







HBase上RegionServer的cache主要分为两个部分,分别是memstore&blockcache,其中memstore主要用于写缓存,而blockcache用于读缓存。
当数据写入hbase时,会先写入memstore,RegionServer会给每个region提供一个memstore,memstore中的数据达到系统设置的水位值后,会触发flush将memstore中的数据刷写到磁盘。
客户的读请求会先到memstore中查数据,若查不到就到blockcache中查,再查不到就会从磁盘上读,并把读入的数据同时放入blockcahce。我们知道缓存有三种不同的更新策略,分别是先入先出(FIFO)、LRU(最近最少使用)和LFU(最近最不常使用),hbase的block使用的是LRU策略,当BlockCache的大小达到上限后,会触发缓存淘汰机制,将最老的一批数据淘汰掉。
一个RegionServer上有一个BlockCache和N个Memstore。下面我们从hbase的源码中展开阐述Blockcache的具体实现,并在讲解实现的中间补充阐述关于缓存的相关机制介绍。
BlockCache在HBase中所处的位置如下图中所示:
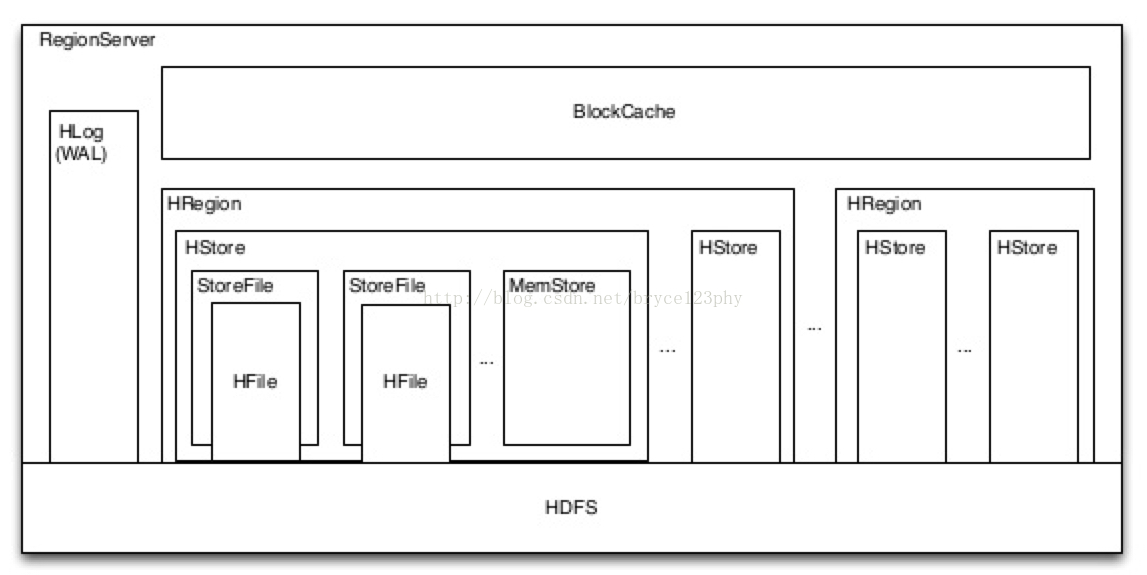
BlockCache的实现是基于On-heap ConcurrentHashMap。map的key是BlockCacheKey类型的对象,包括了offset、hfileName等成员变量,map的value是LruCachedBlock类型的对象,表示缓存的实体,该对象中定义了成员变量accesstime,用于LRU淘汰时的比较依据。BlockCache的大小是固定的,由参数hfile.block.cache.size决定,默认是RegionServer的堆内存的40%。
BlockCache的初始化在HRegionServer的handleReportForDutyResponse里完成,HRegionServer有一个HeapMemoryManager类型的成员变量,用于管理RegionServer进程的堆内存,HeapMemoryManager中的blockCache就是RegionServer中的读缓存,它的初始化在CacheConfig的instantiateBlockCache方法中完成,剪掉一些判断BlockCache是否禁用的代码,我们列出其中的主要逻辑如下:
public static synchronized BlockCache instantiateBlockCache(Configuration conf) {
MemoryUsage mu = ManagementFactory.getMemoryMXBean().getHeapMemoryUsage();
LruBlockCache l1 = getL1(conf, mu);
BlockCache l2 = getL2(conf, mu);
if (l2 == null) {
GLOBAL_BLOCK_CACHE_INSTANCE = l1;
} else {
boolean useExternal = conf.getBoolean(EXTERNAL_BLOCKCACHE_KEY, EXTERNAL_BLOCKCACHE_DEFAULT);
boolean combinedWithLru = conf.getBoolean(BUCKET_CACHE_COMBINED_KEY,
DEFAULT_BUCKET_CACH 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2191
2191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









