







我个人认为Python中的re部分比较难,我也找了一些书籍来看,主要是Python基础教程,来分享一下今天下午的学习成果。
- 什么是正则表达式
正则表达式是可以匹配文本片段的模式。最简单的正则表达式就是单个字符,可以匹配其自身的。简单的说就是在文本寻找你要的东西。 简单的使用方法
通配符:点号(.)一个点号可以匹配任何一个字符(空格,+-*%)
转义符:\, 在re模式下一个就可以,不然的话要用两个
选择符:|,可以在匹配的时候进行选择例如‘Python|perl’就可匹配字符‘python‘和’perl‘
子模式:(),可以使字符的一部分,’p(ython|erl)’
重复子模式:()?,问号前面的括号,匹配时是可以里面的内容可以没有的,
3.具体例子
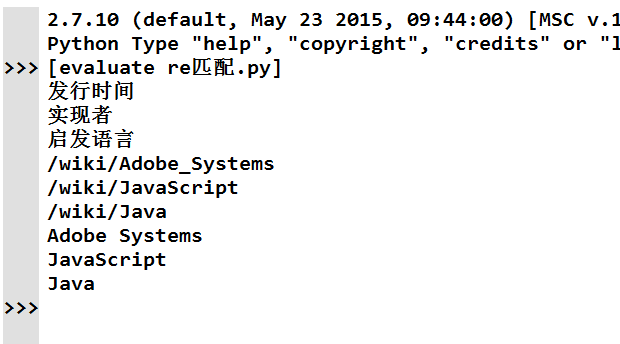
line中的是主要的文本内容,
re1,re2,re3是匹配的不同的内容,分别实现的功能是查找中文,查找链接,查找标题
# coding:gb2312
import re
line='''
<table class="infobox vevent" cellspacing="3" style="border-spacing:3px;width:22em;text-align:left;font-size:small;line-height:1.5em;">
<caption class="summary"><b>ActionScript</b></caption>
<tr>
<th scope="row" style="text-align:left;white-space:nowrap;;;">发行时间</th>
<td style=";;">1998年</td>
</tr>
<tr>
<th scope="row" style="text-align:left;white-space:nowrap;;;">实现者</th>
<td class="organiser" style=";;"><a href="/wiki/Adobe_Systems" title="Adobe Systems">Adobe Systems</a></td>
</tr>
<tr>
<tr>
<th scope="row" style="text-align:left;white-space:nowrap;;;">启发语言</th>
<td style=";;"><a href="/wiki/JavaScript" title="JavaScript">JavaScript</a>、<a href="/wiki/Java" title="Java">Java</a></td>
</tr>
</table>
'''
re1=r'<th scope=.*?>(.*?)</th>'
re2=r'(?<=href=\").+?(?=\")'
re3=r'(?<=title=\").+?(?=\")'
for z in re1,re2,re3:
rec_th=re.findall(z,line ,re.M|re.I)
if rec_th!='':
for x in rec_th:
print x
运行的结果就是
4.还有一些很好的例子
可以稍微借鉴一下,
import re
href = '<p><a href="www.csdn.cn" title="csdn">CSDN</a></p>'
link = re.findall(r"(?<=href=\").+?(?=\")", href)
print link # coding:gb2312
lines = '''
<table>
<tr>
<td>序列号</td><td>DEIN3-39CD3-2093J3</td>
<td>日期</td><td>2013年1月22日</td>
<td>售价</td><td>392.70 元</td>
<td>说明</td><td>仅限5用户使用</td>
</tr>
</table>
'''
import re
m = re.findall(r'<td>(.*?)</td>', lines, re.I|re.M)
if m:
for x in m:
print x













 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









