







最近看了算法导论的KMP算法的介绍,笔者实现了该算法,并大致懂得了该算法的思想。现大致总结如下:
字符串匹配:即是在一个目标串中寻找某一个模式出现的位置。
例如:在目标串 S = “ababababca” 中寻找模式串P = “ab”。返回“ab”的位移为0,2,4 , 6。
下面以 S = "abacabababababcabababababca" , P = “ababababca”。 len(S) = n , len(P) = m
传统的方法,依次比较P与S中的每一个字符,如果出现不一样的,则将P 相对于 S 向后移位一次,开始下一轮匹配,总共的匹配的次数为( (len(S) - len(P) + 1)次。
如下图所示:

每一轮匹配时,出现不匹配的情况时,将模式串P向后移一位,进入下一轮匹配,因此:时间复杂度为O((n-m+1)m).
KMP是Knuth Morris 和 Pratt 设计的线性时间字符串匹配算法。
首先定义一个next数组,该数组是针对于模式串本身的特点来定义的。
元素 next[ i ] 的定义是: 如果在字符 P[ i ] 处,模式串与目标串的值不相同,那么下一次开始匹配的位置是模式串的 next[ i ] 位置开始。
距离说明:
对于模式串 P = “ ababababca”串而言,该模式串P的next数组为:

举例来说,P[ 3 ] = 'b', next[ 3 ] = 1,也就是说如果P在于目标串S比较时,如果P[ 3 ] 与目标串不匹配,那么下一次匹配直接从P[ next [ 3] ] = P[ 1 ]开始比较。
如下图:

注意:每一次匹配不成功时, 模式串P相对于原始串的移动的位置。
因此,整个KMP算法的核心便是在求模式串的next数组了。
PS:如果模式串中所有的字符都不一样,那显然使用KMP算法便会退化为传统的算法。
整个程序的代码如下:
注:与算法导论上面有出入,字符串的起始位置为0。
<span style="font-size:18px;">#include<iostream>
#include<vector>
#include<string>
using namespace std;
vector<int> ComputeNext(string p)
{
vector<int> next(p.length(),0);
if(p.length() == 0 ) return next;
next[0] = -1;//index从0开始
int k = -1;
for(int q = 1 ; q < p.length() ; ++q )
{
while(k >= 0 && p[k+1] != p[q])
k = next[k];
if( p[k+1] == p[q] ) k++;
next[q] = k;
}
return next;
}
void KMP(string s, string p )
{
cout << "KMP..." << endl;
vector<int> next = ComputeNext(p);
int lenS = s.length();
int lenP = p.length();
int q = -1; //已经match的字符的个数
for(int i = 0 ; i < lenS ; ++i)
{
//-1 means no backward position
while(q >= 0 && s[i] != p[q+1])
q = next[q];
if (p[q+1] == s[i])
q++;
if ( q == lenP-1 )
{
cout << p << " find in "<< s << " " << (i-lenP+1) << " pos!" << endl;
q = next[q];
//return;
}
}
//cout << "do not find!!!" << endl;
return;
}
int main()
{
string p = "abababab";
string s = "abacabababababcabababababca";
vector<int> next = ComputeNext(p);
for(vector<int>::size_type i = 0 ; i != next.size() ; ++i)
{
cout << i << " " << next[i] << endl;
}
KMP(s,p);
return 0;
}</span>
上述程序的运行结果为:
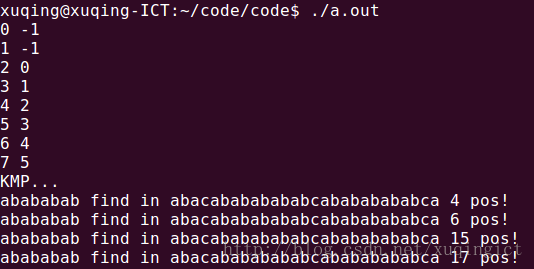
总结:KMP本身很简单,关键是求解next数组,必须知道next数组是由于模式串本身的特征来决定的,跟目标串没有任何关系。















 3838
3838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









