



今天,PPIO 上线 KAT-Dev-32B,这是由快手推出的全新开源代码模型。
在 SWE-Bench Verified 测试中, KAT-Dev-32B 解决率达到 62.4%, 在所有不同规模的开源模型中排名第五。
该模型支持 128K 上下文,价格为每百万输入 tokens 1 元、每百万输出 tokens 3 元。
现在,前往 PPIO 官网或点击文末阅读原文即可体验 KAT-Dev-32B 。新用户填写邀请码【LUUV7S】注册可得 15 元代金券。
快速入口:
https://ppio.com/llm/kwaipilot-kat-dev
开发者文档:
https://ppio.com/docs/model/overview

# 01 模型创新点
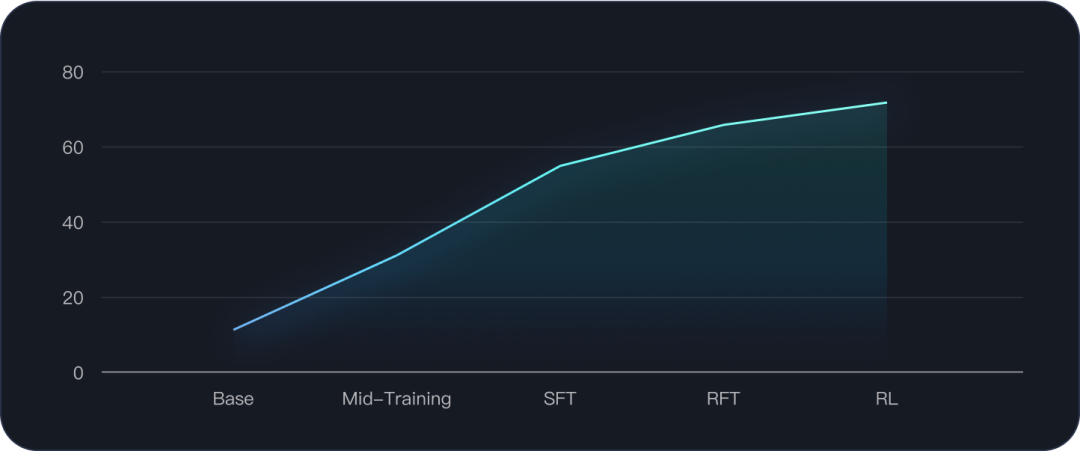
KAT-Dev-32B 通过多个阶段的训练进行优化,包括中期训练阶段(Mid-Training)、监督微调(SFT)和强化微调(RFT)阶段以及大规模代理强化学习(Agentic RL Scaling)阶段。
中期训练:在当前阶段(例如在SWE-bench等排行榜上)增加工具使用能力、多轮交互和指令遵循的广泛训练可能不会带来显著的性能提升。但由于实验基于 Qwen3-32B 模型,团队发现增强这些基础能力将对后续的SFT和RL阶段产生重要影响。这表明提升此类核心能力能够深刻影响模型处理更复杂任务的能力。
SFT & RFT:精心设计了八种任务类型和八种编程场景,以确保模型的泛化能力和综合性能。此外,在RL 阶段之前,创新性地引入了RFT阶段。与传统RL相比,在训练中融入了由工程师标注的"教师轨迹"作为指导——正如新手驾驶员在正式上路前需要教练陪同练习。这一步骤不仅提升了模型性能,还进一步稳定了后续的RL训练。

Agentic RL 扩展:扩展智能强化学习主要面临三大挑战:在非线性轨迹历史上实现高效学习、利用模型内在信号,以及构建可扩展的高吞吐量基础设施。通过 RL 训练引擎中的多级前缀缓存机制、基于熵的轨迹剪枝技术,以及内部实现的 SeamlessFlow 架构来解决这些挑战——该架构在充分利用异构计算资源的同时,实现了智能体与训练的清晰解耦。这些创新共同降低了扩展成本,实现了高效的大规模强化学习。
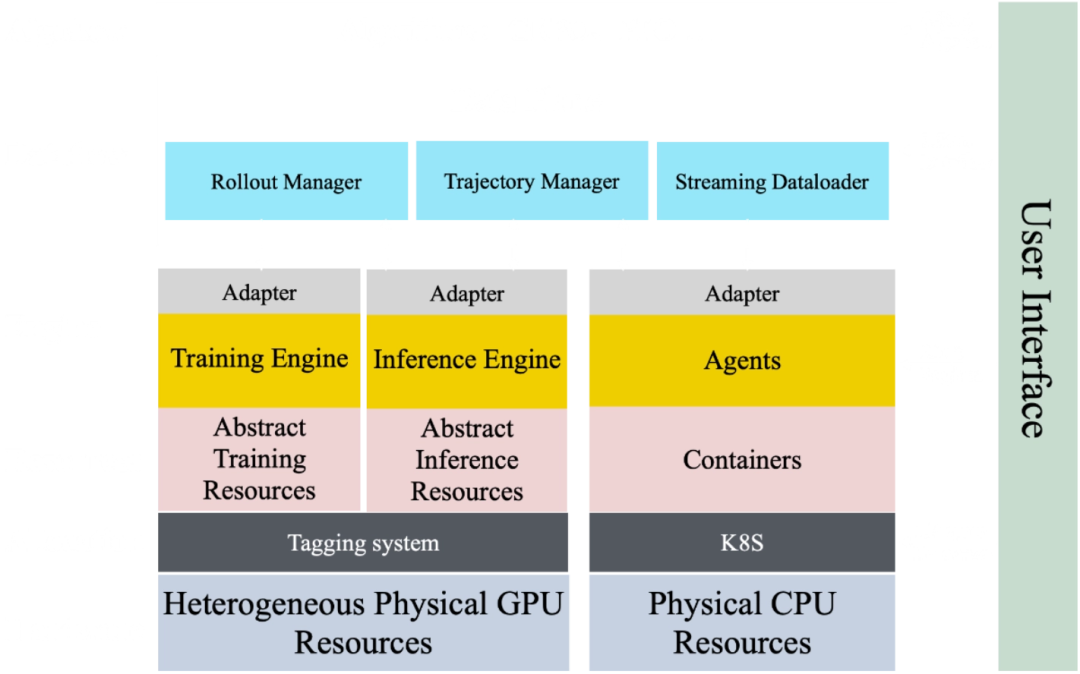
以下是模型在 SWE-Bench Verified 的性能变化:
02 在线体验KAT-Dev-32B
KAT-Dev-32B 的具体表现如何?
提示词:
你是前端工程师。请用单文件写一个反应力测试网页(仅用原生 HTML/CSS/JS,不引第三方库,不联网)。规则:
1、初始显示“点击开始”;点击后进入等待状态,随机 800–2000ms 后背景变绿;
2、变绿后用户点击,显示这次反应时间(ms);重复 3 次,显示平均值;
3、设计要美观:居中卡片、柔和配色、微动效(过渡/阴影/按钮态);
4、适配手机(375px)和桌面(1440px);
5、交互有防误触:变绿前点击判为“太早了”;
6、代码整洁,≤200 行(不含空行),含少量注释。
直接给出完整单文件 HTML。
生成效果:

代理重构任务:
你可以到 PPIO 官网在线体验 KAT-Dev-32B ,或者将模型 API 接入 Cherry Studio、ChatBox 或者你自己的 AI 工作流中。
查看详细接入教程:
https://ppio.com/docs/model/overview

KAT-Dev-32B 通过可扩展的 Agentic RL推进代码智能。因此,最后送一份福利:PPIO 整理了 20 余篇 Agent 相关的报告资料,可扫下图二维码下载,以及加入社群交流。



















 492
492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









