







目录
优化策略
- 合并请求
- 数据并发处理
- 数据异步渲染
对于系统首页的处理数据量不大,可以通过合并请求的方式实现。
后端代码可以通过并发多线程的方式处理数据访问,缩短等待时间。
前端html渲染异步化, 可以避免页面渲染和数据互相等待。
JSON格式模块化
{
"HNGS_GSWH_GSGS": [
{
"JJ": "额",
"BT": "测试",
"NR": "<p>vd</p>",
"SJ": 1582905600000,
"MZGUID": "202002/d539bbc653c44fa1b194cac4b11486c5.png",
"PK_UID": 2
},
{
"JJ": "好几款发过火",
"BT": "豆腐花多少",
"NR": "<p>东方国际地方发动机的</p>",
"SJ": 1578931200000,
"MZGUID": "202001/3c1fca05ced647aa902df4a0ffa19e52.jpg",
"PK_UID": 1
}
],
"HNGS_GZDT": [
{
"BT": "工作动态:湖南古树名木运维系统就要上线了",
"FBSJ": 1572364800000,
"PK_UID": 3
},
{
"BT": "工作动态:林业工作汇报",
"FBSJ": 1572278400000,
"PK_UID": 1
},
{
"BT": "图片上传",
"FBSJ": 1573747200000,
"PK_UID": 52
},
{
"BT": "工作动态:严格按照章程作业",
"FBSJ": 1572364800000,
"PK_UID": 2
}
],
"HNGS_GSWH_XCQH": [
{
"BT": "阿斯蒂芬",
"SJ": 1572537600000,
"PK_UID": 1
}
],
"HNGS_GSWH_ZXTC": [
{
"BT": "都发过火凤凰",
"SJ": 1570982400000,
"MZGUID": "201912/2015年10月木材战略储备基地建设珍贵用材树种培育技术管理培训班资料汇编(201510).pdf",
"PK_UID": 1
}
],
"HNGS_SWFC": [
{
"BT": "东安古银杏,树龄2500年",
"GSZP": "201911/f0576ca5f5cd4fbea1172915dd7dee9e.png",
"PK_UID": 1
},
{
"BT": "茶亭奇树-惜字塔百年古朴",
"GSZP": "201911/db8d6ad88f2444518cc6516bb65a7e88.jpg",
"PK_UID": 2
},
{
"BT": "黄巢吊马樟",
"GSZP": "201911/db8d6ad88f2444518cc6516bb65a7e89.jpg",
"PK_UID": 3
},
{
"BT": "龙华山下的绿色明珠-双江镇古樟",
"GSZP": "201911/db8d6ad88f2444518cc6516bb65a7e90.jpg",
"PK_UID": 4
},
{
"BT": "中国杉树王",
"GSZP": "201911/db8d6ad88f2444518cc6516bb65a7e92.jpg",
"PK_UID": 5
},
{
"BT": "浏阳千年古樟",
"GSZP": "201911/db8d6ad88f2444518cc6516bb65a7e91.png",
"PK_UID": 6
},
{
"BT": "维新镇千年重阳木",
"GSZP": "201911/db8d6ad88f2444518cc6516bb65a7e93.jpg",
"PK_UID": 7
},
{
"BT": "323",
"GSZP": "202002/a34b609bc3c7437e9a43f1cd1d70ed38.png",
"PK_UID": 16
}
],
"HNGS_SY_GJGSZS_V": [
{
"CODE": "43",
"ZZS": "2476",
"YJZS": "124",
"SJZS": "2114",
"MMZS": "6",
"EJZS": "232"
}
],
"HNGS_XCP": [
{
"JJ": "<p>郴州苏仙区有对千年夫妻银杏古树</p>",
"BT": "郴州苏仙区有对千年夫妻银杏古树",
"FBSJ": 1573488000000,
"SPDZ": "93fafb19-8a41-46de-aec1-330fef136016",
"FBR": "ysw",
"SFZD": "1",
"MZGUID": "29c5debb-631c-4538-8cde-b8ddd7f92a65",
"PK_UID": 51,
"LY": "网络"
},
{
"JJ": "<p>郴州资兴市东江河畔发现罕见楠木古树群</p>",
"BT": "郴州资兴市东江河畔发现罕见楠木古树群",
"FBSJ": 1573488000000,
"MZGUID_PATH": "202001/947919d204d14be1ac165cdb58997647.png",
"SPDZ": "e7908c79-9bf6-4bc6-8fa1-b63d48e501ef",
"FBR": "ysw",
"SPDZ_PATH": "201911/7296c26dc15f42c0af2a39d1aa700705.mp4",
"SFZD": "1",
"MZGUID": "69555d67-dd67-42fc-906c-612d1478ebed",
"PK_UID": 52,
"LY": "网络"
},
{
"JJ": "<p>湖南:平江惊现树龄千年以上红豆杉</p>",
"BT": "湖南:平江惊现树龄千年以上红豆杉",
"FBSJ": 1573488000000,
"MZGUID_PATH": "202001/c793842f23a44dc49e4296b6198fe76d.png",
"SPDZ": "d32b92c2-47ee-4220-b1af-982539d863c4",
"FBR": "ysw",
"SPDZ_PATH": "201911/a95c347f00374bd5872880606c3f9701.mp4",
"SFZD": "1",
"MZGUID": "36d019cc-ea5a-4cf5-af20-f0ca16cd7e81",
"PK_UID": 53,
"LY": "网络"
},
{
"JJ": "<p>湖南永顺千年古树聚焦的原始森林(2014)</p>",
"BT": "湖南永顺千年古树聚焦的原始森林",
"FBSJ": 1573488000000,
"MZGUID_PATH": "202001/d0696765e8d74656b78d2e808359f14d.png",
"SPDZ": "77e23dd2-f189-42ae-875f-a09d419b1d8b",
"FBR": "ysw",
"SPDZ_PATH": "201911/2ebaa1c019554dbe90c1bfbab6f9109a.mp4",
"SFZD": "1",
"MZGUID": "16072c0e-b8ce-4c92-8cac-56592c1d009a",
"PK_UID": 54,
"LY": "网络"
},
{
"JJ": "<p>怀化芷江侗塞发现珍稀古树群</p>",
"BT": "怀化芷江侗塞发现珍稀古树群",
"FBSJ": 1573488000000,
"MZGUID_PATH": "202001/035272c3b3aa4630aaa057d35eb0d0ee.png",
"SPDZ": "61863c28-28e2-4ead-a6f8-0e1dedf599f2",
"FBR": "ysw",
"SPDZ_PATH": "201911/07513323381b432f937915521f6ce40a.mp4",
"SFZD": "1",
"MZGUID": "edee8c4e-0468-43d7-a232-85afd8e3d5f5",
"PK_UID": 55,
"LY": "网络"
},
{
"JJ": "<p>邵阳城步:千年紫薇树需6人合抱</p>",
"BT": "邵阳城步:千年紫薇树需6人合抱",
"FBSJ": 1573488000000,
"MZGUID_PATH": "202001/6caa3c20fbb24d87b6e95aacfa4b298b.png",
"SPDZ": "08aed5a5-d4a6-4629-be53-9be68e093551",
"FBR": "ysw",
"SPDZ_PATH": "201911/70bc1b6325f348548d716c043bd14480.mp4",
"SFZD": "1",
"MZGUID": "114e030c-05a2-4d1c-8c93-c803889caad7",
"PK_UID": 56,
"LY": "网络"
},
{
"JJ": "<p>湘西泸溪发现2000多株古树群落</p>",
"BT": "湘西泸溪发现2000多株古树群落",
"FBSJ": 1573488000000,
"MZGUID_PATH": "202001/abba3eb846e14a86af902d0543005a2d.png",
"SPDZ": "7def7c5c-8e92-4632-a71d-6442f1857c63",
"FBR": "ysw",
"SPDZ_PATH": "201911/952cbabdff9f4fee887f840da4c4a4e3.mp4",
"SFZD": "1",
"MZGUID": "622c258b-e306-4e81-87a7-6920514d9cee",
"PK_UID": 57,
"LY": "网络"
},
{
"JJ": "<p>永州东安白竹村定下永不卖古树村规民约</p>",
"BT": "永州东安白竹村定下永不卖古树村规民约",
"FBSJ": 1573488000000,
"MZGUID_PATH": "202001/45513d65fadb4157ab425b522f1bff0b.png",
"SPDZ": "f697b858-a324-49d7-8e88-275c46b017a0",
"FBR": "ysw",
"SPDZ_PATH": "201911/8d191e27652748e6a54248b837fece91.mp4",
"SFZD": "1",
"MZGUID": "0fa0bdea-05dd-4e80-851d-33298d527c84",
"PK_UID": 58,
"LY": "网络"
}
],
"HNGS_TZGG": [
{
"BT": "通知公告:湖南古树名木移动端APP应用已提测",
"FBSJ": 1572451200000,
"PK_UID": 34
},
{
"BT": "通知公告:湖南古树名木系统运维信息信息发布功能即将发布",
"FBSJ": 1572364800000,
"PK_UID": 33
},
{
"BT": "通知公告:2019年古树名木研究报告会议",
"FBSJ": 1573747200000,
"PK_UID": 54
},
{
"BT": "通知公告:湖南古树名木业务系统进入测试阶段",
"FBSJ": 1572364800000,
"PK_UID": 32
},
{
"BT": "通知公告:建国70周年安全检查与消防演练",
"FBSJ": 1572278400000,
"PK_UID": 31
},
{
"BT": "关于开展全省古树名木资源普查工作的通知 ",
"FBSJ": 1455465600000,
"PK_UID": 52
}
],
"HNGS_ZCFG": [
{
"BT": "政策法规:运维测试记录",
"FBSJ": 1574092800000,
"PK_UID": 55
},
{
"BT": "古树名木普查技术规范(试行)",
"FBSJ": 1573488000000,
"PK_UID": 51
},
{
"BT": "古树名木鉴定标准(试行)",
"FBSJ": 1573488000000,
"PK_UID": 50
},
{
"BT": "中华人民共和国环境保护法",
"FBSJ": 1400860800000,
"PK_UID": 54
},
{
"BT": "中华人民共和国野生植物保护条例",
"FBSJ": 844012800000,
"PK_UID": 53
}
],
"HNGS_KPBK": [
{
"BT": "湖南省关于古树名木申报的通知",
"FBSJ": 1570982400000,
"PK_UID": 2
},
{
"BT": "湖南省关于古树名木申报的通知",
"FBSJ": 1570377600000,
"PK_UID": 3
},
{
"BT": "湖南省关于古树名木申报的通知",
"FBSJ": 1569686400000,
"PK_UID": 1
},
{
"BT": "ssssss",
"FBSJ": 1577376000000,
"PK_UID": 50
}
],
"HNGS_ZTHD": [
{
"BT": "英雄联盟常规赛",
"HDJSSJ": 1577894400000,
"HDKSSJ": 1577030400000,
"NUM": 5,
"PK_UID": 14
},
{
"BT": "\"亲自林\"(小树苗因你的呵护而茁壮成长)",
"HDJSSJ": 1571846400000,
"HDKSSJ": 1570982400000,
"NUM": 5,
"PK_UID": 7
}
]
}请求处理并发化
模块任务拆分
接口并发处理
public Map<String,Object> getIndexData(HttpServletRequest request,HttpServletResponse response){
Map<String, Object> result = new HashMap<String, Object>();
/*String[] tables = new String[]{"HNGS_SWFC","HNGS_SY_GJGSZS_V",
"HNGS_TZGG","HNGS_GZDT","HNGS_ZCFG","HNGS_KPBK","HNGS_GSWH_GSGS",
"HNGS_GSWH_XCQH","HNGS_GSWH_ZXTC","HNGS_XCP","HNGS_ZTHD"};
System.out.println(JSONObject.toJSONString(tables));*/
ExecutorService executorService = Executors.newCachedThreadPool();
// 列举FutureTask任务
FutureTask<Object> lbtTask = new FutureTask<Object>(new LbtTask(indexDataService));
executorService.execute(lbtTask);
FutureTask<Object> gstjTask = new FutureTask<Object>(new GstjTask(indexDataService));
executorService.execute(gstjTask);
FutureTask<Object> commonTaskTZGG = new FutureTask<Object>(new CommonTask("HNGS_TZGG",indexDataService));
executorService.execute(commonTaskTZGG);
FutureTask<Object> commonTaskGZDT = new FutureTask<Object>(new CommonTask("HNGS_GZDT",indexDataService));
executorService.execute(commonTaskGZDT);
FutureTask<Object> commonTaskZCFG = new FutureTask<Object>(new CommonTask("HNGS_ZCFG",indexDataService));
executorService.execute(commonTaskZCFG);
FutureTask<Object> commonTaskBPBK = new FutureTask<Object>(new CommonTask("HNGS_KPBK",indexDataService));
executorService.execute(commonTaskBPBK);
FutureTask<Object> gsgsTask = new FutureTask<Object>(new GsgsTask(indexDataService));
executorService.execute(gsgsTask);
FutureTask<Object> xcqhTask = new FutureTask<Object>(new XcqhTask(indexDataService));
executorService.execute(xcqhTask);
FutureTask<Object> zxtcTask = new FutureTask<Object>(new ZxtcTask(indexDataService));
executorService.execute(zxtcTask);
FutureTask<Object> xcpTask = new FutureTask<Object>(new XcpTask(indexDataService));
executorService.execute(xcpTask);
FutureTask<Object> zthdTask = new FutureTask<Object>(new ZthdTask(indexDataService));
executorService.execute(zthdTask);
try {
result.put("HNGS_SWFC", lbtTask.get());
result.put("HNGS_SY_GJGSZS_V", gstjTask.get());
result.put("HNGS_TZGG", commonTaskTZGG.get());
result.put("HNGS_GZDT", commonTaskGZDT.get());
result.put("HNGS_ZCFG", commonTaskZCFG.get());
result.put("HNGS_KPBK", commonTaskBPBK.get());
result.put("HNGS_GSWH_GSGS", gsgsTask.get());
result.put("HNGS_GSWH_XCQH", xcqhTask.get());
result.put("HNGS_GSWH_ZXTC", zxtcTask.get());
result.put("HNGS_XCP", xcpTask.get());
result.put("HNGS_ZTHD", zthdTask.get());
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ExecutionException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return result;
}注意:FutureTask get()方法是同步方法,这里没有所谓的CountDownLatch控制。 虽然都是等待,但耗时最短可达到单个模块最长的数据处理耗时。
请求处理并发化更优的解决方法
下图参考自:https://blog.csdn.net/u011726984/article/details/79320004
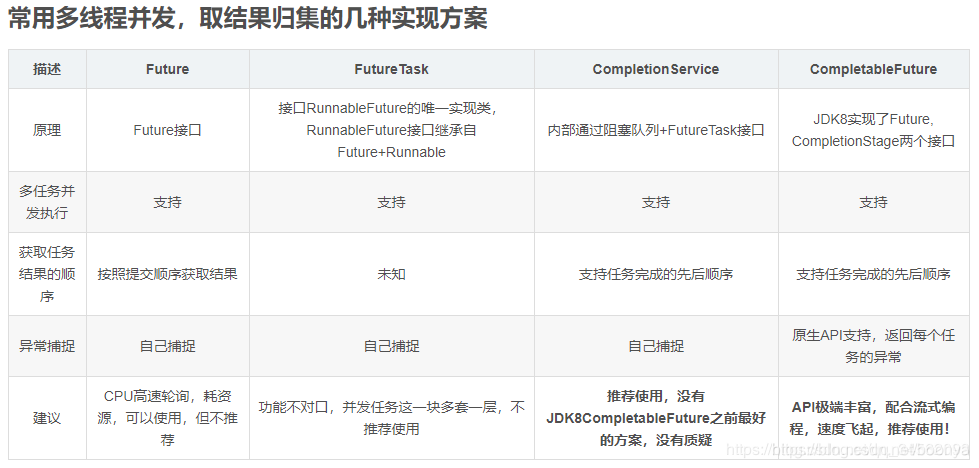
代码改造:CompletableFuture和CompletionService。
/**
* 首页数合并请求处理
* @param request
* @param response
* @return
*/
@SuppressWarnings("unchecked")
@RequestMapping({ "/getIndexData.web" })
@ResponseBody
public Map<String,Object> getIndexData(HttpServletRequest request,HttpServletResponse response){
Map<String, Object> result = new HashMap<String, Object>();
/*String[] tables = new String[]{"HNGS_SWFC","HNGS_SY_GJGSZS_V",
"HNGS_TZGG","HNGS_GZDT","HNGS_ZCFG","HNGS_KPBK","HNGS_GSWH_GSGS",
"HNGS_GSWH_XCQH","HNGS_GSWH_ZXTC","HNGS_XCP","HNGS_ZTHD"};
System.out.println(JSONObject.toJSONString(tables));*/
// 是否使用JDK1.8特性
if(ConfigUtil.THREAD_WORKER_USE_JDK8){
// 解决线程先后执行完成顺序问题,线程池是一个重量级的资源分配操作,不宜频繁初始化
//CompletionService<Object> completionService=new ExecutorCompletionService<Object>(executorService);
// 列举CompletableFuture任务
CompletableFuture<Object> lbtTask = CompletableFuture.supplyAsync(new LbtTask(indexDataService), executorService);
CompletableFuture<Object> gstjTask = CompletableFuture.supplyAsync(new GstjTask(indexDataService), executorService);
CompletableFuture<Object> commonTaskTZGG = CompletableFuture.supplyAsync(new CommonTask("HNGS_TZGG",indexDataService), executorService);
CompletableFuture<Object> commonTaskGZDT = CompletableFuture.supplyAsync(new CommonTask("HNGS_GZDT",indexDataService), executorService);
CompletableFuture<Object> commonTaskZCFG = CompletableFuture.supplyAsync(new CommonTask("HNGS_ZCFG",indexDataService), executorService);
CompletableFuture<Object> commonTaskBPBK = CompletableFuture.supplyAsync(new CommonTask("HNGS_KPBK",indexDataService), executorService);
CompletableFuture<Object> gsgsTask = CompletableFuture.supplyAsync(new GsgsTask(indexDataService), executorService);
CompletableFuture<Object> xcqhTask = CompletableFuture.supplyAsync(new XcqhTask(indexDataService), executorService);
CompletableFuture<Object> zxtcTask = CompletableFuture.supplyAsync(new ZxtcTask(indexDataService), executorService);
CompletableFuture<Object> xcpTask = CompletableFuture.supplyAsync(new XcpTask(indexDataService), executorService);
CompletableFuture<Object> zthdTask = CompletableFuture.supplyAsync(new ZthdTask(indexDataService), executorService);
try {
result.put("HNGS_SWFC", lbtTask.get());
result.put("HNGS_SY_GJGSZS_V", gstjTask.get());
result.put("HNGS_TZGG", commonTaskTZGG.get());
result.put("HNGS_GZDT", commonTaskGZDT.get());
result.put("HNGS_ZCFG", commonTaskZCFG.get());
result.put("HNGS_KPBK", commonTaskBPBK.get());
result.put("HNGS_GSWH_GSGS", gsgsTask.get());
result.put("HNGS_GSWH_XCQH", xcqhTask.get());
result.put("HNGS_GSWH_ZXTC", zxtcTask.get());
result.put("HNGS_XCP", xcpTask.get());
result.put("HNGS_ZTHD", zthdTask.get());
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ExecutionException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return result;
}else{
// 解决线程先后执行完成顺序问题,线程池是一个重量级的资源分配操作,不宜频繁初始化
CompletionService<Object> completionService=new ExecutorCompletionService<Object>(executorService);
// 列举FutureTask任务
Future<Object> lbtTask = completionService.submit(new LbtTask(indexDataService));
Future<Object> gstjTask = completionService.submit(new GstjTask(indexDataService));
Future<Object> commonTaskTZGG = completionService.submit(new CommonTask("HNGS_TZGG",indexDataService));
Future<Object> commonTaskGZDT = completionService.submit(new CommonTask("HNGS_GZDT",indexDataService));
Future<Object> commonTaskZCFG = completionService.submit(new CommonTask("HNGS_ZCFG",indexDataService));
Future<Object> commonTaskBPBK = completionService.submit(new CommonTask("HNGS_KPBK",indexDataService));
Future<Object> gsgsTask = completionService.submit(new GsgsTask(indexDataService));
Future<Object> xcqhTask = completionService.submit(new XcqhTask(indexDataService));
Future<Object> zxtcTask = completionService.submit(new ZxtcTask(indexDataService));
Future<Object> xcpTask = completionService.submit(new XcpTask(indexDataService));
Future<Object> zthdTask = completionService.submit(new ZthdTask(indexDataService));
try {
result.put("HNGS_SWFC", lbtTask.get());
result.put("HNGS_SY_GJGSZS_V", gstjTask.get());
result.put("HNGS_TZGG", commonTaskTZGG.get());
result.put("HNGS_GZDT", commonTaskGZDT.get());
result.put("HNGS_ZCFG", commonTaskZCFG.get());
result.put("HNGS_KPBK", commonTaskBPBK.get());
result.put("HNGS_GSWH_GSGS", gsgsTask.get());
result.put("HNGS_GSWH_XCQH", xcqhTask.get());
result.put("HNGS_GSWH_ZXTC", zxtcTask.get());
result.put("HNGS_XCP", xcpTask.get());
result.put("HNGS_ZTHD", zthdTask.get());
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ExecutionException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return result;
}
}
前端渲染异步化
/**
* 初始化表单
*/
function init() {
/**
* 异步Ajax请求
*/
$.ajax({
url : 'data/getIndexData.web',
data : {},
type : 'post',
cache : true,
async:true,
dataType : 'json',
success : function(data) {
queryCallback(data);
},
error : function(evt) {
mini.alert("请求失败,请重试!");
}
});
}
/**
* 页面数据查询回调函数
*/
function queryCallback(data){
//轮播图
lbtData(data.HNGS_SWFC);
//古树统计
gstjData(data.HNGS_SY_GJGSZS_V);
//通知公告
index_common_data("HNGS_TZGG",".tzgg-c ul",data.HNGS_TZGG);
//延迟加载
setTimeout(function (){
index_common_data("HNGS_GZDT",".zxkd-c ul",data.HNGS_GZDT);
index_common_data("HNGS_ZCFG",".zcfg-c ul",data.HNGS_ZCFG);
index_common_data("HNGS_KPBK",".kpbk-c ul",data.HNGS_KPBK);
},3000);
//延迟加载
setTimeout(function(){
//乡愁情怀
xcqhData(data.HNGS_GSWH_XCQH);
//在线图册
zxtcData(data.HNGS_GSWH_ZXTC);
//专题活动
zthdData(data.HNGS_ZTHD);
//index_dbsx();
//szjd();
//古树故事
gsgsData(data.HNGS_GSWH_GSGS);
//宣传片
xcpData(data.HNGS_XCP);
},1000);
}测试效率
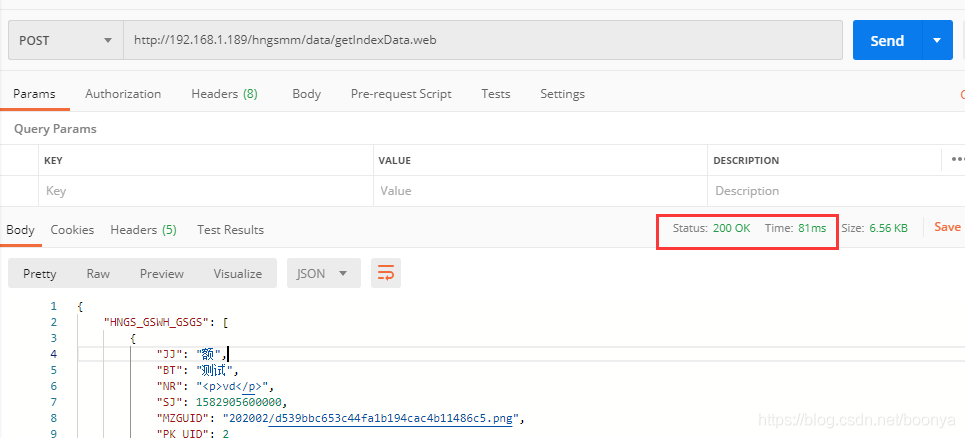
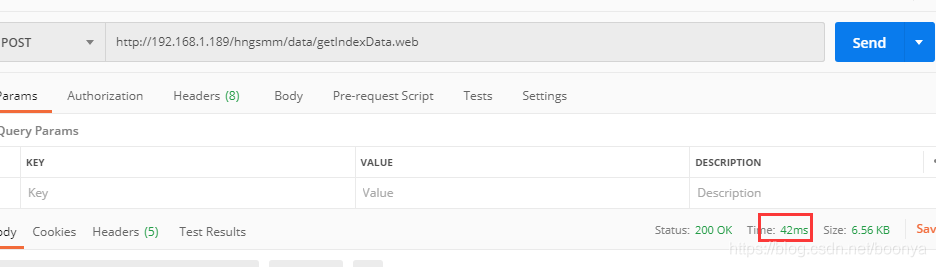














 651
651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









