方式,不过并非所有的数据都可形成合理的分区,
尤其是需要确定合适大小的分区划分方式,(不合理的数据分区划分方式可能导致有的分区数据过多,而某些分区没有什么数据的尴尬情况)
试试分桶是将数据集分解为更容易管理的若干部分的另一种技术。
数据分桶的原理:
跟MR中的HashPartitioner的原理一模一样
MR中:按照key的hash值去模除以reductTask的个数
Hive中:按照分桶字段的hash值去模除以分桶的个数
Hive也是 针对某一列进行桶的组织。Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
好处:
1、方便抽样
2、提高join查询效率
(1)获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
(2)使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
### 分桶字段的要求是
分桶字段必须是表中的字段
### 内部表与外部表的区别
内部表数据由Hive自身管理,外部表数据由HDFS管理;
删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除;
### order by与sort by的区别
使用order by会引发全局排序
使用sort by会引发局部排序
### Hive声明参数有哪些方式,优先级是什么
配置文件<命令行参数<参数声明
### 企业中hive常用的数据存储格式是什么?常用的数据压缩格式是什么?
存储格式是ORC格式,数据压缩格式是snappy















 773
773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









