







 本文详细介绍了 SVN 中 branch、trunk 和 tag 的概念及使用方法,强调了 branch 在不干扰 trunk 开发中的作用,通过实例演示了创建分支、同步更新、合并回主线的完整流程,帮助读者理解版本控制中的分支管理策略。
本文详细介绍了 SVN 中 branch、trunk 和 tag 的概念及使用方法,强调了 branch 在不干扰 trunk 开发中的作用,通过实例演示了创建分支、同步更新、合并回主线的完整流程,帮助读者理解版本控制中的分支管理策略。
对于branch truck tag一直迷迷糊糊的,想搞明白,但是一直又没来弄明白,最近就用了这种方式来开发 可以我又不是完全了解怎么操作,所以查看了下资料,这个解释得很详细呀,连我都看得懂的东西,真所谓“写得真好”,记录下,转载http://blog.csdn.net/keda8997110/article/details/21813035
先说说什么是branch。按照Subversion的说法,一个branch是某个development line(通常是主线也即trunk)的一个拷贝,见下图:
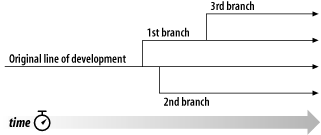
branch存在的意义在于,在不干扰trunk的情况下,和trunk并行开发,待开发结束后合并回trunk中,在branch和trunk各自开发的过程中,他们都可以不断地提交自己的修改,从而使得每次修改在repository中都有记录。
设想以下场景,如果你的项目需要开发一个新功能,而该功能可能会修改项目中的绝大多数文件,而与此同时,你的另一位同事正在进行bug fix,如果你的新功能不在branch中开发而直接在trunk中开发,那么你极有可能影响另一位同事的bug fix,他/她在bug修复中可能会遇到各种各样的问题,因为你的频繁提交代码引入了过多的不稳定因素。你可能会说,那我在开发的过程中不提交不就行了,等到我全部开发结束我再提交,是,你可以这么做,那还要版本控制干什么呢?也许等到你最后提交代码的时候(也许一周,也许两周?),你会发现有一大堆conflict等着你resolve。。。
那么,正确的做法是什么?使用branch,从trunk创建branch,然后在你的branch上开发,开发完成后再合并到trunk中。
关于branch先讲到这里,下面说说什么叫做合并。很好理解,当branch开发完成后(包括必要的测试),将branch中的修改同步到trunk中,这个过程有可能包括修改文件、增加文件、删除文件等等。
说到这里,貌似本文差不多可以结束了,不就是分支和合并么?只要再简单地说说如何建立分支和如何合并就可以收尾了,可能只需两个命令,也可能只需鼠标点几下然后键盘敲两下即可。其实事情远非这么简单,爱动脑筋的同学可能会问了,将branch的改动merge到trunk的时候,和上文说的直接在trunk中全部开发完然后提交有何区别?你最后还不是要处理一大堆conflict?
这个问题问得非常好,其实这正是本文的重点:branch和trunk在并行开发的过程中如何感知对方,branch如何才能在开发过程中不会和trunk越走越远,导致最后无法合并?试想一下,如果在你开发branch的过程中,trunk中的某个类文件已经被删除了(这可能是另外一个家伙在另一个branch上开发了两周后才合并到trunk的),而你竟然在这个类文件上做了大量修改,试问你到最后合并回trunk的时候该有多蛋疼?解决这一问题的唯一手段是,branch要不停地和trunk保持同步,你要及时地知道trunk都做了什么修改,这些修改是否会影响你正在开发的新功能,如果需要,你必须及时调整branch的代码,使之能与trunk“兼容”。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2376
2376

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









