







激活函数的作用:
1、主要作用是改变之前数据的线性关系,使网络更加强大,增加网络的能力,使它可以学习复杂的事物,复杂的数据,以及表示输入输出之间非线性的复杂的任意函数映射;
2、另一个重要的作用是执行数据的归一化,将输入数据映射到某个范围内,再往下传递,这样做的好处是可以限制数据的扩张,防止数据过大导致的溢出风险。
一、sigmoid函数
公式:![]()
图像:
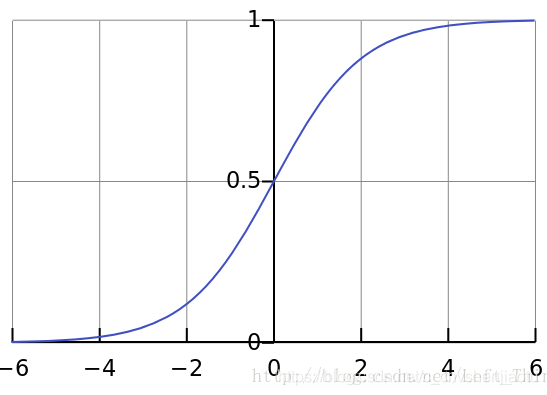
特点:1、从图中可以看到,当输入大于5或小于-5时,函数输出结果趋于稳定,区分度低,通过几层神经网络传导便容易产生梯度饱和问题,也可以叫梯度弥散。
2、sigmod函数要进行指数运算和除法运算,这个对于计算机来说是比较慢的。
3、函数输出不是以0为中心的,这样会使权重更新效率降低。即当我们的输入如果全是正数时,我们在反向传播时,下降的梯度也是正数;当我们输入全是负数时,我们反向传播时,下降的梯度也时负数。因此会导致梯度更新权重是按照z字型下降的。但是这个问题我们可以一次训练一个batch的数据,这样就可以避免输入全是正数或者负数的现象。
应用场景:在特征相差比较复杂或是相差不是特别大时,使用sigmoid效果比较好。用于隐层神经元输出。
二、 tanh函数
公式:![]()
图形:
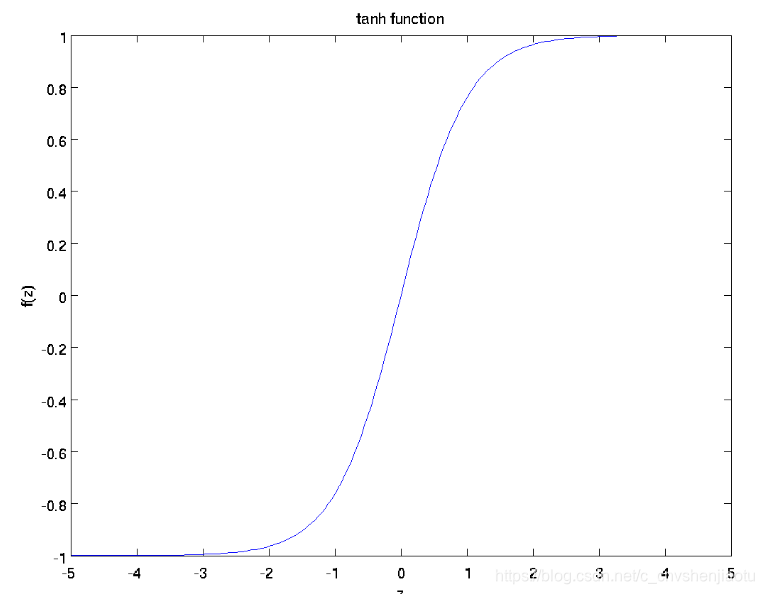
特点:tanh函数相比于sigmoid函数来说,它是关于原点对称的了。但是还是会存在着计算复杂,以及梯度消失的问题。
应用场景:tanh函数在特征相差明显时的效果会很好,在循环过程中会不断扩大特征效果。
三、ReLu函数
公式:![]()
图形:
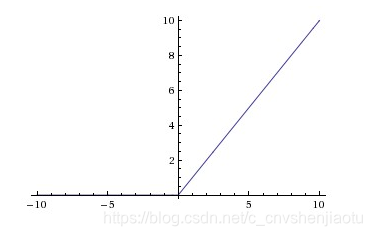
特点:
1、单侧抑制:在输入大于0时,此时激活函数的导数恒等于1,因此不会出现饱和的现象。但是在输入小于0时,此时为硬饱和。
2、计算便捷:ReLu是线性的,它只用将神经元的输出与某个阈值做比较,如果大于阈值,则输出神经元的输出,否则输出为0。因此无论是在正向传播还是反向传播的计算中都十分便捷。
3、ReLu在训练的过程中会造成神经元的死亡。为什么会造成这种情况呢?举个例子:当在反向传播时,如果此时流进网络的梯度很大,如果权重系数被更新成很大的负数后,此时很多输入经过该神经元输出都会是0。此时就落入了硬饱和区域了。而这个神经元的梯度将一直都是0。要解决这个问题就是要在设置学习率的时候,尽量不要设置太大的学习率,这样可以有效的避免神经元的失活。
应用场景:用于隐层神经元输出。建议先试用ReLu或Leaky-ReLU,不行再试sigmoid或tanh。
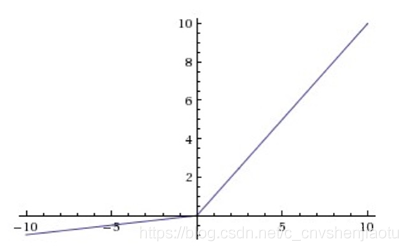
Leaky-ReLU:
Maxout:
另:
参考:
https://blog.csdn.net/jacke121/article/details/80805488
https://blog.csdn.net/left_think/article/details/77664085
https://blog.csdn.net/leo_xu06/article/details/53708647














 295
295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









