






 本文详细介绍Celery异步任务队列的使用方法,包括环境搭建、任务调度、结果存储及与Flask框架的整合技巧。
本文详细介绍Celery异步任务队列的使用方法,包括环境搭建、任务调度、结果存储及与Flask框架的整合技巧。
由于公司业务,需要配合flask框架执行异步任务,于是想到了异步任务神器-Celery,发现非常好用,也遇到许多坑,在此记录下celery使用以及使用过程中遇到的坑。
Celery 简介
它是一个异步任务调度工具,用户使用 Celery 产生任务,借用中间人来传递任务,任务执行单元从中间人那里消费任务。任务执行单元可以单机部署,也可以分布式部署,因此 Celery 是一个高可用的生产者消费者模型的异步任务队列。你可以将你的任务交给 Celery 处理,也可以让 Celery 自动按 crontab 那样去自动调度任务,然后去做其他事情,你可以随时查看任务执行的状态,也可以让 Celery 执行完成后自动把执行结果告诉你。
Celery 的架构
学习一个工具,最好先从它的架构理解,辅以快速入门的代码来实践,最深入的就是阅读他的源码了,下图是 Celery 的架构图。
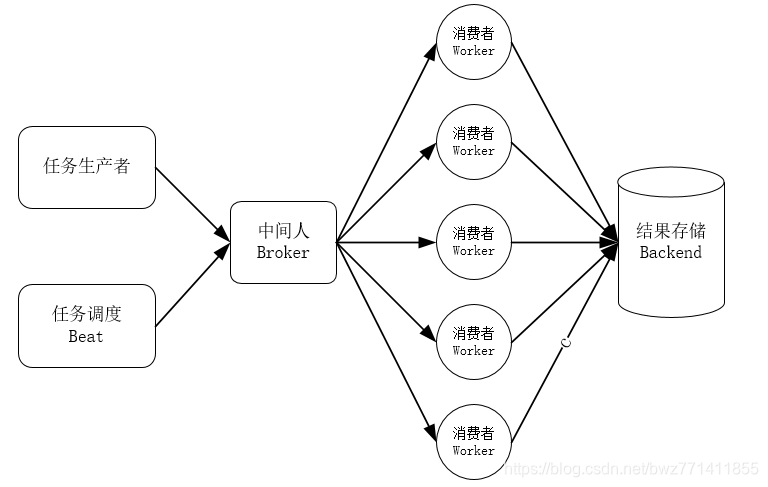
任务生产者: 调用Celery提供的API,函数,装饰器而产生任务并交给任务队列的都是任务生产者。
任务调度Beat: Celery Beat进程会读取配置文件的内容,周期性的将配置中到期需要执行的任务发送给任务队列
中间人(Broker): Celery 用消息通信,通常使用中间人(Broker)在客户端和 worker 之前传递,这个过程从客户端向队列添加消息开始,之后中间人把消息派送给 worker。在实际使用中通常我们选择 RabbitMQ 或 Redis 作为中间。
执行单元worker: worker 是任务执行单元,是属于任务队列的消费者,它持续地监控任务队列,当队列中有新地任务时,它便取出来执行。worker 可以运行在不同的机器上,只要它指向同一个中间人即可,worker还可以监控一个或多个任务队列, Celery 是分布式任务队列的重要原因就在于 worker 可以分布在多台主机中运行。修改配置文件后不需要重启 worker,它会自动生效。
任务存储backend: 用来持久存储 Worker 执行任务的结果,Celery支持不同的方式存储任务的结果,包括AMQP,Redis,memcached,MongoDb,SQLAlchemy等。
Celery 的使用示例:
这里以python3.6.7为示例
1. 环境准备
1.1 安装 python 库:celery,flask
pip install celery==4.47
pip install flask
注:
celery 5.0.0版本不支持-Q参数指定队列
1.2 安装 Redis
安装redis有2种方式,一种通过源码安装(即压缩包),一种通过pip安装,第二种方式可能会麻烦点,pip安装使用的默认配置文件(没找到在哪里),如果因为业务需要修改配置,就需要通过命令行修改。
方式一:
通过源码安装:
$ wget http://download.redis.io/releases/redis-4.0.11.tar.gz
$ tar xzf redis-4.0.11.tar.gz
$ cd redis-4.0.11
$ make && make install
修改 redis 配置文件 redis.conf,修改bind = 127.0.0.0.1为bind = 0.0.0.0,意思是允许远程访问redis数据库。
方式二:
通过pip安装
pip install redis(客户端)
pip install redis-server(服务端)
启动 redis-server:
启动方式都是一样的,运行redis-server可执行文件即可,如果要指定某些配置,在启动文件后加上文件路径参数
./redis-server …/redis.conf
2. 第一个 celery 应用程序
2.1 编写celery配置文件
先建立一个目录,比如我这里是/root/yzc/celery1,然后新建一个celery配置文件,可随意命名,比如celeryconfig.py,内容如下:
#!/usr/bin/python
BROKER_URL = ‘redis://127.0.0.1:6379/0’
这里只定义了broker的存储位置,指定redis的0号库作为存储地址。
2.2 定义celery和tasks
新建一个tasks.py,内容如下:
from celery import Celery
celery_app = Celery(‘tasks’)
celery_app.config_from_object(“celeryconfig”)
@celery_app.task
def add(x, y):
return x + y
使用celery的第一步是定义一个Celery实例,也叫做Celery app,它是使用Celery的入口,比如tasks、管理workers都是通过Celery实例完成。
定义Celery对象的第一个参数是当前模块的名称,然后使用config_from_object方法导入配置。接下来在celery实例app上注册了一个任务(task),叫做add,计算两个数的和。
额外话题: 在定义任务的时候,使用了@celery_app.task符号,这个是python中的装饰器,在不改变add函数的情况下,为它增加了新的功能,相当于下面的语句:
def add(x, y):
return x + y
add = celery_app.task(add)
先定义了函数add,然后作为参数传递给装饰器,得到一个新的对象,这个新的add不仅具有原来的计算两数之和的功能,还增加了一些新的功能,比如后面用到的delay方法。
2.3 启动celery职程服务(worker)
在celery1目录下的命令行执行命令 celery -A tasks worker -l info 启动worker;
-A参数表示的是celery app的名称,这里为tasks,-l表示日志等级。这条命令表示启动了一个worker来执行程序中的add任务。
执行结果如下:
pass
在[config]中我们可以看到当前app名称tasks,transport就是我们在程序中设置的broker,result(就是backend)没有设置,暂时显示为disabled,然后我们可以看到worker缺省使用perfork来执行并发,当前并发数显示为32,下面的[queue]就是任务队列,默认队列是celery,再下面的[tasks]中有一个任务tasks.add,表示注册到celery实例的任务。日志最后一行表示celery在这台主机已经ready了,可以接收任务了。
注意事项:
关于worker职程启动的问题,如果tasks中定义了celery app那么就在tasks文件所在目录启动;
如果tasks中没有定义celery,而是从其他文件导入过来,那么就要在定义celery app的文件上一级目录执行worker启动,-A参数后面接路径(假设celery1目录下有个__init__.py文件,里面定义了celery_app,那么就要在celey1上级目录/root下启动celery -A celery1.tasks worker - l info).否则会会报错The module celery1 was not found。
2.4 下发任务
新开一个terminal,输入python进入交互模式,输入:
pass
先从tasks.py中导入add任务对象,然后使用delay()方法将任务发送到消息中间件,我们之前开启的worker会一直监控任务队列,发现有任务到来,就会执行。这里可以看到输入的任务已经由之前启动的worker服务异步执行了,回到启动worker的终端查看结果如下:
pass
日志显示worker接收到一个任务:tasks.add,并且执行成功了。
2.5 保存任务执行结果
在上面的例子中,worker执行完任务后并没有存储结果,而我们在前端下发完任务后,由于是异步任务,所以我们并不知道任务执行的结果,所以要把任务结果保存起来,然后前端通过接口去获取结果。
首先在celeryconfig中添加一行:
CELERY_RESULT_BACKEND = “redis://127.0.0.1:6379/1”
意思是将结果保存在redis的1号库,重新启动worker职程,可以看到[config]中有了result的信息:
pass
在另一个终端调用一个任务,返回一个AsyncResult对象,可以通过这个对象的ready方法查询任务执行状态,get方法查询结果:
pass
2.6 将任务发往指定队列
在启动worker职程时,可以通过-Q参数指定该worker处理哪一个或者几个队列的任务,在下发任务时也可以指定将任务下发到哪个队列中;
pass
通过上述示例可以看出,第一个任务下发到add_que队列,执行成功;第二个任务不指定队列,默认会下发到celery这个队列(celery定义的默认队列),由于没有启动worker处理默认队列的任务,所以任务处于pending状态。
2.7 worker后台执行
以上的示例worker均为前台运行,实际应用中我们通常希望worker后台运行,这里介绍两种方式:
- 第一种是在上面的启动命令最前面加上nohup,并且最后加上&号,如果多个worker,则执行多条命令。
- 第二种是使用celery mulit命令,这个命令可以同时在后台启动多个worker。
例如启动10个worker,1-3处理add_que队列任务,4-5处理multi_que队列任务,其他处理默认队列任务:
celery multi start 10 tasks -Q:1-3 add_que -Q:4-5 multi_que -Q default -l info —pid=‘%n.pid —logfile=%n.log
这里的—pid和–logfile不写会有默认的地址- 如果要某一个worker执行定时任务,不建议使用celery multi命令启动多个worker,因为命令中的-B参数(同时启动celery beat调度定时任务)会影响所有的worker,比如你有3个worker并且在希望第三个worker执行定时任务,那么你会发现第三个worker的日志中,一时间周期内会有3次任务执行结果,在后面的定时任务中会讲到。
2.8 多任务配置(多worker)
注意事项:
通过-Q参数指定了worker处理哪个队列任务,但是如果后面接的不是celery,则处理的为指定队列而不是默认队列,如下:
celery -A tasks worker -Q default -l info:处理队列名为default的任务;需要在celery_queues和celery_routes都指明对应规则。
celery -A tasks worker -Q celery -l info:处理默认队列的任务;启动时直接指定-Q celery在配置文件中celery_queues添加一条规则即可。
2.9 定时任务
pass
3. 第一个celery项目
功能:启动一个flask服务,通过接口下发任务,下发成功返回任务唯一标示task id,用户可以通过任务id查询任务当前状态或执行结果。
pass
4. 在项目应用中遇到的坑
4.1 celery实例不能访问到flask的应用上下文
由于celery服务相对flask服务是离线的(相互隔离),所以如果在celery服务中使用了flask的某些东西(比如在celery中使用flask的current_app记录日志),会下面这个错:
pass
解决:出现这个错的原因就是他们相互隔离,没有导入访问不了对方的东西,所以在创建celery app的时候可以将flask app的应用上下文导入,代码如下所示:
from flask import Flask
from celery import Celery
app = Flask(__name__)
def make_celery(app):
celery_app = Celery(app.name, include=['celery_tasks.tasks'])
celery_app.config_from_object('celery_tasks.settings')
class ContextTask(celery_app.Task):
def __call__(self, *args, **kwargs):
with app.app_context():
return self.run(*args, **kwargs)
celery_app.Task = ContextTask
return celery_app
celery_app = make_celery(app)
注意事项:
很多博文在ContextTask类中重写父类call方法,在实际表现下发现不能解决这个bug,所以直接返回self.run。
4.2 已经设置了backend,查询任务结果时提示未设置backend
在settings中明明配置了backend的地址,但是获取任务执行结果时报错:
pass
解决:在上面的flask服务中,下发任务(delay方法)和获取任务结果(AsyncResult方式)在两个接口内[如果在同一个接口,可以使用下发任务后返回的对象,调用status获取任务状态],所以调用AsyncResult方式时需要传入celery app才能过去到相应结果,代码如下:
res = celery_app.AsyncResult(task_id).result
4.3 celery任务中使用了多进程mulitprocess
在示例中,celery执行的异步任务中用到了多进程,报错:
pass
解决:只需要在启动脚本中或者在服务运行的当前终端导入下面这个环境变量即可;
export PYTHONOPTIMIZE=1
4.4 celery和flask命令行参数不同的问题
在业务中,我们通常通过启动命令来判断是生产还是测试环境(访问不同的数据库),这里就会用到sys.argv,正如上面说的,flask和celery的sys.argv的值等于自己的启动命令,两者必然是不同的,程序不一定报错,但是结果和你预期肯定不符:
pass
解决:在flask中调用方法下发异步任务时,将flask的sys.argv作为参数传递给celery任务使用即可。
say.argv示例:
celery:[‘/usr/bin/celery’, ‘-A’, ‘celery_tasks.tasks’, ‘-Q’, ‘add_que’, ‘work’, ‘-l’, ‘info’]
flask:[‘/root/flask_celery/manage.py’, ‘sit’]
4.5 在flask中装饰器(统计接口耗时)需要有返回值
在flask服务中使用装饰器计算接口响应耗时,报错了:
pass
解决:在装饰器内层函数加上装饰@wraps.(func),在不加的情况下,index.__name__输出内层函数inner,添加后输出index本身,代码如下:
from functools import wraps
def timer(func):
@wraps(func)
def inner(*args, **kwargs):
t1 = time.time()
res = func(*args, **kwargs)
t2 = time.time()
current_app.logger.info('Exec func({}) cost time: {:.2f}s'.format(func, (t2 - t1)))
return res
return inner
@app.route('/')
@timer
def index():
currrent_app.logger('-' * 99)
return str(sys.argv[1])
print(index.__name__)
4.6 celery任务中抛出异常
任何程序都需要对异常情况进行处理,celery也不例外,在celery任务执行出行异常时,不处理程序不至于崩溃,但是对用户很不友好,比如用户给了一个异常参数,程序返回错误500:
pass
解决:只需要在celery配置中增加选项
CELERY_ACCEPT_CONTENT = [‘json’],然后在flask程序中进行判断就行了。处理代码如下:
# 获取结果
res = celery_app.AsyncResult(task_id).result
# 更新状态
if not isinstance(res, int):
return jsonify({'RESULT': 'FAILED', 'MSG': 'An exception is captured, more detail to check celery log!'})
注意事项:
由于这里的程序是做简单的加法和乘法,所以判断的结果celery异步任务返回的结果是否为int类型,一般正常返回时dict,需要的话修改即可。
4.7 多任务配置
5. 总结
总的来说,可以把flask服务和celery服务看成完全隔离的两个进程,相互之间并不知道对方在干什么,自己拥有的上下文,变量对方也一无所知,所以需要通过传参或者重写来达到两者间某些东西的共享。
关于celery和flask的执行流程,大体总结为以下几步:
- 优先启动redis(worker中配置了broker和backend存储在其中);
- 配置好celery app的各个选项,启动worker职程(告诉worker是否在后台运行,各个worker对应的处理哪个队列的任务);
- 在flask中调用接口下发任务,该接口对应的是配置项中指定的某个队列,这个队列的任务发给指定的worker;并将接口提供给用户使用。

















 2003
2003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









