






问题导读:
1、本人大数据工作内容有哪些?
2、高级/资深大数据架构涉及哪些内容?
3、大数据学习路线是什么?
4、有哪些可以建议给到在学习路上的小伙伴?
网上看到一些想进名企的小伙伴,对于名企的工作日常到底是怎么样的,比较好奇和关心。所以特地邀请了我们VIP成员,【目前已经认证“腾讯大数据架构师”】,写了这篇“在大厂的数据工程师工作日常工作分享”。如果大家有问题,也可以关注他的博客。后面我们也邀请了京东的大佬,原先是我们VIP成员,大数据工程师,后来成为京东主管。给我们分享相关经历。
这是我们VIP大佬的的博客“不埋雷的探长”
https://tanzhang.blog.csdn.net/?t=1
原文链接:
https://blog.csdn.net/weixin_32265569/article/details/122030896
如果关心大佬怎么进入大厂的,下面是大佬总结的相关经验
我是二本,凭什么可以进入大厂
https://tanzhang.blog.csdn.net/article/details/121891198
下面是在大厂的数据工程师工作日常工作分享:
首先说明一下数据类的岗位在大厂是会再细分,具体有数据工程、数据分析、数据科学这三大类。本人是在数据工程方面多一些。大数据开发在我们这边叫数据工程,其工作内容本质上没有什么区别,只是叫法不一样而已。
数据工程的定义:基于对业务和数据的理解,通过各种技术和管理手段,不断提升数据接入、建模效率以及数据质量(一致性、准确性、合规性、重复性、及时性、完备性),满足各种数据消费和应用场景的数据分析和挖掘需求。
一、本人大数据工作内容?
早上,我一般会选择坐公司的班车(偶尔睡晚了也会坐地铁)。差不多8点40分左右到公司会先吃早餐。
休息片刻大概9点去健身房锻炼一下身体。主要是想通过适当的运动,让身体更加放松、健康,同时还可以甩甩脂肪控制体重,最近这段时间通过运动由67KG减至61KG了。这里也分享一下我个人的感受:运动期间听听歌、或者看看新闻,出出汗,整个身心更加舒服~ 运动完后我一般都会安静下来休息一下,再冲个澡儿。
9:50左右到办公位,开始一天的工作;10点左右会有一个小组晨会,汇报一下最近几天的工作情况、遇到的问题以及接下来要做的事情,这个晨会我个人是觉得挺好的,小组团队成员也能够彼此了解到大家的工作内容,同时也能方便Leader传答一下最近的项目规划。晨会后就是开启一天的工作啦,我本人有个习惯就是好好打杯温水慢慢喝,边想一天需要干的事情,怎样工作效率高一些~
12点左右开始去吃午饭,12:00~14:00是休息时候(含吃饭);下午也是类似的工作节奏;到了下午6点开始晚饭;晚上8点左右下班,有时我也会6点下班;一天下来还是挺累的。好在是双休,加上自己的一些工作节奏调整,整体下来工作节奏还可以把控得住~
每天例行的工作清单大致如下:
检查一下核心的报表、负责的核心链路是否正常;
打开需求文档,看看有没有还没有完成好的需求,跟需求方了解详细诉求;
期间会不定期地接收新的业务需求、业务反馈、Leader需求【这个频率不会很高】
每天重点工作:
本人大部分时间及精力是花在理解需求,拆解功能,考虑数据架构、模型,这个时间占整个项目周期的70%,剩下的时间是在开发、测试;我本人实时任务、离线数据仓库都做;离线的项目则可在公司的数据平台 (这个很依赖于公司的基建能力) 上直接写SQL脚本,写好后会提交到任务调度平台进行任务依赖配置即可;实时需求会复杂一些,涉及的技术栈比较多,我们一般会采用Flink + Kafka + Apache Druid + Bi可视化;
除了上述外,本人还参与数据治理、数据驱动、数据报表设计,为部门团队成员提供全面的数据服务。
目前大厂在大数据领域主要分为离线、实时两大类:
离线开发:主要是存储Hadoop作为数据存储,hive管理库表/字段信息与Hadoop存储进行关联,使用MapReduce、Spark、Presto作为分析计算引擎
实时开发:前几年还有在用SparkStreaming,现在基本全部是flink了
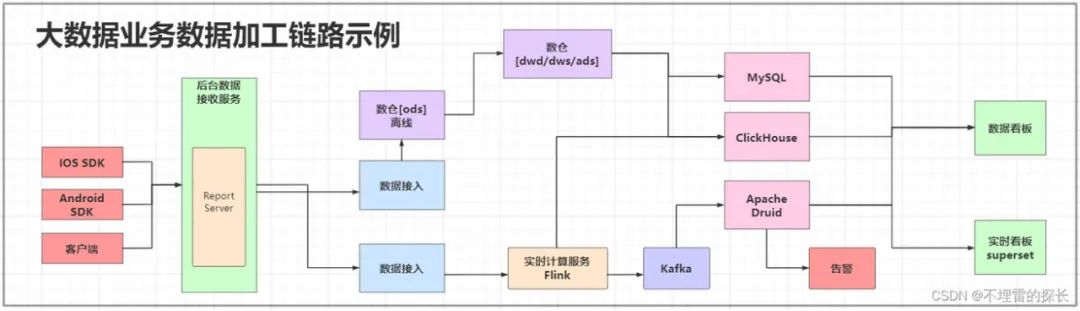
下面是我平时画的架构图,也供大家一起交流分享
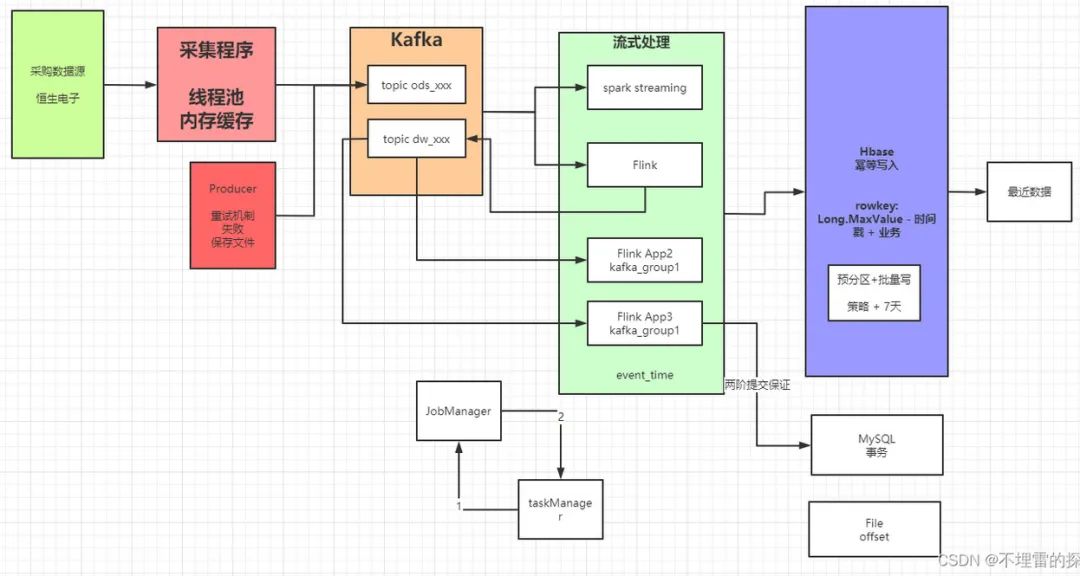
二、高级/资深大数据架构涉及哪些内容?
在大厂中有很多实力强劲的大佬,他们对大数据有更全面、更体系、更深入的认识,往往在团队中起到顶梁柱的作用;这些大佬,不仅仅是业务上的负责人更多的是引领团队朝正规化的方向发展。现在来看看这种类型的大佬应该具备怎样的技能~
掌握并在企业实战实时计算平台、离线数仓平台、离线和实时数据质量QDC建设、统一埋点与统一指标建设、数据字典与数据血缘管理关系、调度平台、数据湖与数仓、数据应用服务及数据可视化 等,探索大数据云原生化部署建设
实时计算类:Flink, Spark Streaming, Apache Beam, Storm, Kafka Streaming, Streaming SQL等 平台建设, 深入掌握flink可完成定制改造源码做平台化建设、实时应用类深度开发,曾基于业务需要修 改flink cep模块让其支持动态CEP规则
OLAP分析引擎类:Apache Kylin、Apache Druid、Pinot、ClickHouse等,熟悉基于Apache Druid进行OLAP准实时分析技术,能完成Dimension和Metric的构建;使用clickhouse构建明细 +汇总的OLAP查询引擎,百亿数据秒级返回,支持自由定义维度和度量
实时数据湖:apache iceberg,apache hudi等,使用iceberg构建增量实时数据湖,解决企业PB 级海量数据存储和高速计算问题
实时数仓、离线数仓:深刻理解离线数仓ODW,DWD,DWS,DM,APP,DIM等分层建设思路,掌握基 于one data,one service,one model的数据中台建设方法论,并用于企业实战,曾经维护每日增量 100TB离线任务5000+的离线数仓;熟悉基于Kappa架构批流一体实时数仓设计,并能够集合数据 资产完成离线和实时元数据统一化管理,从底层计算引擎设计实时和离线的统一平台,曾经维护 1000+任务的实时计算平台
实时检索与存储系统:HBase、ElasticSearch、Redis、Phoenix等,掌握Hbase架构与使用,完成基于Hbase的二级索引建立,提高查询效率,能与ElasticSearch整合,完成分布式搜索引擎搭建
ELK日志套件:Flume、FileBeat、Logstash、ElasticSearch、Kibana
MQ消息队列:Apache Kafka、Apache Pulsar、RocketMQ、Tencent Tube
数据应用服务:数据自助报表建设(supserset、davinci),数据服务open api建设,数据脱敏及细 粒度权限控制
数据迁移工具,掌握Sqoop、阿里Datax、FlinkX,完成数据以分布式方式在不同存储介质间迁移, binlog+canal数据库数据变更流抓取和处理转换
机器学习类:可根据Spark和Alink提供的机器学习套件做模型训练、模型server服务
大数据运维类:可运维千台规模集群,集群容量规划、扩容及集群性能和资源利用率,可以做集群的 运维工作包括但不限于hdfs/Hbase/Hive/kudu/TIDB/Yarn/Spark/flink/hudi等,确保高可用性运行;熟悉容器和服务部署维护,自动化构建
数据驱动业务:掌握体系化“第一关键指标法”、海盗指标模型等数据分析方法,结合业务运用数据 SDAF闭环提升业务营收,曾经在广告业务领域通过数据驱动每年提升收入数亿人民币;数据结合策略指导智能营销,建设精细化DMP数据管理平台,构建商业标签体系。
三、大数据学习路线
大数据涉及的技术栈比较多,有数据存储、计算、传输中转等等方方面面;所以在学习大数据技术栈前一定得先搞明白某个技术栈主要是干什么用的,它能解决什么问题,学习的过程中带着问题去学习,同时也要侧重学习的前后顺序。
系统的学习大数据相关的课程,可按照如下顺序学习
(必学)需要先掌握 Java SE 阶段,Linux 基础命令(建议安装 CentOS),MySQL数据库
(必学)学习Hadoop生态(zk、hadoop、hive、hbase、kafka、spark、flink等)
(选学)机器学习、人工智能

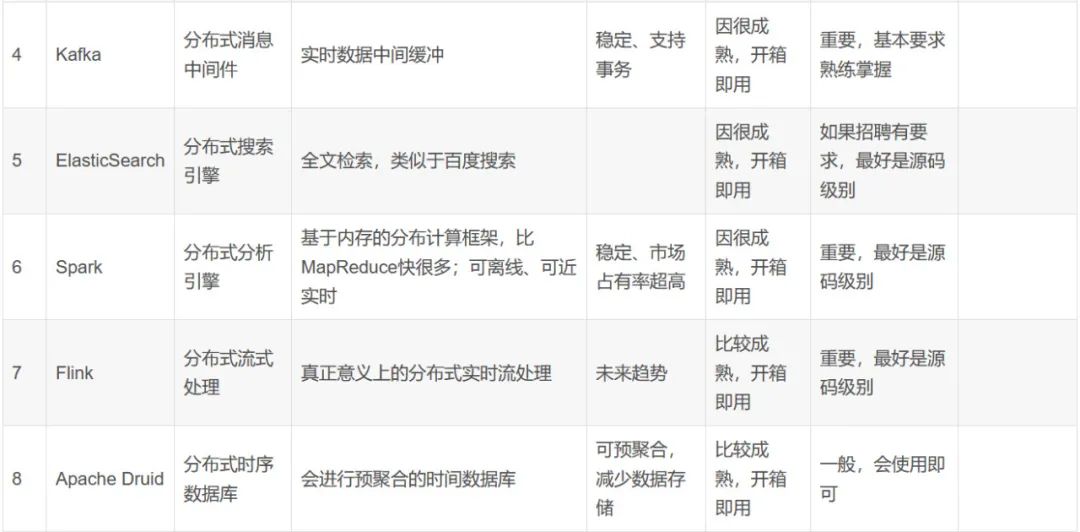

具体可参照如下顺序进行学习(涵盖ETL、数仓、开发等岗位)
hadoop -> zookeeper -> hive -> flume && sqoop -> azkaban && oozie -> 数仓建模理论+实践 -> hbase -> redis -> kafka -> elk -> scala -> spark -> kylin -> flink -> 实时数仓项目
以上为大数据学习必备知识!!!
学完以上技能后,有时间还需要学习比较流行的 OLAP 查询引擎
ClickHouse 、 Impala 、 Presto、Druid 、 Kudu 、 Doris
如果还有时间,可以学习数据治理、数据驱动相关的内容,如元数据管理,数据湖等
Atlas 、 Hudi、 “第一关键指标法”、海盗指标模型等数据分析方法
附:大数据类工作分工

四、送给在学习路上的小伙伴一些建议
要多思考 ,这个技术点为什么这样实现,有什么好处,多思考会让大脑越来越灵活
要多交流 ,跟身边的同学或高手多交流学习,遇到一些没有理解的知识通过相互交流学习也是一种很好的方式
要多做笔记,我个人就是喜欢多做笔记;因为大数据知识体系复杂且繁多,通过在学习过程中将核心知识点记录起来
要多画图,多画架构图、原理图;比如:Spark架构图、Flink架构图等等;这样学习起来也会更容易理解一些
要多做项目,最终通过真实项目将知识体系串连起来形成一张完整的技术栈网
要多读书,建议可以读读一些大数据技术栈类的书籍,这个技术巩固会更扎实















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









