







版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/baimafujinji/article/details/78384792
现在人工智能,特别是深度学习可谓风光无限,加之各种框架神器层出不穷也令深度学习不再是什么空中楼阁。由于工具化的趋势越来越明显,现在要自行搭建一个深度神经网络已经变得越来越容易。你可能听说过的框架有TensorFlow、Theano、Torch、Caffe、MXNet等等,今天我们就要来介绍构建神经网络最为容易的一个框架——Keras。之所以说Keras是当前构建神经网络最为容易的框架,就是因为相比于Theano和TensorFlow,你会发现使用Keras,你所需要自行编写的代码是最少的。真是不得不令人感叹:没有对比,就没有伤害。
总的来说,使用Keras构建神经网络的基本工作流程主要可以分为4个部分。而且这个用法和思路我个人感觉,很像是在使用Scikit-learn中的机器学习方法
Model definition → Model compilation → Training → Evaluation and Prediction
下面我们就通过一个非常简单的例子来一步一步地演示如果在Keras中构建一个简单的用于回归的神经网络。这个例子基本上跟文章【TensorFlow简明入门宝典 】中最后给出的那个求解线性回归的例子要做的事情是一致的。
首先,我们人为地造一组由 y = 0.5x + 2 加上一些噪声而生成的数据,数据量一共有200个,其中前160作为train set,后40作为test set。
import numpy as np
import matplotlib.pyplot as plt
X = np.linspace(-2, 6, 200)
np.random.shuffle(X)
Y = 0.5 * X + 2 + 0.15 * np.random.randn(200,)
# plot data
plt.scatter(X, Y)
plt.show()
X_train, Y_train = X[:160], Y[:160] # train first 160 data points
X_test, Y_test = X[160:], Y[160:] # test remaining 40 data points
可以用matplotlib中提供的方法来绘制一下数据的分布情况:
接下来,我们要执行构建模型的第一步,即Model Definition。这一步的作用就是定义NN中的层次结构。为此要引入两个重要的类,Sequential和Dense。
from keras.models import Sequential
from keras.layers import Dense
其中Sequential是Keras中构建NN最常用的一种Model(也是最简单的一种),一个Sequential的Model 就是 a linear stack of layers,也就是说,你只要按顺序(使用add()方法)一层一层地顺序地添加神经网络层就可以了。而Dense表示全连接层,此时它需要接收两个参数,即输入的节点数及输出的节点数,特别地,在一层一层地构建NN时,Keras还可以根据上一层的输出来推断下一次的输入,所以有些全连接层参数可以省略。
在这个简单的例子中,我们的全连接层只有一层,而且输入的节点数和输出的节点数都为1,所以有:
model = Sequential()
model.add(Dense(output_dim = 1, input_dim = 1))
接下来执行构建模型的第一步,即Model compilation。这一步是要指定模型中的loss function(在这例子中使用的是最小二乘误差‘mse’),优化器以及metrics等内容。优化器你可以使用系统提供的默认优化器,例如你可以像下面这样用'sgd'表示随机梯度下降。
model.compile(loss='mse', optimizer='sgd')
你可以可以像下面这样自定义优化器中的参数:
from keras.optimizers import SGD
model.compile(loss='mse', optimizer=SGD(lr=0.01, momentum=0.9, nesterov=True))
然后来执行Training的部分。在这一步你可以有两个选择。第一种直接使用fit,这个简直和Scikit-learn中的感觉像极了!你只要在fit方法的参数列表中指定训练数据(特征向量和label)、训练的次数和用来做梯度下降的batch size就可以了。
model.fit(x_train, y_train, epochs=100, batch_size=64)
另外一个选择是你也可以采用下面的语法来feed batches to your model manually:
model.train_on_batch(x_batch, y_batch)
例如在本例中你可以把训练部分写成下面这种形式,其中每20步,我们会输出一次cost。
print('Training -----------')
for step in range(100):
cost = model.train_on_batch(X_train, Y_train)
if step % 20 == 0:
print('train cost: ', cost)
我的程序输出结果如下(注意由于存在各种随机性,每次的输出未必完全一致):
Training -----------
train cost: 0.0290748
train cost: 0.0276375
train cost: 0.026696
train cost: 0.0260792
train cost: 0.0256752
最后,终于可以进入Evaluation and Prediction的部分了。对于之前预留的测试集来说,你可以使用:
cost = model.evaluate(X_test, Y_test, batch_size=40)
具体来说针对我们现在这个例子则有:
print('\nTesting ------------')
loss_and_metrics = model.evaluate(X_test, Y_test, batch_size=40)
print('test cost:', cost)
W, b = model.layers[0].get_weights()
print('Weights=', W, '\nbiases=', b)
我的程序输出结果如下:
Testing ------------
40/40 [==============================] - 0s
test cost: 0.0254213
Weights= [[ 0.50829154]]
biases= [ 1.9707619]
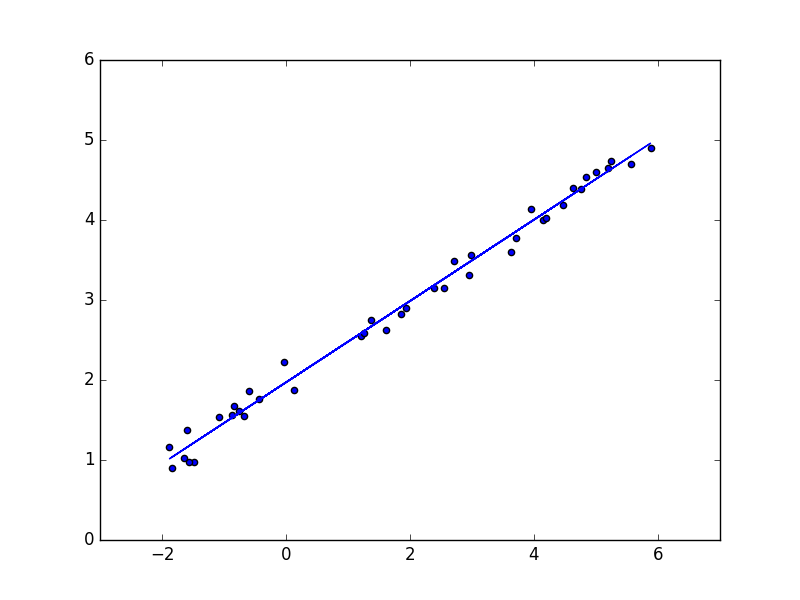
对一些新的数据来进行预测,那么你可以使用predict,而且它的使用也与Scikit-learn中的用法及其相似,最终我们预测test set中每个的点,并绘制预测的模型。
Y_pred = model.predict(X_test)
plt.scatter(X_test, Y_test)
plt.plot(X_test, Y_pred)
plt.show()
输出之图形如下:
最后,我个人认为【1】是入门Keras的一个非常好的Talk。另外,本文的jupyter notebook文件,你可以从下面的链接【3】中获取到。
参考文献:
【1】https://www.youtube.com/watch?v=OUMDUq5OJLg (需要自备梯子)
【2】https://keras.io/#getting-started-30-seconds-to-keras
【3】https://pan.baidu.com/s/1jI8CgHw
(本文完)
---------------------
作者:白马负金羁
来源:CSDN
原文:https://blog.csdn.net/baimafujinji/article/details/78384792
版权声明:本文为博主原创文章,转载请附上博文链接!














 1919
1919











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









