






Datawhale X 李宏毅苹果书 AI夏令营–深度学习入门 Task2
线性模型
这些模型都是把输入的特征 x 乘上一个权重,再加上一个偏置就得到预测的结果,这样的模型称为线性模型
通常一个模型的修改,往往来自于对这个问题的理解,即领域知识
-
如数据按七天一循环,可设
y = b + ∑ j = 1 7 w j x j y = b +\sum^7_{j=1}{w_jx_j} y=b+j=1∑7wjxj- 通过梯度下降算法得到的一组w:0.79 -0.31 0.12 -0.01 -0.10 0.30 0.18
- b为偏置,w为权重,相较之前只考虑一天的模型,该模型考虑了七天,所得损失更小
- 机器的逻辑是前一天跟要预测的隔天的数值的关系很大,所以w1是0.79,部分天数与其成反比,权值设为负值
- 再尝试考虑28天,结果所得损失与考虑八天相同,说明在该案例中,考虑更多天没有办法再更降低损失
分段线性曲线
线性模型有很大的限制,这一种来自于模型的限制称为模型的偏差,无法模拟真实的情况
-
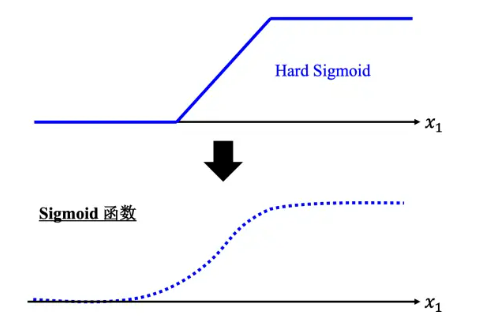
Hard Sigmoid 函数的特性是当输入 x 的值小于某一个阈值的时候,大于另外一个定值阈值的时候,中间有一个斜坡。所以它是先水平的,再斜坡,再水平的
-
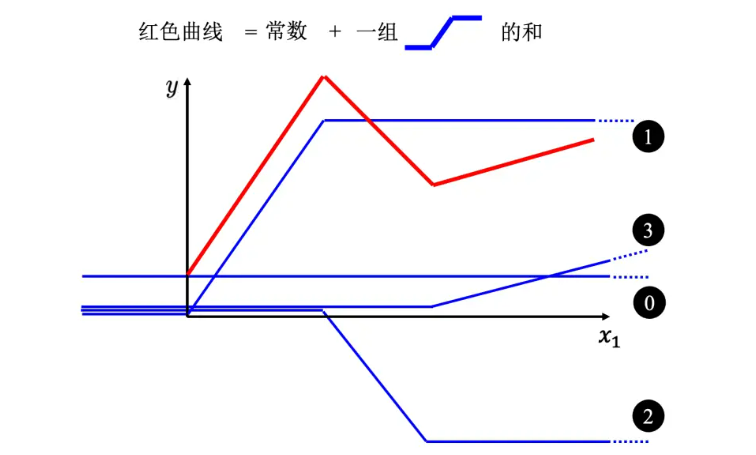
对于非分段线性曲线,可以用分段线性曲线逐渐逼近,故只要有足够的蓝色函数把它加起来,就可以变成任何连续的曲线
-
用 Sigmoid 函数来逼近 Hard Sigmoid
y = c 1 1 + e − ( b + w x 1 ) y = c{\frac{1}{1 + e^{−(b+wx_1)}}} y=c1+e−(b+wx1)1- 简洁形式为
y = c σ ( b + w x 1 ) y = cσ(b + wx_1) y=cσ(b+wx1)
- 如果改 w,就会改变斜率,就会改变斜坡的坡度;如果改了 b,就可以把这一个 Sigmoid 函数左右移动;如果改 c,就可以改变它的高度
- 所以只要有不同的 w、b、c,就可以制造出不同的 Sigmoid 函数,把不同的Sigmoid 函数叠起来以后就可以去逼近各种不同的分段线性函数,分段线性函数可以拿来近似各种不同的连续的函数,分段线性函数可表示为
y = b + ∑ i c i σ ( b i + w i x 1 ) y = b +\sum_i{c_iσ(b_i + w_ix_1)} y=b+i∑ciσ(bi+wix1)
-
此外,我们可以不只用一个特征 x1,可以用多个特征代入不同的 c, b, w,组合出各种不同的函数,从而得到更有灵活性的函数,如x1~x7
-
对第一个sigmoid函数:
r 1 = b 1 + w 11 x 1 + w 12 x 2 + w 13 x 3 r_1=b_1 + w_{11}x_1 + w_{12}x_2 + w_{13}x_3 r1=b1+w11x1+w12x2+w13x3 -
用矩阵形式(分别对每一个ri进行σ运算)
r = b + W x r = b + W x r=b+Wxa = σ ( r ) a = σ(r) a=σ(r)
y = b + c T a y = b + c^Ta y=b+cTa
-
故

-
未知参数有W、b、c、标量b,将其全部拉直,得到一个向量θ,直接用 θ 来统设所有的参数,所以损失函数就变成 L(θ)
-
随机选择一个初始向量θ,计算其中每一个未知的参数θ1~θn对 L 的微分,得到向量 g
g = ∇ L ( θ 0 ) g = ∇L(θ_0) g=∇L(θ0)g = [ ∂ L ∂ θ 1 ∣ θ = θ 0 ∂ L ∂ θ 2 ∣ θ = θ 0 . . . ] g=\begin{bmatrix}\frac{∂L}{∂θ_1}|θ=θ_0 \\ \frac{∂L}{∂θ_2}|θ=θ_0\\ ...\\ \end{bmatrix} g= ∂θ1∂L∣θ=θ0∂θ2∂L∣θ=θ0...
-
再按梯度下降算法更新
θ 1 ← θ 0 − η g θ_1 ← θ_0 − ηg θ1←θ0−ηg
-
-
实现上有个细节:会把 N 笔数据随机分成一个一个的批量(batch),每次会先选一个批量,用该批量来算 L1,根据 L1 来算梯度,再用梯度来更新参数,接下来再选下一个批量算出 L2,根据 L2 算出梯度,再更新参数,依此类推
- 把所有的批量都看过一次,称为一个回合(epoch)
- 每次更新一次参数叫做一次更新
模型变形
Hard Sigmoid 除了可以换成 Soft Sigmoid,还可以看作是两个修正线性单元(Rectified Linear Unit,ReLU)的加总
修正线性单元,简称ReLU(Rectified Linear Unit),是一种常用的人工神经网络中的激活函数。ReLU函数的形式为: f(x) = max(0,x)。它在x大于零的时候激活,输出x;在x小于等于零的时候不激活,输出零。ReLU函数的优点是计算简单、神经元数量少、训练速度快、避免梯度消失的问题等。它已成为现代神经网络中最为普遍的激活函数之一,用于隐藏层中。
-
对应公式为
c ∗ m a x ( 0 , b + w x 1 ) c ∗ max(0, b + wx_1) c∗max(0,b+wx1)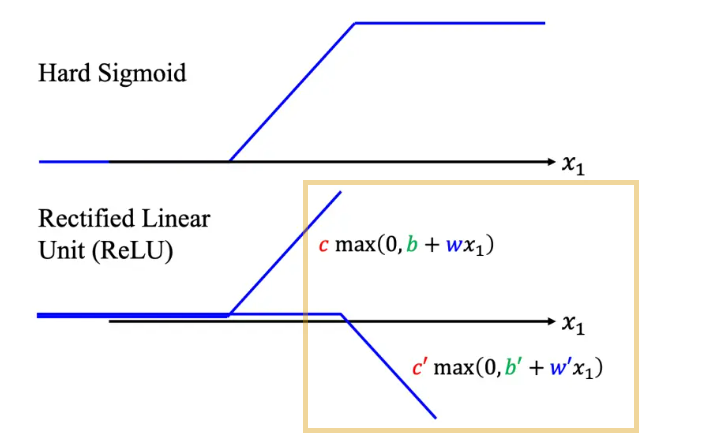
-
看 0 跟 b + wx1 谁比较大,比较大的会被当做输出
-
2 个 ReLU 才能够合成一个 Hard Sigmoid
-
在机器学习里面,Sigmoid 或 ReLU 称为激活函数(activation function)
激活函数是神经网络中的一种函数,用于对输入信号进行非线性变换,增加网络的表达能力。激活函数通常被应用于神经元的输出,将其转换为非线性的形式,以便更好地处理复杂的输入数据。常见的激活函数包括sigmoid函数、ReLU函数、tanh函数等。激活函数的选择对神经网络的性能和训练速度有很大的影响。
-
在案例训练中,线性模型考虑56天,而连续使用 10 个 ReLU作为模型,跟用线性模型的结果是差不多的,连续使用 100 个 ReLU 作为模型,结果就有显著差别
-
-
接下来可以继续改模型
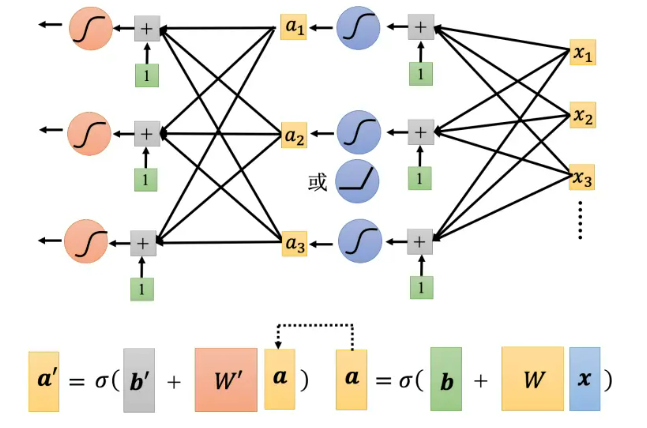
- 如图,将运算得到的数据再次进行运算,反复运算能显著降低损失
- 注意:w, b 和 w′, b′ 不是同一个参数,是增加了更多的未知的参数
- 反复运算的次数是超参数
- 案例中,机器只知道看前 56 天的值,来预测下一天会发生什么事,所以它不会考虑节日等因素
-
深度学习
- Sigmoid 或 ReLU 称为神经元(neuron),很多的神经元称为神经网络
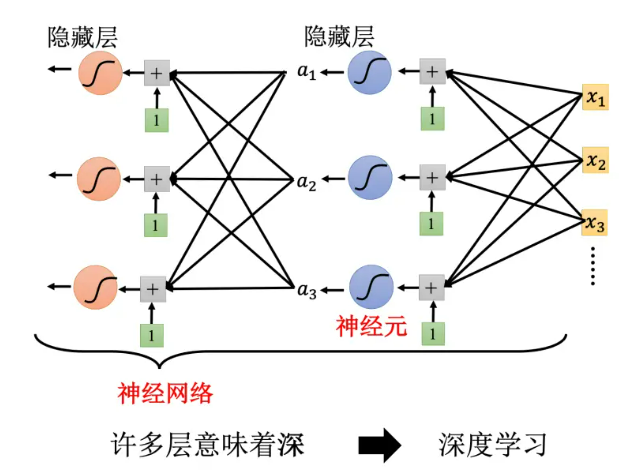
隐藏层是人工神经网络中的一层,位于输入层和输出层之间,由一定数量的神经元组成。隐藏层中的每个神经元都利用输入层的输入数据进行计算,并传递输出到输出层。隐藏层的存在可以提高神经网络的学习和预测能力,使其能够识别更加复杂的模式和规律。隐藏层的数量和每层神经元的数量是决定神经网络性能和复杂度的关键因素之一。
过拟合是指一个机器学习模型在训练数据上表现得很好,但在测试数据上表现不佳的现象。过拟合可能是因为模型过于复杂或者数据量太小。如果一个模型过于复杂,它可能会在训练数据中学习到噪声,而这些噪声可能并不普遍存在于测试数据中,这样就会导致过拟合。解决过拟合的方法包括增加训练数据、减小模型复杂度、使用正则化方法等。
BP(Back Propagation)是一种训练人工神经网络的常见方法,它是“误差反向传播”的简称,与最优化方法(如梯度下降法)相结合使用,可以帮助神经网络更好地学习和更新权重,从而提高网络的准确性。
机器学习框架
训练的3个步骤
- 先写出一个有未知数 θ 的函数,θ 代表一个模型里面所有的未知参数。函数fθ(x),输入的特征为 x
- 定义损失,损失是一个函数,其输入就是一组参数,去判断这一组参数的好坏
- 解一个优化的问题,找一个 θ,该 θ 可以让损失的值越小越好
















 179
179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











